DStream编程数据模型
DStream(Discretized Stream)作为Spark Streaming的基础抽象,它代表持续性的数据流。
这些数据流既可以通过外部输入源赖获取,也可以通过现有的Dstream的transformation操作来获得。
在内部实现上,DStream由一组时间序列上连续的RDD来表示。每个RDD都包含了自己特定时间间隔内的数据流。

对DStream中数据的各种操作也是映射到内部的RDD上来进行的
对Dtream的操作可以通过RDD的transformation生成新的DStream。

我们把RDD加上一个时间属性来区分。
我们可以把DStream当作一连串用时间分段的RDD来看待,并且这串是RDD像流水一样绵绵不断的。
当我们对DStream采取一些操作的时候,其中每段时间的RDD之间相互对应转化成新的DStream.
SparkStreaming的基本步骤
1.通过创建输入DStream来定义输入源
2.通过对DStream应用转换操作和输出操作来定义流计算,用户自己定义处理逻辑
3.通过streamingContext.start()来开始接收数据和处理流程
4.通过streamingContext.awaitTermination()方法来等待处理结果
5.通过streamingContext.stop()来手动结束流计算流程
具体步骤
1.创建StreamingContext对象
(1)通过 new StreamingContext(SparkConf,Interval)建立
创建StreamingContext对象所需的参数有两个一个是 SparkConf 配置参数,一个是时间参数。
与SparkContext基本一致,SparkConf 配置参数需要指明Master,任务名称(如NetworkWordCount)。
时间参数我们如果以秒来定义的话格式为Seconds(n),这个参数定义了Spark Streaming需要指定处理数据的时间间隔,
时间参数需要根据用户的需求和集群的处理能力进行适当的设置。
例如
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
这里的那么Spark Streaming会以1s为时间窗口进行数据处理。
(2)通过 new StreamingContext(SparkContext,Interval)建立
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(1))
这种方式一般用于spark-shell中建立,
spark-shell中给我们定义好了sc,但是spark-shell并没有为我们建立好ssc
所以我们需要自己建立ssc
在建立ssc 之前我们需要导入 import org.apache.spark.streaming._
在编码之前我们需要设置一下日志等级,以便我们之后的程序调试。
要么日志会把所有东西都显示出来,你根本找不到哪条是错误信息。
//设置日志等级的单例对象
import org.apache.log4j.{Logger,Level}
import org.apache.spark.internal.Logging
object StreamingLoggingExample extends Logging{
def setStreamingLogLevels(): Unit ={
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if(!log4jInitialized)
logInfo("Setting log level to [WARN] for streaming example" +
"To override add a custom log4j.properties to the classpath"
)
Logger.getRootLogger.setLevel(Level.WARN)
}
}
//使用单例对象修改日志等级
StreamingLoggingExample.setsetStreamingLogLevels()
//注意在编码之前设置
2.创建InputDStream
我们通过设置InputDStream来设置数据的来源
Spark Streaming支持的数据源有文件流、套接字流、RDD队列流、Kafka、 Flume、HDFS/S3、Kinesis和Twitter等数据源。
(1)文件流
val lines = ssc.textFileStream("file:///")
文件流的加载的是系统中的文件,可以是HDFS中的也可以是本地的,跟创建RDD是一样的。
(2)套接字流
val lines = ssc.socketTextStream("hostname", port.toInt)
(3)RDD队列流
创建RDD队列
val rddQueue = new scala.collection.mutable.SynchronizedQueue[RDD[Int]]()//建立一个整型RDD的队列流,初始化为空
创建RDD队列流的spark流进行监听
val lines = ssc.queueStream(rddQueue)
rdd队列流中添加数据
for(i <- 1 to 100){
rddQueue += ssc.sparkContext.makeRDD(1 to 100,2) //添加数据到RDD队列
}
(4)Kafka
3.操作DStream
对于从数据源得到的DStream,用户可以在其基础上进行各种操作。
与RDD类似,DStream也提供了自己的一系列操作方法,这些操作可以分成三类:普通的转换操作、窗口转换操作和输出操作。
(1)普通的转换操作
|
转换 |
描述 |
|
map(func) |
源 DStream的每个元素通过函数func返回一个新的DStream。 |
|
flatMap(func) |
类似与map操作,不同的是每个输入元素可以被映射出0或者更多的输出元素。 |
|
filter(func) |
在源DSTREAM上选择Func函数返回仅为true的元素,最终返回一个新的DSTREAM 。 |
|
repartition(numPartitions) |
通过输入的参数numPartitions的值来改变DStream的分区大小。 |
|
union(otherStream) |
返回一个包含源DStream与其他 DStream的元素合并后的新DSTREAM。 |
|
count() |
