作业信息
| 实验班级 | 机器学习实验-计算机18级 |
| 实验要求 | K-近邻算法及应用 |
| 实验目标 | 理解K-近邻算法原理,能实现算法K近邻算法 |
| 学号 | 3180701240 |
一、实验目的
1.理解K-*邻算法原理,能实现算法K*邻算法;
2.掌握常见的距离度量方法;
3.掌握K*邻树实现算法;
4.针对特定应用场景及数据,能应用K*邻解决实际问题。
二、实验内容
1.实现曼哈顿距离、欧氏距离、闵式距离算法,并测试算法正确性。
2.实现K*邻树算法;
3.针对iris数据集,应用sklearn的K*邻算法进行类别预测。
4.针对iris数据集,编制程序使用K*邻树进行类别预测。
三、实验报告要求
1.对照实验内容,撰写实验过程、算法及测试结果;
2.代码规范化:命名规则、注释;
3.分析核心算法的复杂度;
4.查阅文献,讨论K*邻的优缺点;
5.举例说明K*邻的应用场景。
四、实验过程及步骤
1.距离度量
利用python代码遍历三个点中,与1点距离最近的点
import math #导入数学运算函数 from itertools import combinations

#计算欧式距离
def L(x, y, p=2):
# x1 = [1, 1], x2 = [5,1] 在这里,实例是两个二维特征 x1 = [1, 1], x2 = [5,1]
if len(x) == len(y) and len(x) > 1:
# 当两个特征的维数相等时,并且维度大于1时。
sum = 0
# 目前总的损失函数值为0
for i in range(len(x)): # 用range函数来遍历x所有的维度,x与y的维度相等。
sum += math.pow(abs(x[i] - y[i]), p)
# math.pow( x, y )函数是计算x的y次方。
return math.pow(sum, 1/p)# 距离公式。
else:
return 0
# 输入样例,该列来源于课本 x1 = [1, 1] x2 = [5, 1] x3 = [4, 4]
# 计算x1与x2和x3之间的距离
for i in range(1, 5): # i从1到4
r = { '1-{}'.format(c):L(x1, c, p=i) for c in [x2, x3]} # 创建一个字典
print(min(zip(r.values(), r.keys()))) # 当p=i时选出x2和我x3中距离x1最近的点
结果:
(3.0, '1-[4, 4]')
(3.0, '1-[4, 4]')
(3.0, '1-[4, 4]')
(3.0, '1-[4, 4]')
2.编写K-近邻算法
python实现,遍历所有数据点,找出n个距离最近的点的分类情况,少数服从多数(不使用直接的python中现有的K-近邻算法包)
# 导包 import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from collections import Counter
# data 输入数据 iris = load_iris() # 获取python中鸢尾花Iris数据集 df = pd.DataFrame(iris.data, columns=iris.feature_names) # 将数据集使用DataFrame建表 df['label'] = iris.target # 将表的最后一列作为目标列 df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label'] # 定义表中每一列 # data = np.array(df.iloc[:100, [0, 1, -1]])
df # 将建好的表显示在屏幕上查看
结果:
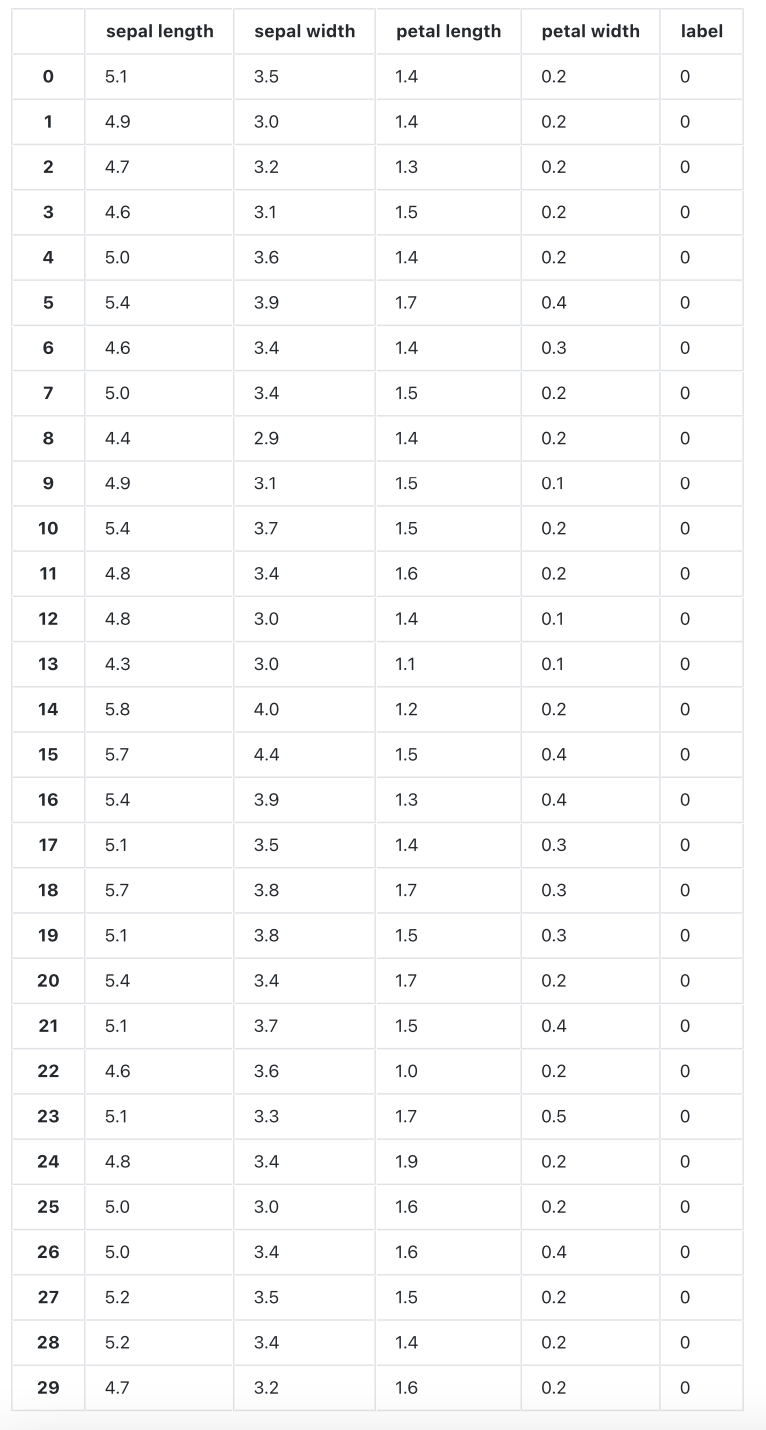

#数据进行可视化
#将标签为0、1的两种花,根据特征为长度和宽度打点表示
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
结果:
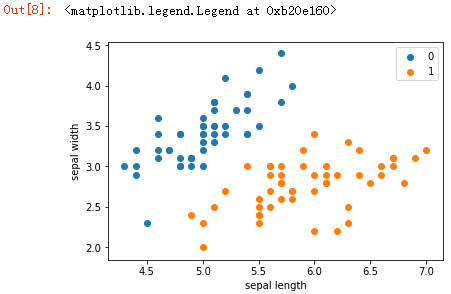
#取数据,并且分成训练和测试集合 data = np.array(df.iloc[:100, [0, 1, -1]]) #按行索引,取出第0列第1列和最后一列,即取出sepal长度、宽度和标签 X, y = data[:,:-1], data[:,-1]#X为sepal length,sepal width y为标签 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # train_test_split函数用于将矩阵随机划分为训练子集和测试子集
# 建立一个类KNN,用于k-近邻的计算
class KNN:
#初始化
def __init__(self, X_train, y_train, n_neighbors=3, p=2): # 初始化数据,neighbor表示邻近点,p为欧氏距离
self.n = n_neighbors
self.p = p
self.X_train = X_train
self.y_train = y_train
def predict(self, X):
