简介
本文是阅读 《Docker 容器和容器云》 的读书笔记,书中第三章详细讲解了 Docker 的核心原理,本文主要是 Linux namespace 机制。namespace 一般都会有父子关系,一般来说是父 namespace 可以创建、修改、访问子 namespace,而放过来不行,namespace 提供了某种程度上的资源隔离,使到子 namespace 中的进程操作不会影响到父进程。
UTS 隔离
UTS(UNIX Time-sharing System) namespace 提供了主机名和域名的隔离,运行代码需要 root 权限,否则将会失败。
#include <cerrno>
#include <csignal>
#include <iostream>
#include <sched.h>
#include <unistd.h>
#include <signal.h>
#include <sys/wait.h>
constexpr int STACK_SIZE = 1024 * 1024;
static char child_stack[STACK_SIZE];
char* const child_args[] = {
"/bin/bash",
NULL
};
int child_main(void* args) {
std::cout << "child process" << std::endl;
sethostname("NewNamespace", 12);
execv(child_args[0], child_args);
return 1;
}
int main() {
// root permission is required
int child_pid = clone(child_main, child_stack + STACK_SIZE, SIGCHLD, NULL);
std::cout << child_pid << " " << errno << std::endl;
waitpid(child_pid, NULL, 0);
std::cout << "main exited" << std::endl;
return 0;
}
IPC 隔离
进程间通信涉及的资源主要包括信号量,消息队列和共享内存。
在上面代码中的 clone 函数中,增加 CLONE_NEWIPC 这个标识符,可以创建一个 IPC 资源隔离的进程。
int child_pid = clone(child_main, child_stack + STACK_SIZE,
CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
相关命令:
ipcmk -Q # 创建消息队列
ipcs -q # 列举出所有的消息队列
使用上面的命令,我们可以现在宿主上创建一个消息队列,然后运行可执行程序,在里面查看消息队列,我们会发现找不到。
(base) percent1@ubuntu:~/code/cmake_cpp_cuda/build$ ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x785e4c5f 0 percent1 644 0 0
0x5329368e 32769 root 644 0 0
0x875bbc3e 65538 percent1 644 0 0
0x2ab3fc5d 98307 percent1 644 0 0
(base) percent1@ubuntu:~/code/cmake_cpp_cuda/build$ sudo ./cpp/docker/docker
1961014 0
child process
(base) root@NewNamespace:~/code/cmake_cpp_cuda/build# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
PID 隔离
PID namespace 是树状结构的,系统启动的时候,会创建一个 root namespace,在这个 namespace 中可以新创建出子 namespace,从而可以形成树状的层级关系。这种层级关系就像进程一样,比如父 PID namespace 可以看到子 PID namespace 中的所有进程,反过来不行;每个 PID namespace 中的第一个进程 PID 1 具有特权;
unshare 和 setns 允许用户在原有进程中建立命名空间并进行隔离,但是当前进程不会进入新的命名空间,它的子进程会。原因是,如果当前进程进入了新的 PID 命名空间,那么当前进程的 PID 会发生变化,存在一定不合理的之处。Docker exec 原理大概就是使用 setns 加入已经存在的命名空间,最终还是要调用 clone 函数。
PID 隔离,在上面代码的基础上加上 CLONE_NEWPID 标志位,即可隔离 PID 命名空间。
int child_pid = clone(child_main, child_stack + STACK_SIZE,
CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
编译之后,运行,我们可以使用 echo $$ 查看当前进程的 PID,可以看到在新的命名空间中,PID 是 1。如果使用 ps aux 等命令,还是可以看到父 PID namespace 中的进程,原因是这个命令应该是通过 /proc 下面的文件来查看正在运行程序的。可以使用命令 mount -t proc proc /proc 挂载一个新的 proc 目录,之后就可以看到只有两个进程。但是退出来的时候再次运行 ps aux 会报错,提示 mount -t proc proc /proc 才可以,但是运行起来会发现需要 root 权限,而 sudo 因为修改了这个目录的原因,不能使用 tty 来输入密码。此时我们可以使用 echo 'yourpassword' | sudo -S mount -t proc proc /proc 来修复。
(base) root@NewNamespace:~/code/cmake_cpp_cuda/build# echo $$