对源DStream内部的所含有的RDD的元素数量进行计数,返回一个内部的RDD只包含一个元素的DStreaam。 |
|
reduce(func) |
使用函数func(有两个参数并返回一个结果)将源DStream 中每个RDD的元素进行聚 合操作,返回一个内部所包含的RDD只有一个元素的新DStream。 |
|
countByValue() |
计算DStream中每个RDD内的元素出现的频次并返回新的DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素出现的频次。 |
|
reduceByKey(func, [numTasks]) |
当一个类型为(K,V)键值对的DStream被调用的时候,返回类型为类型为(K,V)键值对的新 DStream,其中每个键的值V都是使用聚合函数func汇总。注意:默认情况下,使用 Spark的默认并行度提交任务(本地模式下并行度为2,集群模式下位8),可以通过配置numTasks设置不同的并行任务数。 |
|
join(otherStream, [numTasks]) |
当被调用类型分别为(K,V)和(K,W)键值对的2个DStream 时,返回类型为(K,(V,W))键值对的一个新 DSTREAM。 |
|
cogroup(otherStream, [numTasks]) |
当被调用的两个DStream分别含有(K, V) 和(K, W)键值对时,返回一个(K, Seq[V], Seq[W])类型的新的DStream。 |
|
transform(func) |
通过对源DStream的每RDD应用RDD-to-RDD函数返回一个新的DStream,这可以用来在DStream做任意RDD操作。 |
|
updateStateByKey(func) |
返回一个新状态的DStream,其中每个键的状态是根据键的前一个状态和键的新值应用给定函数func后的更新。这个方法可以被用来维持每个键的任何状态数据。 |
注意:
transform(func)
该transform操作(转换操作)连同其其类似的 transformWith操作允许DStream 上应用任意RDD-to-RDD函数。
它可以被应用于未在 DStream API 中暴露任何的RDD操作。
例如,在每批次的数据流与另一数据集的连接功能不直接暴露在DStream API 中,但可以轻松地使用transform操作来做到这一点,这使得DStream的功能非常强大。
例如,你可以通过连接预先计算的垃圾邮件信息的输入数据流(可能也有Spark生成的),然后基于此做实时数据清理的筛选,如下面官方提供的伪代码所示。
事实上,也可以在transform方法中使用机器学习和图形计算的算法。
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
val cleanedDStream = wordCounts.transform { rdd =>
rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning
...
}
updateStateByKey操作
我们使用的一般操作都是不记录历史数据的,也就说只记录当前定义时间段内的数据,跟前后时间段无关。
如果我们想统计历史时间内的总共数据并且实时更新呢?
该 updateStateByKey 操作可以让你保持任意状态,同时不断有新的信息进行更新。要使用此功能,必须进行两个步骤 :
(1) 定义状态 - 状态可以是任意的数据类型。
(2) 定义状态更新函数 - 用一个函数指定如何使用先前的状态和从输入流中获取的新值 更新状态。
对DStream通过updateStateByKey(updateFunction)来实现实时更新。
更新函数有两个参数 1.newValues 是当前新进入的数据 2.runningCount 是历史数据,被封装到了Option中。
为什么历史数据要封装到Option中呢?有可能我们没有历史数据,这个时候就可以用None,有数据可以用Some(x)。
当然我们的当前结果也要封装到Some()中,以便作为之后的历史数据。
我们并不用关心新进入的数据和历史数据,系统会自动帮我们产生和维护,我们只需要专心写处理方法就行。
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {//定义的更新函数
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}
val runningCounts = pairs.updateStateByKey[Int](updateFunction)//应用
示例:
(1)首先我们需要了解数据的类型
(2)编写处理方法
(3)封装结果
//定义更新函数
//我们这里使用的Int类型的数据,因为要做统计个数
def updateFunc(newValues : Seq[Int],state :Option[Int]) :Some[Int] = {
//传入的newVaules将当前的时间段的数据全部保存到Seq中
//调用foldLeft(0)(_+_) 从0位置开始累加到结束
val currentCount = newValues.foldLeft(0)(_+_)
//获取历史值,没有历史数据时为None,有数据的时候为Some
//getOrElse(x)方法,如果获取值为None则用x代替
val previousCount = state.getOrElse(0)
//计算结果,封装成Some返回
Some(currentCount+previousCount)
}
//使用
val stateDStream = DStream.updateStateByKey[Int](updateFunc)
(2)窗口转换函数
Spark Streaming 还提供了窗口的计算,它允许你通过滑动窗口对数据进行转换,窗口转换操作如下:
|
转换 |
描述 |
|
window(windowLength, slideInterval) |
返回一个基于源DStream的窗口批次计算后得到新的DStream。 |
|
countByWindow(windowLength,slideInterval) |
返回基于滑动窗口的DStream中的元素的数量。 |
|
reduceByWindow(func, windowLength,slideInterval) |
