原理
unordered_map 内部实现是散列表,是一个无序的容器。内部实现的散列表采用了链地址法,意思是使用链表来解决散列冲突。当往容器中加入一个元素的时候,会计算散列值,然后取余之后放到一个桶 (bucket) 里。如果不断往容器加元素,那么所有的桶都会变成一个很长的链表,这样效率就很低了,这种情况应该如何避免呢?unordered_map 采用了扩容的机制,当负载因子 (load factor) 超过了阈值,就会进行一次扩容。负载因子的计算方法是总键值对数除以桶数。扩容的时候,会重新计算散列,重新放入到桶里。
cplusplus 文档:https://www.cplusplus.com/reference/unordered_map/unordered_map/
代码声明
从以下的代码中,我们可以看到 unordered_map 内部的存储使用 allocator 来管理的,存储的是 std::pair 类型的数据。
template<class _Key, class _Tp,
class _Hash = hash<_Key>,
class _Pred = std::equal_to<_Key>,
class _Alloc = std::allocator<std::pair<const _Key, _Tp> > >
class unordered_map;
自定义类型
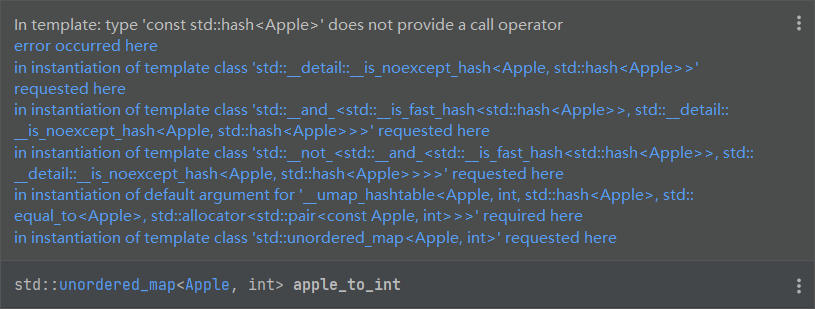
一个自定义的类型,如果要作为 Key,应该如何写代码呢?假如我们定义了一个 Apple 类型,里面只有构造器(构造器内部只有输出)。直接将 Apple 作为 key 会出现报以下错误。std::hash<Apple> does not provide a call provider. 这意味着需要我们自定义散列的规则。如果细细思考 unordered_map 的模板参数,你会发现你不仅需要定义散列的规则,还需要定义相等判定的规则。
散列
可以采用的实现方式:
- 覆写 operator() 的类或者结构体,需要在 unordered_map 实例化的地方指定模板参数
struct apple_hash {
std::size_t operator()(const Apple& apple) const {
return std::hash<int>()(apple.GetData());
}
};
std::unordered_map<Apple, int, apple_hash> apple_to_int;
- 特化 std::hash 来实现,经过特化后,在使用 unordered_map 的时候就不用指定模板参数了
特化 std::hash 的方法如下,覆写 operator() 需要注意几个细节,返回类型是 size_t,输入的参数是 const 引用,函数体是 const。
template<>
struct std::hash<Apple> {
std::size_t operator()(const Apple& apple) const {
return std::hash<int>()(apple.GetData());
}
};
判等
- 覆写 operator() 的类或者结构体作为模板参数
struct apple_equal {
bool operator()(const Apple& x, const Apple& y) const {
std::cout << "apple_equal" << std::endl;
return x.GetData() == y.GetData();
}
};
std::unordered_map<Apple, int, std::hash<Apple>, apple_equal> apple_to_int; // 不知道怎么跳过第三个参数进行实例化hhh
- 特化 std::equal_to来实现
template<>
struct std::equal_to<Apple> {
bool operator()(const Apple& x, const Apple& y) const {
return x.GetData() == y.GetData();
}
};
- 覆写类的 operator==() 方法
bool operator==(const Apple& apple) const {
return this->data_ == apple.data_;
}