我们有这样两个文件

任务:找出用户评分平均值大于4的电影。
我们看两个文件结果,第一个文件有电影的ID和名字,第二个文件有电影的ID和所有用户的评分
对于任务结果所需要的数据为电影ID,电影名字,平均评分。平均评分用所有用户评分总和/用户数来求出
1.我们先计算电影的评分
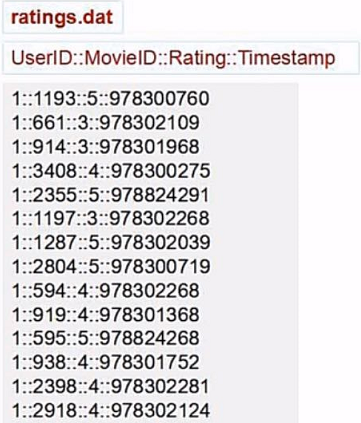
(1)先读取电影评分文件
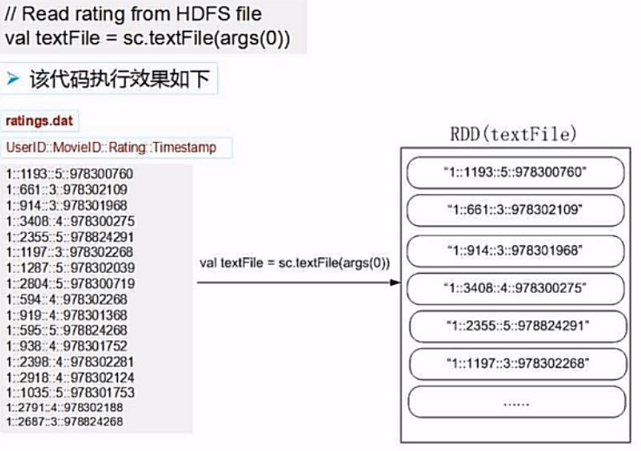
(2)取数据
我们看到每行的数据是通过::来进行连接的,然后我们需要的是第二列的电影ID以及第二列的评分。
我们把两个有用的数据取出来,组成键值对的形式。
为什么要组成键值对的形式?
数据中每个用户的对电影的评分都是分开的,所以我们需要对电影ID进行分组操作,把所有评分分组。
之前示例中我们知道groupByKey能进行分组,同时还能把所有相同Key的数据组合成一个集合。
当我们把所有数据集合之后就很容易操作计算了。
所以我们把数据组合成为<电影ID,评分>这样的键值对的形式。

3.分组计算平均评分
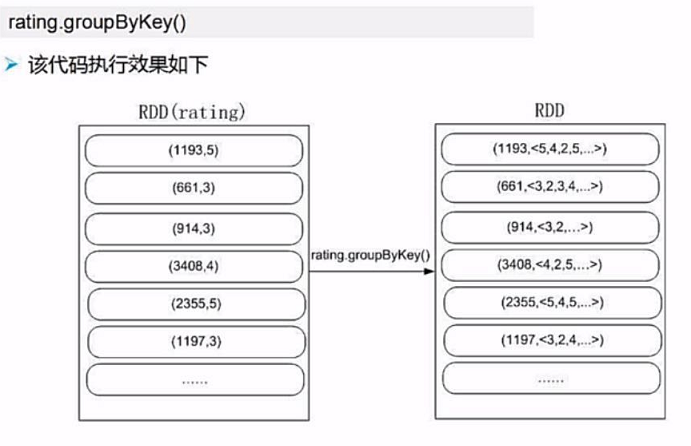
我们看到我们分组之后,所有相同电影的不同用户的评分都被收集到了一个集合中。
那么如何计算平均评分呢?评分总分 / 评分个数 = 平均评分
Scala集合提供了sum方法来可以计算集合总和,提供了size方法来计算数据条数。
正好不用我们额外去求了,如果集合没有定义方法,我们也可以遍历后计算得出要求的值。

