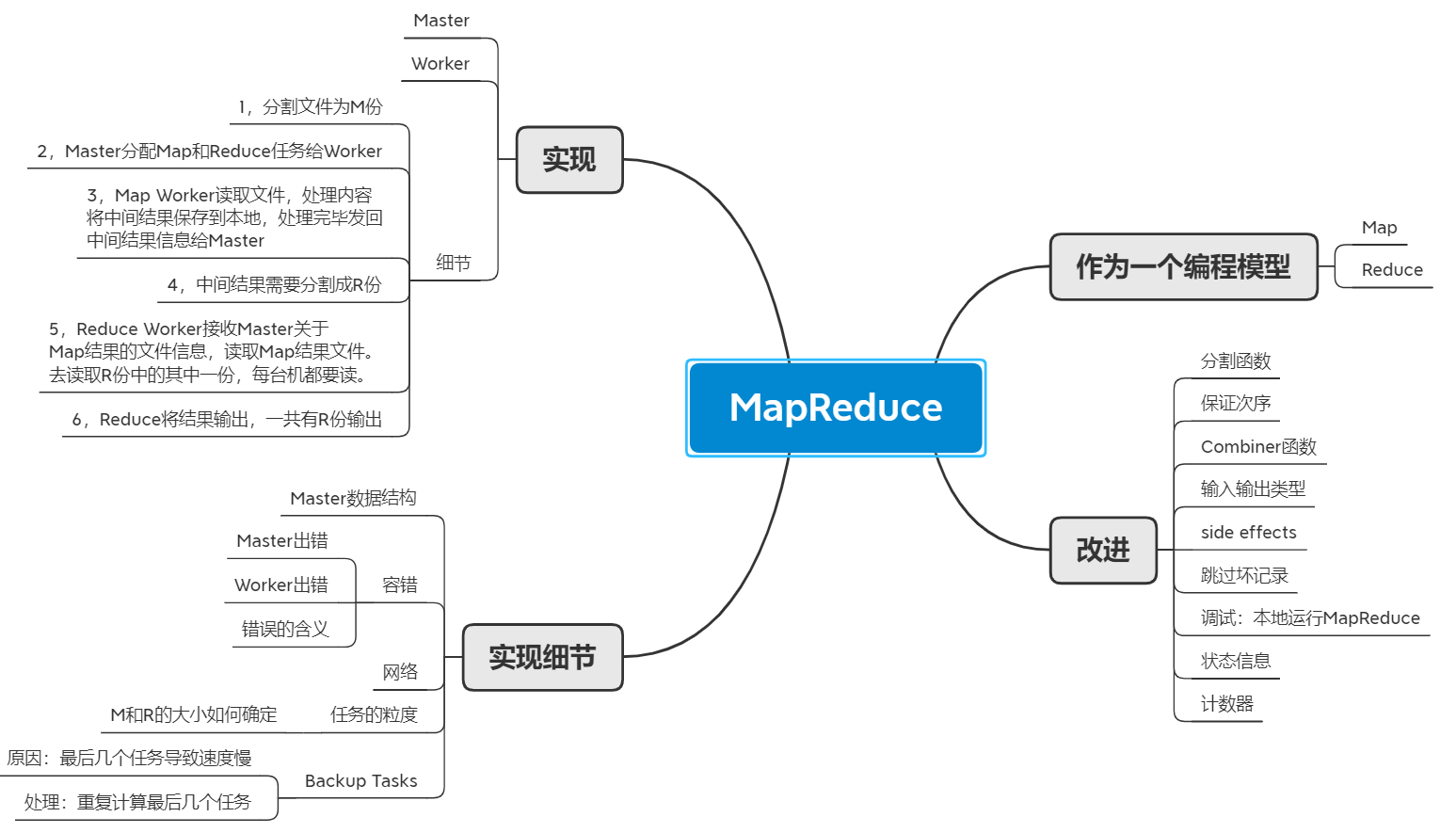
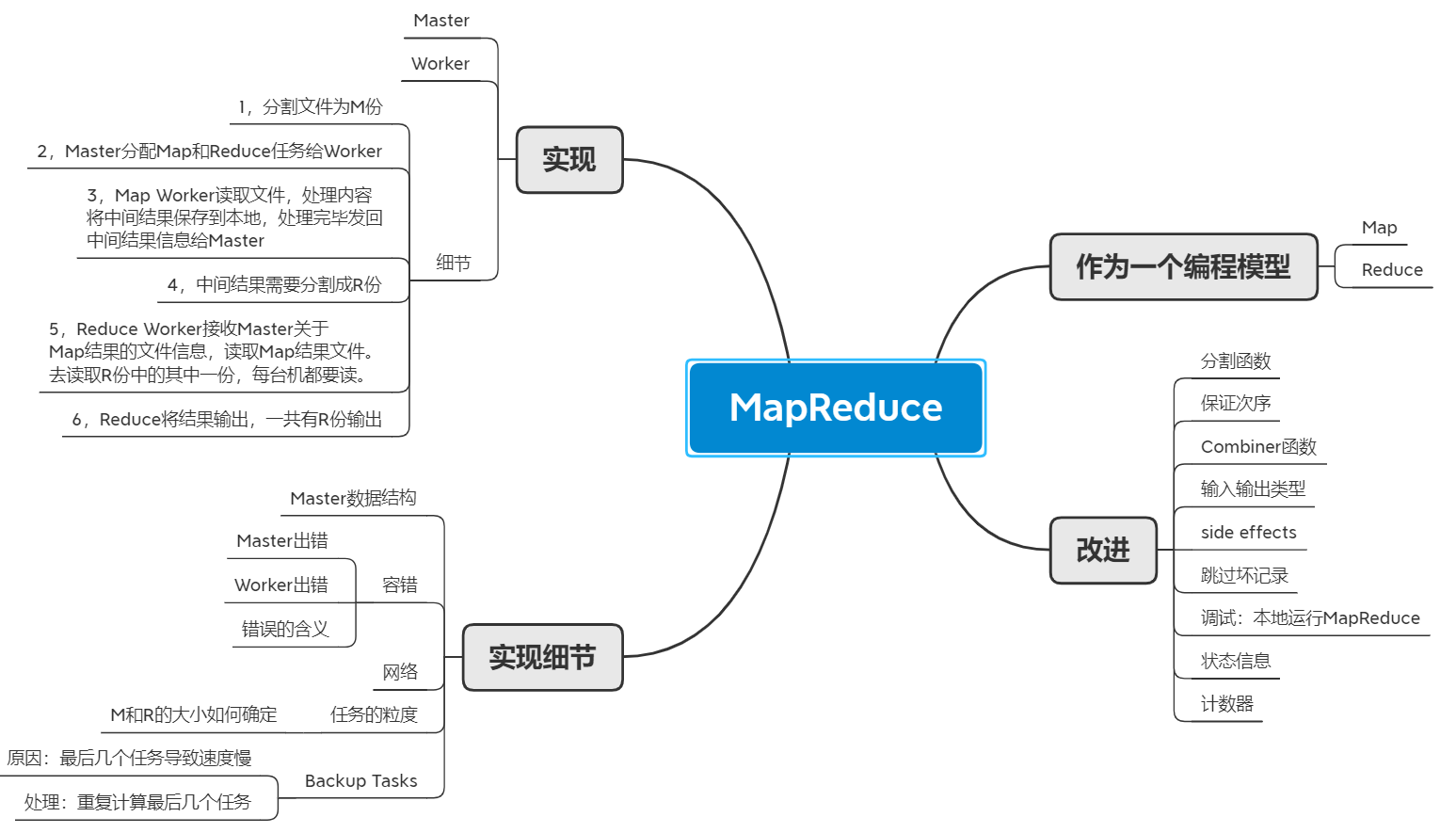
MapReduce
思维导图
需求
一个计算的模型,提供Map和Reduce接口,隐藏底层的分布式计算的实现细节。程序员只需要写Map函数、Reduce函数来做数据处理,分布式计算的过程由MapReduce框架来处理。
概念
Map函数是一个应用到序列中所有元素的简单操作:Map(k1,v1) → list( (k2,v2) )
Map is an idiom in parallel computing where a simple operation is applied to all elements of a sequence, potentially in parallel. It is used to solve embarrassingly parallel problems: those problems that can be decomposed into independent subtasks, requiring no communication/synchronization between the subtasks except a join or barrier at the end. (Wiki)
Reduce函数将数组规约成一个元素:Reduce(k2, list(v2)) → list( (k3, v3) )
The reduction operator is a type of operator that is commonly used in parallel programming to reduce the elements of an array into a single result.(Wiki)
deterministic和non-deterministic:
用来形容一个函数:给定一个输入,是否可以总是得到同一个输出。对于deterministic:分布式计算的正确结果要和串行计算的结果是一样的。
整体结构
结构图