基于滑动窗口对源DStream中的元素进行聚合操作,得到一个新的DStream。 |
|
reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks]) |
基于滑动窗口对(K,V)键值对类型的DStream中的值按K使用聚合函数func进行聚合操作,得到一个新的DStream。 |
|
reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks]) |
一个更高效的reduceByKkeyAndWindow()的实现版本,先对滑动窗口中新的时间间隔内数据增量聚合并移去最早的与新增数据量的时间间隔内的数据统计量。例如,计算t+4秒这个时刻过去5秒窗口的WordCount,那么我们可以将t+3时刻过去5秒的统计量加上[t+3,t+4]的统计量,在减去[t-2,t-1]的统计量,这种方法可以复用中间三秒的统计量,提高统计的效率。 |
|
countByValueAndWindow(windowLength,slideInterval, [numTasks]) |
基于滑动窗口计算源DStream中每个RDD内每个元素出现的频次并返回DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素频次。与countByValue一样,reduce任务的数量可以通过一个可选参数进行配置。 |
在Spark Streaming中,数据处理是按批进行的,而数据采集是逐条进行的。
因此在Spark Streaming中会先设置好批处理间隔(batch duration),当超过批处理间隔的时候就会把采集到的数据汇总起来成为一批数据交给系统去处理。
对于窗口操作而言,在其窗口内部会有N个批处理数据,批处理数据的大小由窗口间隔(window duration)决定
而窗口间隔指的就是窗口的持续时间,在窗口操作中,只有窗口的长度满足了才会触发批数据的处理。
除了窗口的长度,窗口操作还有另一个重要的参数就是滑动间隔(slide duration)
它指的是经过多长时间窗口滑动一次形成新的窗口,滑动窗口默认情况下和批次间隔的相同,而窗口间隔一般设置的要比它们两个大。
在这里必须注意的一点是滑动间隔和窗口间隔的大小一定得设置为批处理间隔的整数倍。
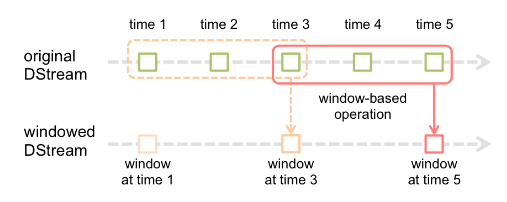
如图所示,批处理间隔是1个时间单位,窗口间隔是3个时间单位,滑动间隔是2个时间单位。
对于初始的窗口time 1-time 3,只有窗口间隔满足了定义的长度也就是3才触发数据的处理,不够3继续等待。
当间隔满足3之后进行计算后然后进行窗口滑动,滑动2个单位,会有新的数据流入窗口。
然后重复等待满足窗口间隔执行计算。
(3)输出操作
Spark Streaming允许DStream的数据被输出到外部系统,如数据库或文件系统。
由于输出操作实际上使transformation操作后的数据可以通过外部系统被使用,同时输出操作触发所有DStream的transformation操作的实际执行(类似于RDD操作)。
以下表列出了目前主要的输出操作:
|
转换 |
描述 |
|
print() |
在Driver中打印出DStream中数据的前10个元素。 |
|
saveAsTextFiles(prefix, [suffix]) |
将DStream中的内容以文本的形式保存为文本文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
|
saveAsObjectFiles(prefix, [suffix]) |
将DStream中的内容按对象序列化并且以SequenceFile的格式保存。其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
|
saveAsHadoopFiles(prefix, [suffix]) |
将DStream中的内容以文本的形式保存为Hadoop文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
|
foreachRDD(func) |
最基本的输出操作,将func函数应用于DStream中的RDD上,这个操作会输出数据到外部系统,比如保存RDD到文件或者网络数据库等。需要注意的是func函数是在运行该streaming应用的Driver进程里执行的。 |
同样DStream也支持持久化
与RDD一样,DStream同样也能通过persist()方法将数据流存放在内存中,
4.启动Spark Streaming
通过streamingContext.start()来开始接收数据和处理流程
通过streamingContext.awaitTermination()方法来等待处理结果
通过streamingContext.stop()来手动结束流计算流程
示例
package SparkDemo
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamWordCount {
def main(args:Array[String]): Unit ={
//创建StreamingContext
val conf = new SparkConf().setMaster("local[*]").setAppName("StreamTest")
val ssc = new StreamingContext(conf,Seconds(20))
//建立文件流数据源通道
val lines = ssc.textFileStream("file:///")
lines.cache()//持久化
//处理,word count
val words = lines.flatMap(_.split(" "))
val wordPair = words.map((_,1))
val count = wordPair.reduceByKey(_+_)
count.print()
//启动StreamingContext
ssc.start()
ssc.awaitTermination()
}
}
然后我们将程序打包提交到spark集群中运行
当程序运行ssc.start()后,就开始自动循环进入监听状态,屏幕上会显示

这是正确的,如果我们在建立ssc的文件中再添加一个文件file3.txt
就可以在监听窗口中显示词频的统计了。

最后我们可以通过ssc.stop()停止程序,不过注意我们不能省略这里的圆括号。