在该系列的上一篇文章中,较为详细的描述了Spark程序的生命周期,这一篇我们以一段Spark代码为例,来详细拆解一下Spark程序的执行过程。
一、示例代码:
val ss = SparkSession.builder().appName("localhost").master("local[*]").getOrCreate()
val df1 = ss.range(2, 10, 2).toDF()
val df2 = ss.range(0, 20, 4).toDF()
val df11 = df1.repartition(3)
val df21 = df2.repartition(4)
val df12 = df11.selectExpr("id * 2 as id") // select1
val df3 = df21.join(df12, "id")
val df4 = df3.selectExpr("sum(id)") // select2
df4.collect().foreach(println(_))
df4.explain()
二、打印的执行计划和DAG图
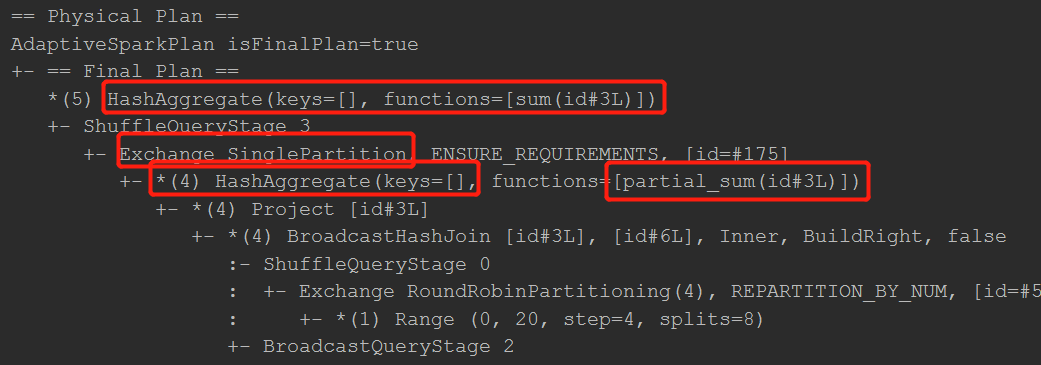
== Physical Plan == AdaptiveSparkPlan isFinalPlan=true +- == Final Plan == *(5) HashAggregate(keys=[], functions=[sum(id#3L)]) +- ShuffleQueryStage 3 +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#175] +- *(4) HashAggregate(keys=[], functions=[partial_sum(id#3L)]) +- *(4) Project [id#3L] +- *(4) BroadcastHashJoin [id#3L], [id#6L], Inner, BuildRight, false :- ShuffleQueryStage 0 : +- Exchange RoundRobinPartitioning(4), REPARTITION_BY_NUM, [id=#57] : +- *(1) Range (0, 20, step=4, splits=8) +- BroadcastQueryStage 2 +- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [id=#134] +- *(3) Project [(id#0L * 2) AS id#6L] +- ShuffleQueryStage 1 +- Exchange RoundRobinPartitioning(3), REPARTITION_BY_NUM, [id=#62] +- *(2) Range (2, 10, step=2, splits=8)
DAG图:



三、分析
1、首先看两个toDF方法和对应两个DataFrame的repartition方法
默认用range方式创建DataFrame时的分区数是8个,而我们repartition的分区数分别为3和4,分区数不同触发shuffle。
出现shuffle是Spark中stage划分的原则,所以此处两个repartition触发了两次shuffle。
这两次shuffle对应命令行中即下面两处:
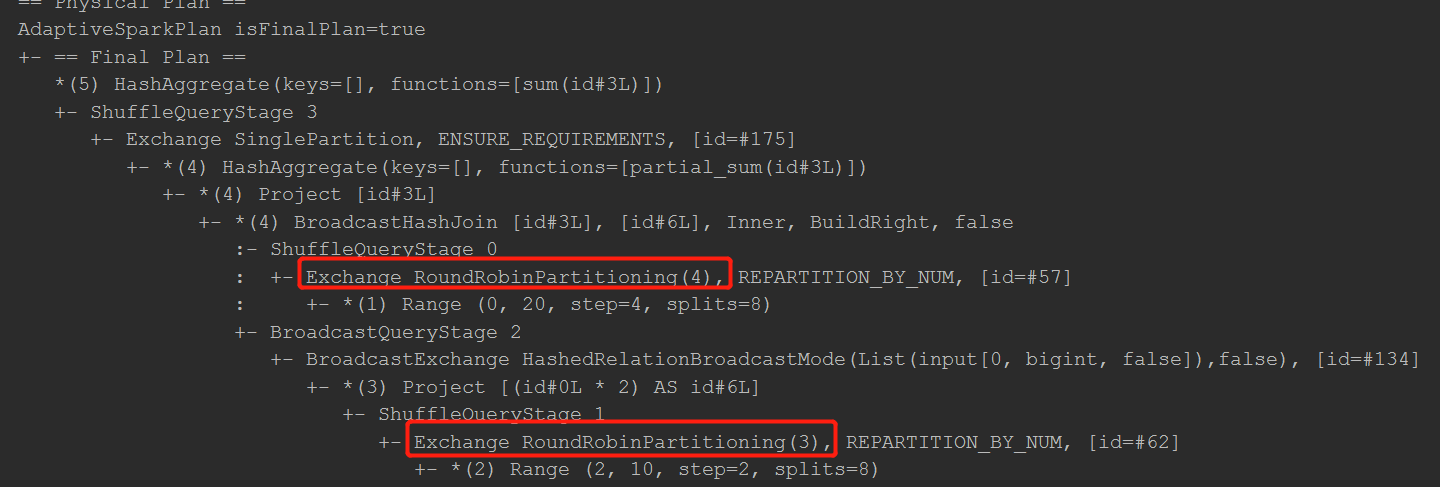
对应DAG图中是如下所示:

