环境:Centos 6.9,Hadoop 2.7.1,JDK 1.8.0_161,Maven 3.3.9
前言:
1、配置一台master服务器,两台或多台slave服务器。
2、master可以无密码ssh登陆slave
3、解压安装Hadoop,配置hadoop的core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml文件,配置好之后启动hadoope服务,用jps命令查看状态;
4、运行hadoop自带的wordcount程序做一个Hello World实例
开始配置
第一步 配置hosts
获得它们的IP地址,并设置主机名,(根据实际IP地址和主机名)修改/etc/hosts文件内容为:
192.168.110.66 master.hadoop
192.168.110.67 slave1.hadoop
192.168.110.68 slave2.hadoop

重启后。host生效。
第二步 ssh免密登陆
全程用的都是root用户,没有另外创建用户。每台服务器都生成公钥,再合并到authorized_keys。
1) CentOS默认没有启动ssh无密登录,去掉/etc/ssh/sshd_config其中2行的注释,每台服务器都要设置。
查找
#RSAAuthentication yes
#PubkeyAuthentication yes
删除前面的井号注释。
2) 输入命令,ssh-keygen -t rsa,生成key,都不输入密码,一直回车,/root就会生成.ssh文件夹,每台服务器都要设置
3) 合并公钥到authorized_keys文件,在master服务器,进入/root/.ssh目录,通过SSH命令合并,(~/.ssh/id_rsa.pub 是省略的写法,要根据实际路径来确定)
cat id_rsa.pub>> authorized_keys ssh root@192.168.110.67 cat ~/.ssh/id_rsa.pub >> authorized_keys ssh root@192.168.110.68 cat ~/.ssh/id_rsa.pub >> authorized_keys
如果出现 ssh command not found
就yum装一个ssh


4) 把master服务器的authorized_keys、known_hosts复制到slave服务器的/root/.ssh目录
scp -r /root/.ssh/authorized_keys root@192.168.110.67:/root/.ssh/ scp -r /root/.ssh/known_hosts root@192.168.110.67:/root/.ssh/ scp -r /root/.ssh/authorized_keys root@192.168.110.68:/root/.ssh/ scp -r /root/.ssh/known_hosts root@192.168.110.68:/root/.ssh/
5) 完成后,ssh root@192.168.110.67、ssh root@192.168.110.68或者(ssh root@slave1.hadoop、ssh root@slave2.hadoop ) 就不需要输入密码直接登录到其他节点上。

