1. 前三次作业总结
1.1 第一次作业
类图:
复杂度分析:
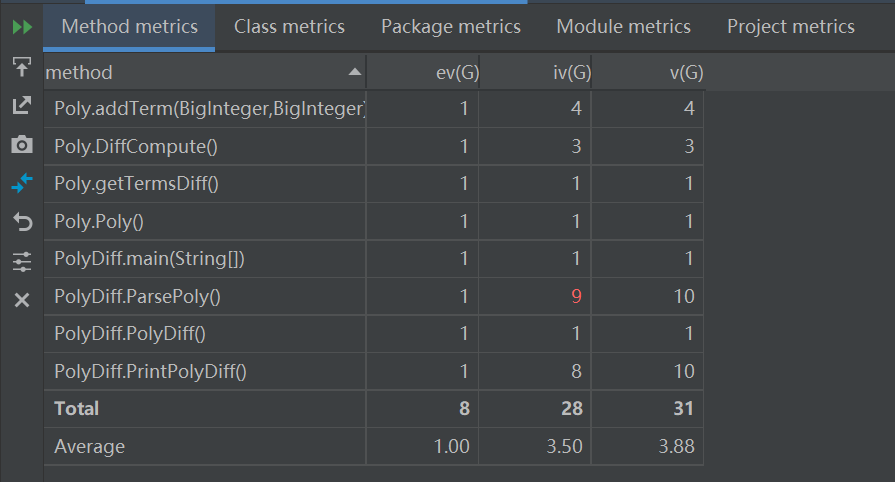
第一次作业比较简单,根据系数和指数构造的二元对,通过HashMap来储存和表达式和求导以后的表达式,同时进行合并同类项。
1.2 第二次作业
类图:
复杂度分析:

第二次作业引入了sin(x), cos(x)作为常数因子,在读入时依然可以使用正则表达式来进行判定。在存储表达式时,构建以x的指数、sin(x)的指数、cos(x)的指数为属性的项Term。然后建立以Term和系数为键值对的HashMap来储存表达式。表达式的输出与第一次作业相似。
1.3 第三次作业
类图:
复杂度分析:

在第三次作业中,引入了表达式因子和可嵌套的三角函数,在读取表达式时,需要进行递归。在解析表达式构造项和因子时,使用简单工厂模式进行归一化处理。在存储表达式时,使用ArrayList的结构。本次作业和上一次作业相比复杂度明显提升,因此选择重构代码,增加了一些功能类来进行判断表达式正确性和化简等的操作。
2. Bug分析
2.1 前两次作业的Bug分析
在前两次作业中,由于我并没有追求性能分满分,因此并没有通过一些复杂的设计来进行化简,因此没有出现较为明显的bug。
2.2 第三次作业Bug分析
在第三次作业中,我出现了较大的失误。由于我在解析表达式时仍然采用了大正则的方法,在递归读取嵌套的三角函数表达式时,程序并没有正常工作,当我意识到这一点并且修改了代码时,发现程序出现了很多功能性的Bug,因此没能在规定时间内通过中测。
3. 如何发现别人程序中的Bug
在前两次互测时,我主要采取的方法是进行黑箱测试,黑箱测试需要解决的主要问题是如何构建测试样例。我所采用的方法是形式化验证。在我写代码时,我就会开始构造我的测试样例集,首先针对每个单元设计单独的样例,然后进行综合,测试不同单元之间协同性的样例。这样随着代码的逐渐完善,测试样例集也会不断完善。通过这样的方法,不仅便于我们查找自己程序的Bug,进而不断完善代码;也可以通过对代码的完善,丰富自己的测试样例集。
4. 关于工厂模式
在第二次实验后,我认识到通过工厂模式来构造对象可以极大地降低代码的耦合度。但是事实上,在进行多个类的实例化时,工厂模式并不使用于所有的情况。当类的数量较少,并且每个类的实例化仅需要一行new就可以完成时,显然使用工厂模式的代价大于它的受益。工厂模式真正发挥作用的场景是类的数量较多,并且类的实例化较为复杂时。比如在第三次作业中,表达式因子,嵌套因子的实例化均涉及到两个以上类的实例化,是指还需要使用递归来进行构造。这个时候使用工厂模式就能够明显降低代码的复杂度。
5. 对比和心得体会
5.1 不要赶DDL!不要赶DDL!不要赶DDL!重要的事说三遍。
5.2 关于面向过程与面向对象的体会
在过去的一个月中,我第一次接触到了面向对象的概念,尽管考虑问题时总还是习惯于过程化的解决方法,但是对于面向对象方法的使用多少有了一些经验。当我构建了一个类来独立解决某一方面的问题时,这个类内部解决问题的方法有时采用了过程化的思路。但是就目前而言,面向对象方法带给我最大的体会是,当我需要重构代码或者进行功能的扩展时,我可以很容易地认识到哪些类做了哪些工作,需要进行重构还是扩展,重构或者扩展之后对整个project的影响是什么样的。这种在写代码之前就产生的认识会极大地影响写代码的工作量,甚于于对于新产生的Bug位置都可以有一定程度的预判。
5.3 OO的学习体验
有一说一,OO的工作量确实要比想象中的大很多,但是互测的过程还是很有趣的。希望之后能hack到更多Bug吧。