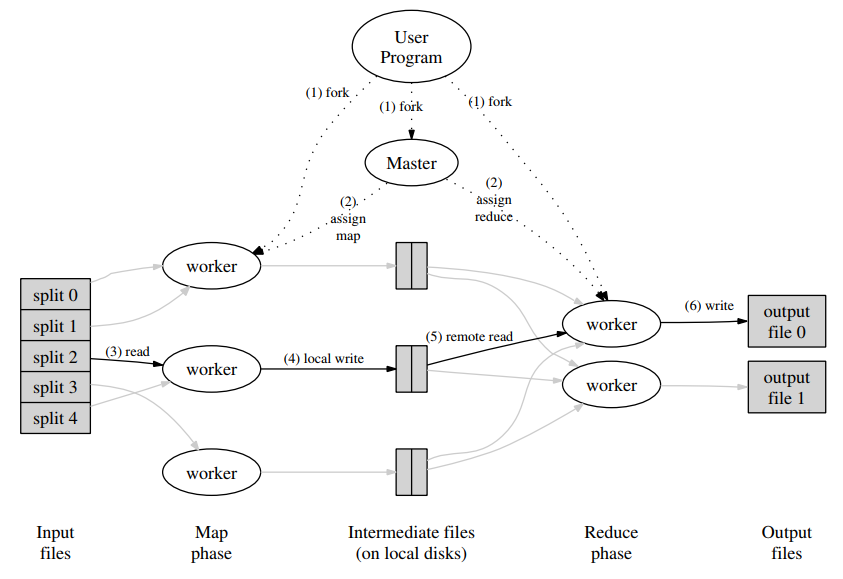
计算过程
1, 将输入文件分割成 M 份,一份16MB ~ 64MB。在集群上启动 MapReduce 程序,其中一个是 Master ,其他是 Worker。
2, Master 负责挑选一个任务分配给一个空闲的主机。
3, 当 Worker 收到了 Map 任务,Worker 读取对应的数据分割,调用用户定义的 Map 函数来处理数据,处理产生的键值对保存在内存中。
4, 将键值对分割成 R 份,定期存储到硬盘,并将存储的位置告知 Master。
5, Master 将存储的位置告诉 Reduce Worker,Reduce Worker 通过 RPC 读取远程的 Map Worker 上对应的文件,读取完毕,按键对中间结果排序。
6, Reduce 遍历排好序的中间结果,每个键都是连续的一块,将一个键和这个键对应的所有中间结果传给 Reduce 函数进行处理。将结果写入到这个Reduce 任务的输出文件尾。
7, 当所有任务处理完成,Master 唤醒用户程序。
实现细节
Master数据结构:
Task状态、Worker状态、中间文件位置
任务粒度(Task Granularity):
输入文件分割成 M 份,中间文件分割成 R 份。M 是由输入文件大小和每个分割大小共同决定,一个分割的大小一般是 16MB ~ 64MB。R 由用户指定。
局部性(Locality):
将 GFS 的位置信息考虑在内,给 Worker 分配任务时,需要处理的文件尽可能在 Worker本地或相邻的主机(交换机连接起来的局域网中)。
错误处理
Master出错:
停止计算;检查点,保存Master的数据结构。
Worker出错:
Master 定期 ping,检查是否有响应。
Map 任务不管完成还是没完成,都重新计算。因为完成的任务结果将会被保存到 Map Worker 本地,如果 Map Worker 离线了,Reduce Worker 就无法通过 RPC 读取中间结果。(看运行流程的5)
Reduce 任务若完成了,将会被保存到GFS,无需重新执行;Reduce任务若没有完成,需要重新分配任务。