2、第一个selectExpr
该行代码对应执行计划中是【(3) Project】那一行,在DAG图中为下面标识处,因为只相当于一个map,故无需移动数据
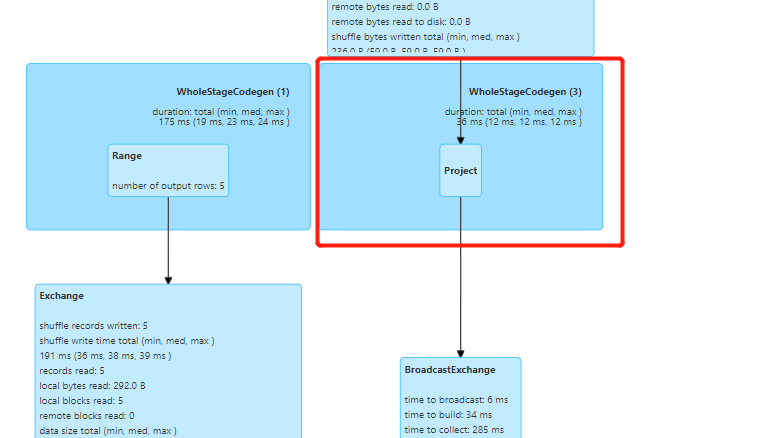
3、join操作
代码示例中的join操作,是进行了一次内关联,正常来说此处是需要触发shuffle的,即两个df均需进行数据的移动。但看DAG图会发现只有右边的DF即df12发生了Exchange即shuffle,为什么会这样呢?
这时Spark针对join的一种优化。Spark认为,如果参与join的双方,有一方的数据量少于10M,则会将该DF转成广播变量发给每个节点,每个节点中的另一个DF中的数据就可直接在本节点做map操作,减少数据的转移量。
当然,如果两个DF都少于10M,则取数据量较少的一方进行广播。本示例中对df12进行的广播,即BroadcastExchange。
广播完之后就是BroadcastHashJoin了,在执行计划中进行了形象的关联,用冒号的连线表示两个DF的关联。

4、第二个selectExpr的sum操作
在DAG图中可以看到,sum的操作涉及两次HashAggregate和一次Shuffle(Exchange):
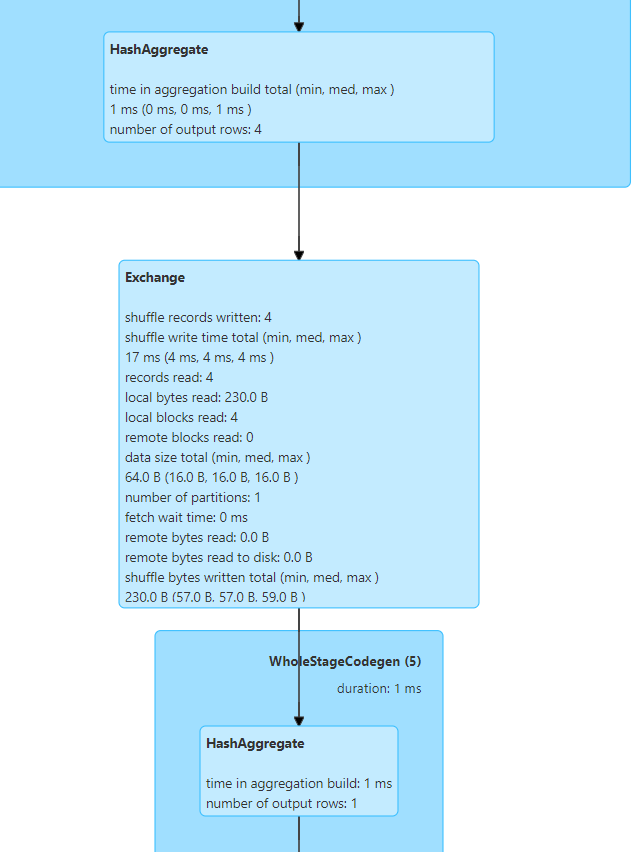
而通过执行计划可以得到更详细的信息,如下图所示。首先的第一个HashAggregate是partial_sum部分求和,即先对每个分区内的id求和。
然后是一个SinglePartition的shuffle,它的作用就是把所有分区的数据合并到一个分区上去,最后一个HashAggregate即对该单个分区的所有数据进行求和。
尾声
至此,这个简单的spark用例的执行流程便分析完了,但其中还有很多隐藏的知识点。
比如DAG图中的WholeStageCodegen是什么? 其实它是Spark对迭代计算的一种优化,它可以将每行数据进行计算时所用的小函数内联成一两个大函数执行,这样可以充分利用编译器以及CPU的优化特性,将执行性能提升一个数量级。细心的话会发现在日志的执行计划中,有的行前面会有一个星号*标识,该标识就表示该段代码启用了codegen的代码生成,是优化过的。
比如Spark还有什么其他的内置优化点?为什么这里用的是SingePartition而不是其他Partition方式?RoundRobinPartitioning的作用原理是什么?Spark性能优化如何分析进行...
问题太多,勿急,且慢慢研究。