2.在取电影ID和电影名
我们查看数据结构,数据是通过::连接的,对我们有用的数据为第一列电影ID和第二列电影名称

3.通过电影ID连接
我们把我们所有需要的数据都取出来了,接下来进行连接就可以了。
但是,我们连接需要把电影ID作为连接的key。
我们需要的结果为(ID,NAME,SCORE)
如果我们直接对id进行连接的话,我们连接出来的结果只有(NAME,SCORE)缺少了ID
所以我们需要再次对数据进行处理,我们通过.keyBy()方法新生成一个key,同时value为原始的数据
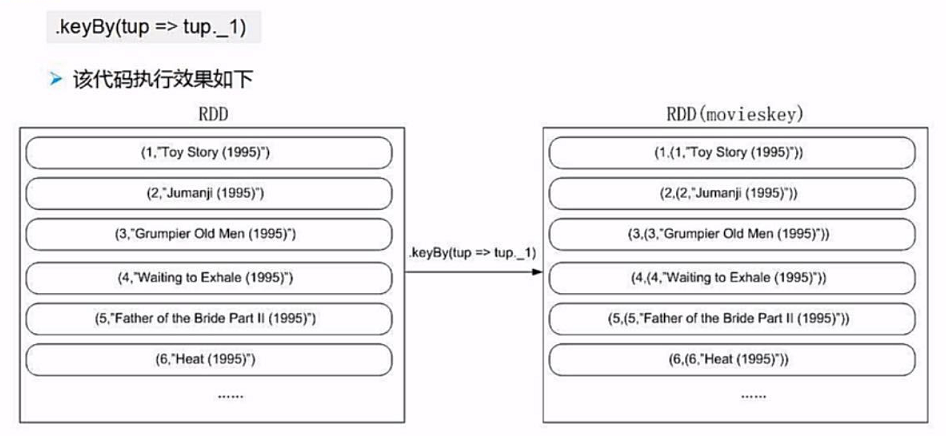
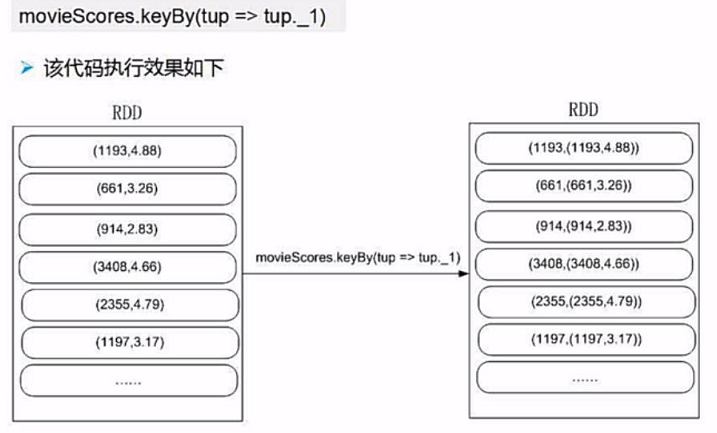
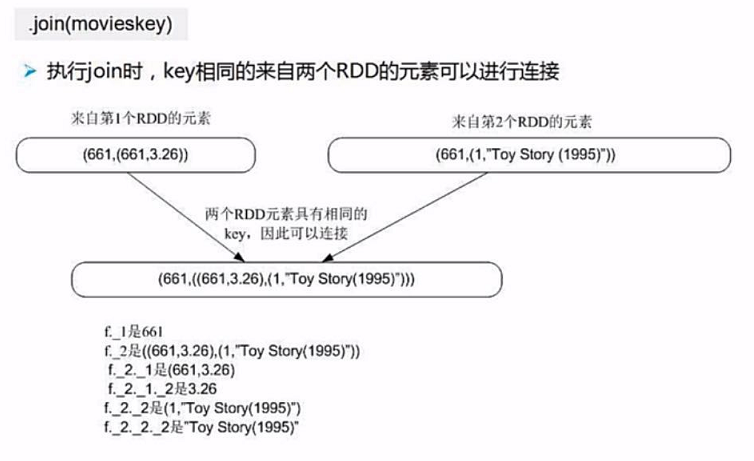
然后我们再进行连接操作,注意join连接操作是内链接,
连接后的key是连接键,value为所有相同key的集合,可以通过 _2._x 来进行访问
4.过滤求出平均评分大于4的记录