第三步安装JDK

tar包安装方式
1) 在/home目录下创建java目录,然后使用rz命令,上传“jdk-7u79-linux-x64.gz”到/home/java目录下,
2) 解压,输入命令,tar -zxvf jdk-7u79-linux-x64.gz
3) 编辑 /etc/profile,在其末尾添加以下内容:
export JAVA_HOME=/home/java/jdk1.7.0_79 export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin
4) 使配置生效,输入命令,source /etc/profile
5) 输入命令,java -version,完成
第四步安装Hadoop
将主从节点上传好的hadoop解压。,输入命令,tar -xzvf hadoop-2.7.3.tar.gz
在/home/hadoop目录下创建数据存放的文件夹,tmp、dfs、dfs/data、dfs/name(hdfs-site.xml文件中会用到)
修改配置文件
1./root/hadoop/etc/hadoop目录下的core-site.xml
1 <configuration> 2 <property> 3 <name>fs.default.name</name> 4 <value>hdfs://master.hadoop:9000</value> 5 </property> 6 <property> 7 <name>hadoop.tmp.dir</name> 8 <value>/root/hadoop/tmp</value> 9 </property> 10 <property> 11 <name>io.file.buffer.size</name> 12 <value>131702</value> 13 </property> 14 </configuration>
2.配置/root/hadoop/etc/hadoop目录下的hdfs-site.xml
1 <configuration> 2 <property> 3 <name>dfs.namenode.name.dir</name> 4 <value>file:///root/hadoop/dfs/name</value> 5 </property> 6 <property> 7 <name>dfs.datanode.data.dir</name> 8 <value>file:///root/hadoop/dfs/data</value> 9 </property> 10 <property> 11 <name>dfs.replication</name> 12 <value>1</value> 13 </property> 14 <property> 15 <name>dfs.namenode.secondary.http-address</name> 16 <value>master.hadoop:50090</value> 17 </property> 18 <property> 19 <name>dfs.webhdfs.enabled</name> 20 <value>true</value> 21 </property> 22 </configuration>
3.配置/root/hadoop/etc/hadoop目录下的mapred-site.xml
1 <configuration> 2 <property> 3 <name>mapreduce.framework.name</name> 4 <value>yarn</value> 5 <final>true</final> 6 </property> 7 <property> 8 <name>mapreduce.jobtracker.http.address</name> 9 <value>master.hadoop:50030</value> 10 </property> 11 <property> 12 <name>mapreduce.jobhistory.address</name> 13 <value>master.hadoop:10020</value> 14 </property> 15 <property> 16 <name>mapreduce.jobhistory.webapp.address</name> 17 <value>master.hadoop:19888</value> 18 </property> 19 <property> 20 <name>mapred.job.tracker</name> 21 <value>http://master.hadoop:9001</value> 22 </property> 23 </configuration>
4.配置/home/hadoop/hadoop-2.7.0/etc/hadoop目录下的yarn-site.xml
1 <configuration> 2 <property> 3 <name>yarn.nodemanager.aux-services</name> 4 <value>mapreduce_shuffle</value> 5 </property> 6 <property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name> 7 <value>org.apache.hadoop.mapred.ShuffleHandler</value> 8 </property> 9 <property> 10 <name>yarn.resourcemanager.address</name> 11 <value>master.hadoop:8032</value> 12 </property> 13 <property> 14 <name>yarn.resourcemanager.scheduler.address</name> 15 <value>master.hadoop:8030</value> 16 </property> 17 <property> 18 <name>yarn.resourcemanager.resource-tracker.address</name> 19 <value>master.hadoop:8031</value> 20 </property> 21 <property> 22 <name>yarn.resourcemanager.admin.address</name> 23 <value>master.hadoop:8033</value> 24 </property> 25 <property> 26 <name>yarn.resourcemanager.webapp.address</name> 27 <value>master.hadoop:8088</value> 28 </property> 29 <property> 30 <name>yarn.resourcemanager.hostname</name> 31 <value>master.hadoop</value> 32 </property> 33 <property> 34 <name>yarn.nodemanager.resource.memory-mb</name> 35 <value>2048</value> 36 </property> 37 </configuration>
提示:yarn.nodemanager.resource.memory-mbr的值一定要注意,在最后的hello world程序运行时,会提示内存太小,(hadoop运行到mapreduce.job: Running job后停止运行 )我把它从1024改成了2048
最后执行wordcount遇到内存不足的问题,解决方案就是把yarn-site.xml文件中的yarn.nodemanager.resource.memory-mb的值改成2048
5.配置/home/hadoop/hadoop-2.7.3/etc/hadoop目录下hadoop-env.sh、yarn-env.sh的JAVA_HOME
取消注释,设置为export JAVA_HOME=你java的安装路径
通过yum安装的java 路径在 /etc/alternatives/java_sdk_1.8.0
slave1.hadoop
slave2.hadoop
6.配置/home/hadoop/hadoop-2.7.3/etc/hadoop目录下的slaves,删除默认的localhost,增加2个slave节点:
7.将master服务器上配置好的Hadoop复制到各个节点对应位置上,通过scp传送
scp -r /root/hadoop 192.168.110.67:/root/
scp -r /root/hadoop 192.168.110.68:/root/
第四步安装Hadoop
提示:在master服务器启动hadoop,各从节点会自动启动,进入/root/hadoop目录,hadoop的启动和停止都在master服务器上执行。
1) 初始化,在hadoop目录下输入命令,bin/hdfs namenode -format (注意这个 横杆不能是中文横杆,否则namenode会格式化失败,在日志里报java.io.IOException: NameNode is not formatted.)
2) 启动命令
sbin/start-dfs.sh
sbin/start-yarn.sh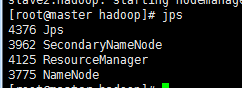
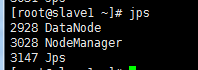
3) 停止命令,依次执行:sbin/stop-dfs.sh、sbin/stop-yarn.sh
至此hadoop已经搭建完成。
四、Hadoop入门之HelloWorld程序
摘要:初步接触Hadoop,必不可少的就是运行属于Hadoop的Helloworld程序——wordcount,统计文件中各单词的数目。安装好的Hadoop集群上已有相应的程序。我们来验证一下。
准备数据
在/root/hadoopdemo/下创建file文件夹,里面生成file1.txt,file2.txt,file3.txt,file4.txt四个文件
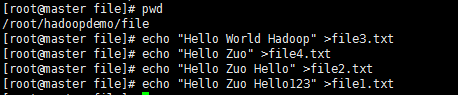
然后把数据put到HDFS里
[root@master hadoop]# bin/hadoop fs -mkdir -p /input
[root@master hadoop]# bin/hadoop fs -put /root/hadoopdemo/file/file1.txt /input
[root@master hadoop]# bin/hadoop fs -put /root/hadoopdemo/file/file2.txt /input
[root@master hadoop]# bin/hadoop fs -put /root/hadoopdemo/file/file3.txt /input
[root@master hadoop]# bin/hadoop fs -put /root/hadoopdemo/file/file4.txt /input

长传成功,但是发现每执行异常hadoop命令都会报一个OpenJDK的警告。
先执行wordcount
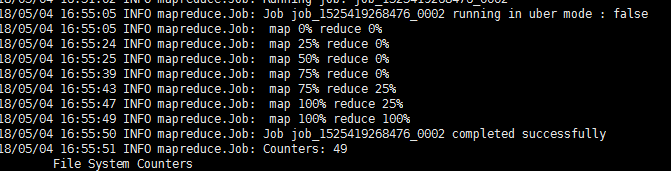
执行命令查看结果
bin/hadoop fs -text /output/wordcount/part-r-00000

问题
要关闭主从各个节点的防火墙,否则容易出现各种莫名的问题。
Ubuntu(ubuntu-12.04-desktop-amd64)
查看防火墙状态:ufw status
关闭防火墙:ufw disable
---------------------------------------------------------------
centos6.0
查看防火墙状态:service iptables status
关闭防火墙:chkconfig iptables off #开机不启动防火墙服务
--------------------------------------------------------------
centos7.0(默认是使用firewall作为防火墙,如若未改为iptables防火墙,使用以下命令查看和关闭防火墙)
查看防火墙状态:firewall-cmd --state
关闭防火墙:systemctl stop firewalld.service