Raft
一致性算法。
整体结构
Raft 的作用是让多台主机保持一致。fault-tolerant virtual machine 论文中提到过两种方法,一种是复制所有的状态到别的主机上,包括 CPU,内存,IO 设备。另一种方法是对主机进行状态机建模,通过复制主机的日志,执行相同的日志内容来保持不同主机的状态一致。Raft 使用的是第二种。
Raft 中的主机数量是固定的,每台主机都知道其他主机的位置以便通信。当启动集群的使用,Raft 首先进行的是选出一个 Leader,Leader 负责接收客户端的请求,将请求写入到日志中,发送给其他主机。当一条日志为大多数主机所拥有的时候,Commit 一条日志。当 Leader 写入日志的时候,并不执行日志,当日志被 Committed 了之后,执行这条日志。
Raft 分成五个部分:
- Leader Election
- Log Replication
- Cluster Membership changes
- Log Compaction
- Client Interaction
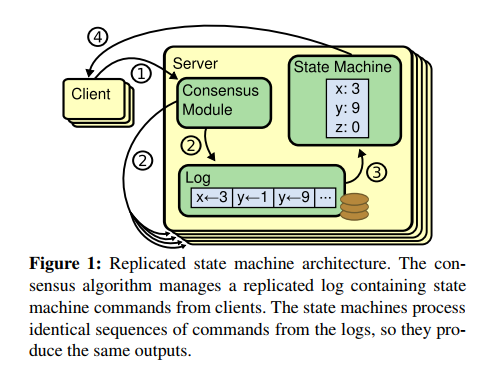
Raft 基础
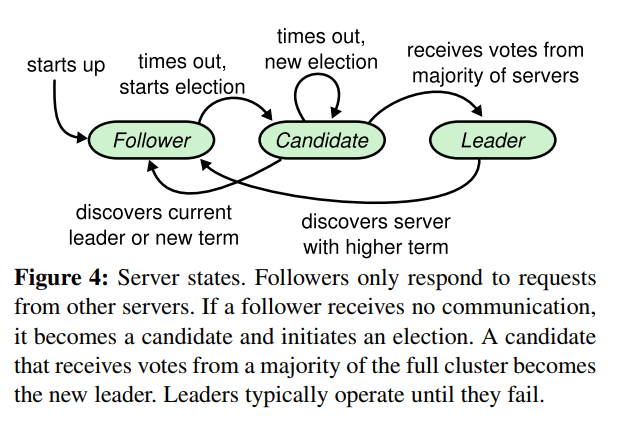
集群中的每台主机,属于某一种状态。一开始所有的主机是 follower 状态,当选举计时器超时,转化为 candidate 状态。当 candidate 得到了大多数主机的选票的时候,candidate 转化为 leader 状态。
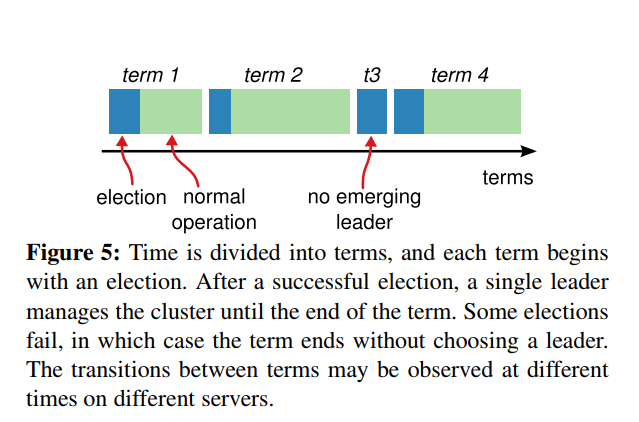
raft 中引入了任期 (Term) 的概念。每个任期从选举开始,选举完成后,leader 执行其他操作,直到任期结束。在 Lab2 中,任期是无限长的,除非发生了故障,比如 followers 无法接收到 leader 的心跳包,此时 follower 会开始进行选举,从而产生新的任期中的 leader。下图中,t3 只有选举,因为有可能发生这样一种状况,没有一个 candidate 得到足够的票数,成为 leader。candidate 的选举计时器超时之后,开始新的任期,重新拉票。为了防止 t3 这种情况频繁出现,Raft 使用随机的选举计时器。lab2 中,每次选举计时器超时之后,重新在 400 ~ 700 毫秒之间随机选择一个数作为下一次的选举计时。
算法总结
在进行 Lab2 的时候,严格按照图 2 的表述去实现即可。