# X为测试集
knn_list = []
for i in range(self.n): # 遍历邻近点
dist = np.linalg.norm(X - self.X_train[i], ord=self.p) # 计算训练集和测试集之间的距离
knn_list.append((dist, self.y_train[i])) # 在列表末尾添加一个元素
for i in range(self.n, len(self.X_train)): # 3-20
max_index = knn_list.index(max(knn_list, key=lambda x: x[0])) # 找出列表中距离最大的点
dist = np.linalg.norm(X - self.X_train[i], ord=self.p) # 计算训练集和测试集之间的距离
if knn_list[max_index][0] > dist: # 若当前数据的距离大于之前得出的距离,就将数值替换
knn_list[max_index] = (dist, self.y_train[i])
# 统计
knn = [k[-1] for k in knn_list]
count_pairs = Counter(knn) # 统计标签的个数
max_count = sorted(count_pairs, key=lambda x:x)[-1] # 将标签升序排列
return max_count
# 计算测试算法的正确率
def score(self, X_test, y_test):
right_count = 0
n = 10
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right_count += 1
return right_count / len(X_test)
clf = KNN(X_train, y_train) # 调用KNN算法进行计算
clf.score(X_test, y_test) # 计算正确率
结果:Out [12]:1.0
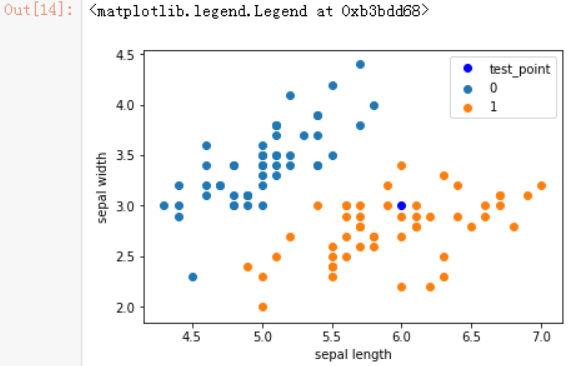
#预测点
test_point = [6.0, 3.0]
#预测结果
print('Test Point: {}'.format(clf.predict(test_point)))
结果:Test Point: 1.0
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
#打印预测点
plt.plot(test_point[0], test_point[1], 'bo', label='test_point')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
结果:
3.使用scikitlearn中编好的包直接调用实现K-近邻算法
sklearn.neighbors.KNeighborsClassifier
n_neighbors: 临近点个数
p: 距离度量
algorithm: 近邻算法,可选{'auto', 'ball_tree', 'kd_tree', 'brute'}
weights: 确定近邻的权重
# 导包 from sklearn.neighbors import KNeighborsClassifier
# 调用 clf_sk = KNeighborsClassifier() clf_sk.fit(X_train, y_train)
结果:
Out[16]:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform')
clf_sk.score(X_test, y_test) # 计算正确率
结果:Out [17]:1.0
4.针对iris数据集,编制程序使用K近邻树进行类别预测
建造kd树
# 建造kd树
# kd-tree 每个结点中主要包含的数据如下:
class KdNode(object):
def __init__(self, dom_elt, split, left, right):
self.dom_elt = dom_elt#结点的父结点
self.split = split#划分结点
self.left = left#做结点
self.right = right#右结点
class KdTree(object):
def __init__(self, data):
k = len(data[0])#数据维度
#print("创建结点")
#print("开始执行创建结点函数!!!")
def CreateNode(split, data_set):
#print(split,data_set)
if not data_set:#数据集为空
return None
#print("进入函数!!!")
data_set.sort(key=lambda x:x[split])#开始找切分平面的维度
#print("data_set:",data_set)
split_pos = len(data_set)//2 #取得中位数点的坐标位置(求整)
median = data_set[split_pos]