改进
Backup Tasks:
Straggler问题,有Worker耗费很长的时间去执行最后的几个任务,拖慢了整体的速度。
解决办法,当只剩下最后几个in-progress任务的时候,去将这个几个任务重新分发去执行一下。同个任务,只要有一个Worker完成了,就标记为完成。
Partitioning Function:
将Map的中间结果的某些键映射到一起。比如键是URL,但是想要将这些URL的按照主机映射到一起。
允许用户提供分割函数。原本的分割方法:Hash(key)%NReduce。用户提供了分割函数Hostname,Hash(Hostname(key))%NReduce
Ordering Guarantees:
中间结果或者输出结果保持有序。
Combiner Function:
存在大量重复的中间键值对,合并部分中间结果,相当于先Reduce一下,以减少网络传输。
用户自定义一个Combiner函数,Map结束后,将结果合并起来之后保存下来。
Input and Output Types:
自定义从输入文件读入键值对的方式;自定义输出到文件的格式。
Skipping Bad Records:
跳过造成错误的记录。
每个Worker安装一个handler捕捉错误,在调用Map/Reduce之前,先记录下序列号,如果发生了错误,handler检测到了,发一个UDP包给Master。之后Master分配任务的时候,告诉Worker这些记录需要跳过。
Local Execution:
串行执行代码,用于调试Map和Reduce函数。
Status Information:
显示执行状态,用于分析。
Counters:
用户可以在Map/Reduce的函数中给某些事件计次。
计数器的值定期传给Master,当所有任务都完成了之后,Master合计所有次数,返回给用户程序。当有backup-task或者重新执行的时候,Master不能重复合计次数。
Q&A
Q:任务数量远多于主机数量的目的是?
A:负载均衡。
Q: Job和Task的区别?
A:用户提交的是一个Job,Job包含一系列Task。