Leader Election
每台主机上设置一个选举计时器,当这个计时器超时,发出拉票请求。当收到了大多数主机的投票,这台主机宣称自己是 Leader,并定时向其他主机发送心跳包。主机上的选举计时器,在接收到合法的心跳包之后,会重新计时。主机给另一台主机投票的时候,也会重置选举计时器。
选举的时候,需要选取出拥有全部已经提交的日志的主机。因此当一台主机接收到拉票请求的时候,它需要判断是否给出选票。首先,判断请求的主机任期是否比自己的新,如果是,那么需要转化为 follower 状态,并且更新任期,重置选票。接下来,判断请求的主机拥有的日志是否比自己的更新 (more up-to-date)。更新的含义是,最后一个日志的任期是否更新,如果请求的主机更新,那么投票。如果最后一个日志任期一致,判断长度是否更长,请求的主机更长,那么投票。
lab2 中的实现。
if args.Term >= rf.currentTerm {
if args.Term > rf.currentTerm {
rf.state = follower
rf.currentTerm = args.Term
rf.votedFor = -1
...
}
if rf.votedFor == -1 || rf.votedFor == args.CandidateId {
lastEntry := rf.log[len(rf.log)-1]
// outdate case 1
if lastEntry.Term > args.LastLogTerm {
return
}
// outdate case 2
if lastEntry.Term == args.LastLogTerm && lastEntry.Index > args.LastLogIndex {
return
}
...
}
}
Log Replication
Log Replication 分为两个部分:append 和 commit。
append,leader 强制将 follower 的日志改为和自己的一致。不管 follower 中原来的日志是什么样子的,leader 被选举出来之后,就让 follower 的日志和自己的完全一致。leader 对每个 follower 维护一个 nextIndex 数组,这个数组的值,指向了要发给 follower 的下一个日志条目 (log entry)。在发送条目的 RPC 中,需要额外携带前一个日志的 index、term 两个信息。这两个信息用来判断,是否可以 append。如果 follower 在对应的 index 上没有对应的 term,那么拒绝 append,返回失败。leader 接收到失败,将对应的 nextIndex 减 1,重新发送。当 leader 接收到了成功,将对应的 nextIndex 加 1。实现的时候,在发心跳包的时候,检查 nextIndex 是否比 log 的日志大,如果大,那么发送多出来的日志。
commit,当 leader 成功将一条日志 append 到大多数主机上之后,这条日志就可以 commit 了。commit 的意思是让主机执行这条日志。为了保证主机 commit 了之后,所有的主机都会 commit 同一条日志,引入了一个约束,主机仅 commit 当前任期的日志。下图展示了一种情况,如果 leader 中某个日志在大多数主机上 append 了之后,就提交,那么这会导致一个 commit 被覆盖的问题,导致了主机的不一致。a 中,S1 被选为 leader,将日志复制到 S2,此时日志条目 2 还没有被提交。b 中,S1 离线了,S5 选举计时器超时并开始拉票,成功拉到了 S3、S4,成为了 leader,于是接收请求,在日志中写入条目 3。c 中,S5 断线了,S1 上线并选为了 leader。此时将条目 2 复制到 S3,条目 2 在大多数主机上了,于是提交了这个日志,在 S1、S2、S3 上执行了这个条目。d 中,S1 故障,S5 重新被选为了 leader,因为它拥有的条目比 S2、S3、S4 新,所以可以被选为 leader。当它选为了 leader 之后,强制其他主机和自己的日志一致,于是覆盖了其他主机,甚至覆盖了已经执行的条目 2。因此错误就发生了。
为了避免这种错误,引入约束:主机仅 commit 当前任期的日志,不 commit 大多数但非当前任期的日志。commit 的方式是,设置一个 commitIndex,这样可以间接 commit 前面的日志。

Cluster Membership changes
集群的配置是固定的,如果集群要增加主机或者移除主机该如何做呢?下图的方法展示了直接将更新主机的配置。这种方法的问题是,不可能一次性更新全部主机的配置,这样会导致部分主机先更新为新配置,从而有可能使到同一个任期,两个 leader。

可以有两种方法解决这个问题,一种是关掉集群,更新配置后重新启动集群。这样的话,在关闭期间是不可用的。另一种方法是,使用两阶段的方法 (two-phase approach)。第一阶段,让主机同时拥有两种配置。第二阶段,让主机转到新的配置上。Raft 中使用一个特殊的 log entry 来让主机进行状态转化,当主机要转换状态的时候,在 log 中加入一个条目,leader 将这个条目复制到其他主机上。当主机见到这个条目的时候,就进行转换,无需等到提交。
两阶段方法,log replication 会在两种配置中都进行,不管一个主机是否出现在新配置中,都要进行 log replication。leader 可以在新旧配置中产生,不管一个 leader 是否最终会在新配置中。达成一致需要在新旧配置中都达到大多数的状态。
在更改配置的过程中会出现三个问题:
- 新加入的主机需要时间来复制 log。可以考虑额外的阶段,加入集群中,不影响任何决定,但是要 leader 发 log 给他们。
- leader 不是最终配置的一部分,step down。
- 新配置中移除的主机,它的选举计时器会超时。解决办法是,给加一个下界,在这个范围内接收到的拉票请求,直接忽略。
Log Compaction
为了防止日志无限制增长,可以使用快照,将当前系统的状态保存下来,丢弃快照之前的所有日志。每个主机独立地进行快照,我觉得这个应该是有限制的,比如对于 commit 了的日志,才能进行快照,否则快照下来的日志后续需要被覆盖,但是又被丢弃了,找不到那个条目了。如果一个 follower 落后太多了,并且 leader 快照后,将日志丢弃了,那么这个落后的 follower 该如何赶上呢?方法是,使用一个 RPC,leader 快照后,可以检查 follower 的 nextIndex,如果发现落后太多,那么可以调用 InstallSnapshot 来让 follower 安装快照,重做日志内容。
Client Interaction
找到 leader:client 随机发送请求给一个主机,如果主机不是 leader,那么发送足够的信息给 client,让它可以找到 leader。如果主机崩溃了,那么重新这个过程。
同一请求可能被多次执行:一个 leader 在 commit 一条日志后,在回复 client 之前,崩溃了。那么 client 会重新请求,导致了同一请求多次执行。解决办法是加一个序列号,如果 leader 接收到了一个已经执行了的请求,那么立即返回,可以根据序列号判断是否执行。
读取过时数据:只读操作可以不写日志。这样可能导致,在一个旧的 leader 上,它不知道已经有新的 leader,然后读取操作返回了过时数据。使用心跳包来确定是否还是 leader。(exchange heartbeat messages with a majority of the cluster)。文本中有这样一段:
a leader must have the lastest information on which entries are committed.
这有点奇怪,因为按照图 2 去实现,leader 应该直到这个信息的。可能这里是没有这个信息的,所以需要提交一个 no-op 来确定提交的最新日志。