split_next = (split+1) % k #(取余数)取得下一个节点的分离维数
return KdNode(
median,
split,
CreateNode(split_next, data_set[:split_pos]),#创建左结点
CreateNode(split_next, data_set[split_pos+1:]))#创建右结点
#print("结束创建结点函数!!!")
self.root = CreateNode(0, data)#创建根结点
#KDTree的前序遍历
def preorder(root):
print(root.dom_elt)
if root.left:
preorder(root.left)
if root.right:
preorder(root.right)
遍历kd树
# 遍历kd树
#KDTree的前序遍历
def preorder(root):
print(root.dom_elt)
if root.left:
preorder(root.left)
if root.right:
preorder(root.right)
from math import sqrt
from collections import namedtuple
# 定义一个namedtuple,分别存放最近坐标点、最近距离和访问过的节点数
result = namedtuple("Result_tuple",
"nearest_point nearest_dist nodes_visited")
#搜索开始
def find_nearest(tree, point):
k = len(point)#数据维度
def travel(kd_node, target, max_dist):
if kd_node is None:
return result([0]*k, float("inf"), 0)#表示数据的无
nodes_visited = 1
s = kd_node.split #数据维度分隔
pivot = kd_node.dom_elt #切分根节点
if target[s] <= pivot[s]:
nearer_node = kd_node.left #下一个左结点为树根结点
further_node = kd_node.right #记录右节点
else: #右面更近
nearer_node = kd_node.right
further_node = kd_node.left
temp1 = travel(nearer_node, target, max_dist)
nearest = temp1.nearest_point# 得到叶子结点,此时为nearest
dist = temp1.nearest_dist #update distance
nodes_visited += temp1.nodes_visited
print("nodes_visited:", nodes_visited)
if dist < max_dist:
max_dist = dist
temp_dist = abs(pivot[s]-target[s])#计算球体与分隔超平面的距离
if max_dist < temp_dist:
return result(nearest, dist, nodes_visited)
# -------
#计算分隔点的欧式距离
temp_dist = sqrt(sum((p1-p2)**2 for p1, p2 in zip(pivot, target)))#计算目标点到邻近节点的Distance
if temp_dist < dist:
nearest = pivot #更新最近点
dist = temp_dist #更新最近距离
max_dist = dist #更新超球体的半径
print("输出数据:" , nearest, dist, max_dist)
# 检查另一个子结点对应的区域是否有更近的点
temp2 = travel(further_node, target, max_dist)
nodes_visited += temp2.nodes_visited
if temp2.nearest_dist < dist: # 如果另一个子结点内存在更近距离
nearest = temp2.nearest_point # 更新最近点
dist = temp2.nearest_dist # 更新最近距离
return result(nearest, dist, nodes_visited)
return travel(tree.root, point, float("inf")) # 从根节点开始递归
# 遍历kd树
#KDTree的前序遍历
def preorder(root):
print(root.dom_elt)
if root.left:
preorder(root.left)
if root.right:
preorder(root.right)
from math import sqrt
from collections import namedtuple
# 定义一个namedtuple,分别存放最近坐标点、最近距离和访问过的节点数
result = namedtuple("Result_tuple",