1961014
(base) root@NewNamespace:~/code/cmake_cpp_cuda/build# sudo ./cpp/docker/docker
1995381 0
child process
(base) root@NewNamespace:~/code/cmake_cpp_cuda/build# echo $$
1
文件系统隔离
文件系统的挂载状态有几种:共享挂载,从属挂载,共享从属挂载,不可绑定挂载。如下图所示,箭头的含义表示,一边的修改会影响到另一边。默认情况下,mount 都是 private 挂载的,两个不同的 namespace 之间是互相隔离的。
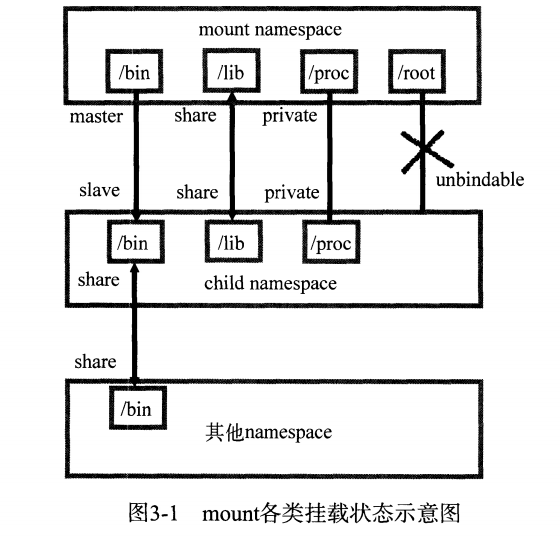
修改代码为如下,重新编译运行后,再运行 mount -t proc proc /proc,当前进程修改文件系统的挂载点,不会影响到父命名空间。不过在这之前需要将 /proc 目录变成 private 类型的,使用这个命令可以设置:mount --make-private proc。
int child_pid = clone(child_main, child_stack + STACK_SIZE,
CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
网络隔离
network namespace 提供了关于网络资源的隔离:网络设备,IPv4 和 IPv6 协议栈,IP 路由表,防火墙,/proc/net 目录,/sys/class/net 目录,socket 等资源。
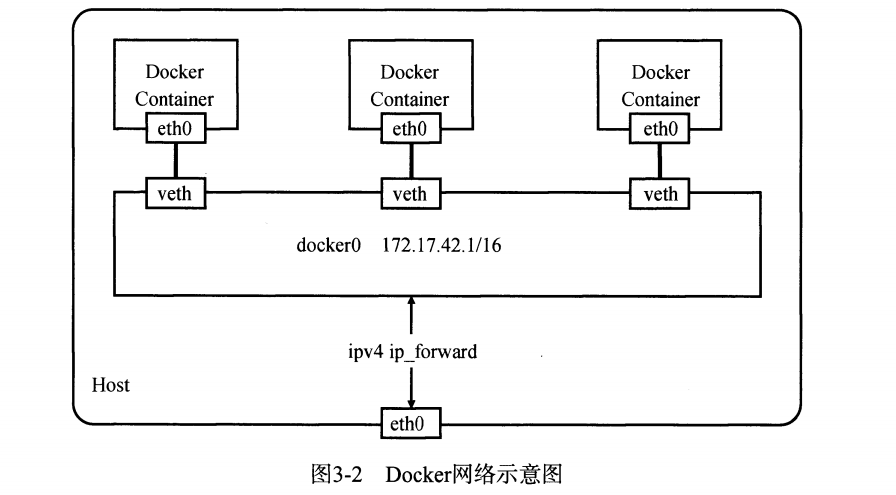
在上面的代码中加上 CLONE_NEWNET 标志位就可以实现网络隔离。书中这部分的讨论不多,先跳过。
用户隔离
user namespace 让普通用户的进程可以通过 clone 创建的新进程在新 user namespace 中可以拥有不同的用户和用户组,这意味着在新的 user namespace 中,可以使用 root 权限。简单来说,user namespace 可以让普通用户拥有 root 权限。不过,这并非意味着一个普通用户就可以任意使用 root 权限了,因为权限的检查最终还是要受限于父 user namespace。比如 /etc/sudoers 这个文件,就不能使用这种方式来修改。举个可以用 root 权限的例子,前面我们使用不同的标志位,有的是需要 root 权限的,可是不会违反父 user namespace 的约束,所以可以先启动 CLONE_NEWUSER 这个标志位的进程,然后再启动含有其他标志位的进程。
#include <bits/types/FILE.h>
#include <cerrno>
#include <csignal>
#include <cstdio>
#include <iostream>
#include <sched.h>
#include <unistd.h>
#include <signal.h>
#include <sys/wait.h>
#include <sys/capability.h>
constexpr int STACK_SIZE = 1024 * 1024;
static char child_stack[STACK_SIZE];
char* const child_args[] = {
"/bin/bash",
NULL
};
void set_uid_map(pid_t pid, int inside_id, int outside_id, int length) {
char path[256];
sprintf(path, "/proc/%d/uid_map", getpid());
FILE* uid_map = fopen(path, "w");
fprintf(uid_map, "%d %d %d", inside_id, outside_id, length);
fclose(uid_map);
}
void set_gid_map(pid_t pid, int inside_id, int outside_id, int length) {
char path[256];
sprintf(path, "/proc/%d/gid_map", getpid());
FILE* gid_map = fopen(path, "w");
fprintf(gid_map, "%d %d %d", inside_id, outside_id, length);
fclose(gid_map);
}
int child_main(void* args) {
std::cout << "child process " << geteuid() << " " << getegid() << std::endl;
set_uid_map(getpid(), 0, 1008, 1); // id -u => 1008
set_gid_map(getpid(), 0, 1008, 1); // id -g => 1008
cap_t caps = cap_get_proc();
std::cout << cap_to_text(caps, NULL) << std::endl;
execv(child_args[0], child_args);
return 1;
}
int main() {
int child_pid = clone(child_main, child_stack + STACK_SIZE,
CLONE_NEWUSER | SIGCHLD, NULL);
std::cout << child_pid << " " << errno << std::endl;
waitpid(child_pid, NULL, 0);
std::cout << "main exited" << std::endl;
return 0;
}
总结

使用了以上介绍的隔离技术,一个 Docker 容器的雏形已经形成。在编码的过程中,可以深刻的体会到,Docker 容器的本质,其实就是一个进程!namespace 在这其中起到了 “资源隔离” 的作用。