增量式爬取
概念:监控网站数据更新的情况,以便于爬取到最新更新出来的数据。
实现核心:去重
-
实战中去重的方式:记录表
-
记录表需要记录什么?记录的一定是爬取过的相关信息。
- 爬取过的相关信息:例如每一步电影的详情页的url
- 只需要使某一组数据,改组数据可以作为该部电影的唯一标识即可,刚好电影详情页的url 就可以作为电影的唯一标识。只要可以表示电影唯一标识的数据我们统称为数据指纹。
-
去重的方式对应的记录表:
-
python中的set集合(不可以)
set集合无法持久化存储
-
redis中的set集合是可以的
-可以持久化存储
-
-
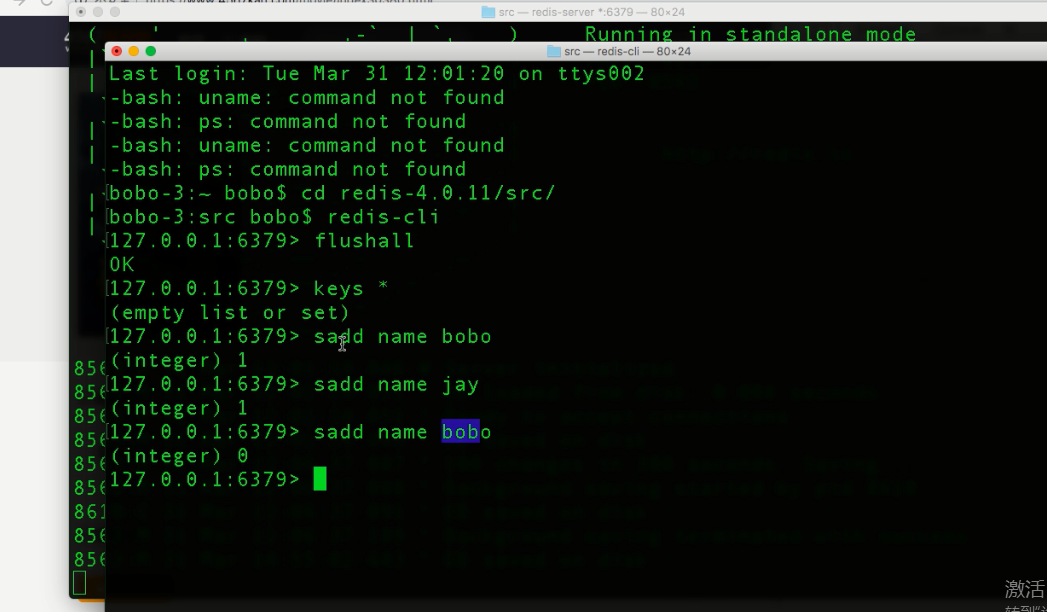
以上图片创建一个集合,叫name 插入数据bobo .jay,但是在插入bobo时返回0,说明插入失败,因为集合不能重复!!利用返回值进行判断!
-
数据指纹一般是经过加密
- 当前案例的数据指纹没必要加密
- 什么情况数据指纹需要加密?
- 如果数据的唯一标识表示的内容数据量比较大,可以使用hash将数据加密成32位密文
- 目的是为了节省空间!! 因为你把密文存到redis,当url相同,密文也相同,redis也能识别重复,就会返回0 无法插入!
- 如果数据的唯一标识表示的内容数据量比较大,可以使用hash将数据加密成32位密文
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from zlsPro.items import ZlsproItem
from redis import Redis
class ZlsSpider(CrawlSpider):
name = 'zls'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.4567kan.com/index.php/vod/show/class/%E5%8A%A8%E4%BD%9C/id/1.html']
conn = Redis(host='127.0.0.1',port=6379)
rules = (
Rule(LinkExtractor(allow=r'page/d+.html'), callback='parse_item', follow=False),
)
def parse_item(self, response):
#解析电影的名称+电影详情页的url
li_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li')
for li in li_list:
title = li.xpath('./div/a/@title').extract_first()
detail_url = 'https://www.4567kan.com'+li.xpath('./div/a/@href').extract_first()
ex = self.conn.sadd('movie_urls',detail_url)
#ex==1插入成功,ex==0插入失败
if ex == 1: #detail_url表示的电影没有存在于记录表中
#爬取电影数据:发起请求
print('有新数据更新,正在爬取新数据......')
item = ZlsproItem()
item['title'] = title
yield scrapy.Request(url=detail_url,callback=self.parse_detail,meta={'item':item})
else:#存在于记录表中
print('暂无数据更新!')
def parse_detail(self,response):
#解析电影简介
desc = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first()
item = response.meta['item']
item['desc'] = desc
yield item