"nearest_point nearest_dist nodes_visited")
#搜索开始
def find_nearest(tree, point):
k = len(point)#数据维度
def travel(kd_node, target, max_dist):
if kd_node is None:
return result([0]*k, float("inf"), 0)#表示数据的无
nodes_visited = 1
s = kd_node.split #数据维度分隔
pivot = kd_node.dom_elt #切分根节点
if target[s] <= pivot[s]:
nearer_node = kd_node.left #下一个左结点为树根结点
further_node = kd_node.right #记录右节点
else: #右面更近
nearer_node = kd_node.right
further_node = kd_node.left
temp1 = travel(nearer_node, target, max_dist)
nearest = temp1.nearest_point# 得到叶子结点,此时为nearest
dist = temp1.nearest_dist #update distance
nodes_visited += temp1.nodes_visited
print("nodes_visited:", nodes_visited)
if dist < max_dist:
max_dist = dist
temp_dist = abs(pivot[s]-target[s])#计算球体与分隔超平面的距离
if max_dist < temp_dist:
return result(nearest, dist, nodes_visited)
# -------
#计算分隔点的欧式距离
temp_dist = sqrt(sum((p1-p2)**2 for p1, p2 in zip(pivot, target)))#计算目标点到邻近节点的Distance
if temp_dist < dist:
nearest = pivot #更新最近点
dist = temp_dist #更新最近距离
max_dist = dist #更新超球体的半径
print("输出数据:" , nearest, dist, max_dist)
# 检查另一个子结点对应的区域是否有更近的点
temp2 = travel(further_node, target, max_dist)
nodes_visited += temp2.nodes_visited
if temp2.nearest_dist < dist: # 如果另一个子结点内存在更近距离
nearest = temp2.nearest_point # 更新最近点
dist = temp2.nearest_dist # 更新最近距离
return result(nearest, dist, nodes_visited)
return travel(tree.root, point, float("inf")) # 从根节点开始递归
# 数据测试 data= [[2,3],[5,4],[9,6],[4,7],[8,1],[7,2]] kd=KdTree(data) preorder(kd.root)
结果:

# 导包
from time import clock
from random import random
# 产生一个k维随机向量,每维分量值在0~1之间
def random_point(k):
return [random() for _ in range(k)]
# 产生n个k维随机向量
def random_points(k, n):
return [random_point(k) for _ in range(n)]
# 输入数据进行测试 ret = find_nearest(kd, [3,4.5]) print (ret)
结果:
Result_tuple(nearest_point=[2, 3], nearest_dist=1.8027756377319946, nodes_visited=4)
N = 400000
t0 = clock()
kd2 = KdTree(random_points(3, N)) # 构建包含四十万个3维空间样本点的kd树
ret2 = find_nearest(kd2, [0.1,0.5,0.8]) # 四十万个样本点中寻找离目标最*的点
t1 = clock()
print ("time: ",t1-t0, "s")
print (ret2)
结果:
7.299844505209247 s
Result_tuple(nearest_point=[0.10505669630674175, 0.49542598718931097, 0.803316691954
3026], nearest_dist=0.007582362181450973, nodes_visited=53)
五、实验小结
通过本次实验,我理解了K-近邻算法原理,能实现算法K近邻算法,也掌握了常见的距离度量方法和K近邻树实现算法,并学会了针对特定应用场景及数据,能应用K近邻解决实际问题。