一、Zookeeper
1、Zookeeper理解
概念:Zookeeper 是一个开源的分布式协调服务框架 ,主要用来解决分布式集群中应用系统的一致性问题和数据管理问题
特点:Zookeeper 本质上是一个分布式文件系统, 适合存放小文件,也可以理解为一个数据库。
Zookeeper 中存储的其实是一个又一个 Znode, Znode 是 Zookeeper 中的节点。
Znode 是有路径的, 例如 /data/host1 , /data/host2 , 这个路径也可以理解为是Znode 的 Name
Znode也可以携带数据, 例如说某个 Znode 的路径是 /data/host1 , 其值是一个字符串 "192.168.0.1"
正因为 Znode 的特性, 所以 Zookeeper 可以对外提供出一个类似于文件系统的试图, 可以通过操作文件系统的方式操作 Zookeeper
使用路径获取 Znode
获取 Znode 携带的数据
修改 Znode 携带的数据
删除 Znode
添加 Znode
2、Zookeeper架构
Zookeeper集群是一个基于主从架构的高可用集群
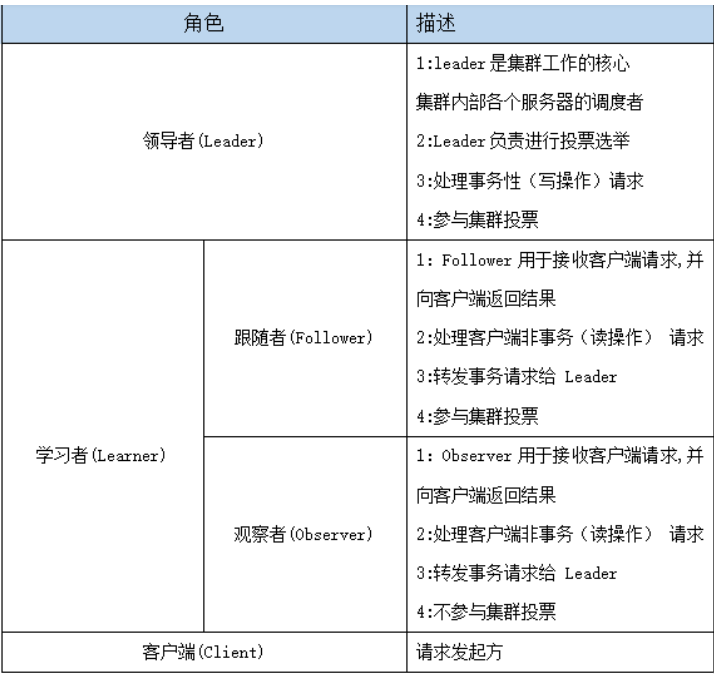
每个服务器承担如下三种角色中的一种
1.Leader:一个Zookeeper集群同一时间只会有一个实际工作的Leader,它会发起并维护与各Follwer及Observer间的心跳。所有的写操作必须要通过Leader完成再由Leader将写操作广播给其它服务器。
2.Follower:一个Zookeeper集群可能同时存在多个Follower,它会响应Leader的心跳。Follower可直接处理并返回客户端的读请求,同时会将写请求转发给Leader处理,并且负责在Leader处理写请求时对请求进行投票。
3.Observer 角色与Follower类似,但是无投票权。
3、Zookeeper的选举机制
1.服务器启动时期的Leader选举
进行leader选举至少两台机器,一般都为奇数个机器,选举过程如下:
①每个Server发起投票
②接收来自各个服务器的投票
③处理投票:
- 优先检查ZXID。ZXID比较大的服务器优先作为Leader。
- 如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器。
对于Server1而言,它的投票是(1, 0),接收Server2的投票为(2, 0),首先会比较两者的ZXID,均为0,再比较myid,此时Server2的myid最大,于是更新自己的投票为(2, 0),然后重新投票,对于Server2而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可。
④统计投票。
每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于Server1、Server2而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出Leader。
⑤改变服务器状态