思维导图
图的定义
图(Graph)G由顶点集合V(G)和边集合E(G)构成。
n个顶点,编号:0~n-1;
无向图:在图G中,代表边的顶点对是无序的,用圆括号序偶表示无向边。

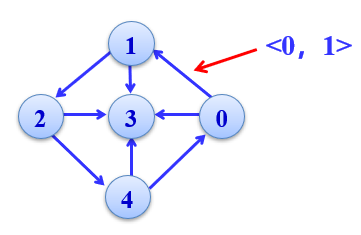
有向图:表示边的顶点对是有序的,用尖括号序偶表示有向边。
图的基本术语
端点和邻接点
无向图:若存在一条边(i,j)→顶点i和顶点j为端点,它们互为邻接点。
有向图:若存在一条边<i,j>→顶点i为起始端点(简称为起点),顶点j为终止端点(简称终点),它们互为邻接点。
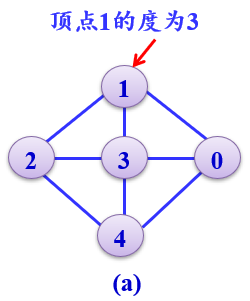
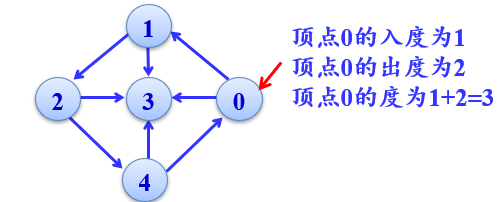
顶点的度、入度和出度
无向图:以顶点i为端点的边数称为该顶点的度。
有向图:以顶点i为终点的入边的数目,称为该顶点的入度。以顶点i为始点的出边的数目,称为该顶点的出度。一个顶点的入度与出度的和为该顶点的度。
若一个图中有n个顶点和e条边,每个顶点的度为di,则度之和为边的2倍。
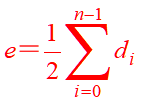
完全图
无向图:每两个顶点之间都存在着一条边,称为完全无向图, 包含有n(n-1)/2条边。
有向图:每两个顶点之间都存在着方向相反的两条边,称为完全有向图,包含有n(n-1)条边。

稠密图、稀疏图
当一个图接近完全图时,则称为稠密图。
相反,当一个图含有较少的边数(即当e<<n(n-1))时,则称为稀疏图。
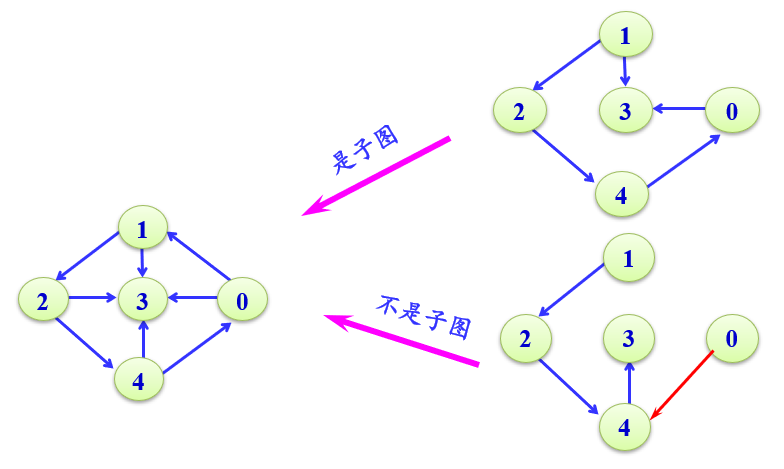
子图
设有两个图G=(V,E)和G'=(V',E'),若V'是V的子集,即V'∈V,且E'是E的子集,即E‘∈E,则称G'是G的子图。
路径和路径长度
在一个图G=(V,E)中,从顶点i到顶点j的一条路径(i,i1,i2,…,im,j)。所有的(ix,iy) ∈E(G),或者<ix,iy> ∈E(G),
路径长度:指一条路径上经过的边的数目。
简单路径:一条路径上除开始点和结束点可以相同外,其余顶点均不相同

回路或环
回路或环:若一条路径上的开始点与结束点为同一个顶点
简单回路或简单环:开始点与结束点相同。

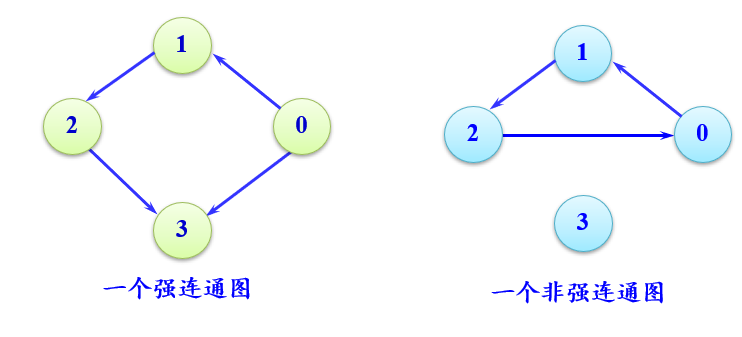
连通、连通图和连通分量
无向图:若从顶点i到顶点j有路径,则称顶点i和j是连通的。
若图中任意两个顶点都连通,则称为连通图,否则称为非连通图。
无向图G中的极大连通子图称为G的连通分量。显然,任何连通图的连通分量只有一个,即本身,而非连通图有多个连通分量。

有向图:若从顶点i到顶点j有路径,则称从顶点i到j是连通的。
若图G中的任意两个顶点i和j都连通,即从顶点i到j和从顶点j到i都存在路径,则称图G是强连通图。
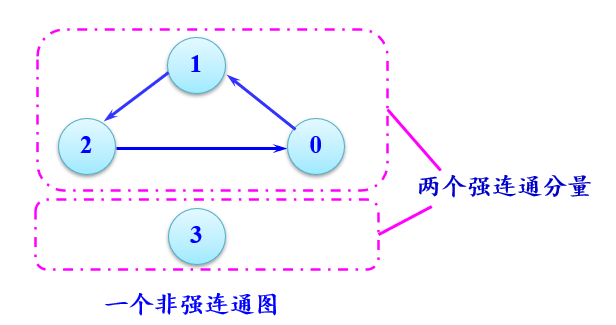
有向图G中的极大强连通子图称为G的强连通分量。显然,强连通图只有一个强连通分量,即本身。非强连通图有多个强连通分量。
在一个非强连通中找强连通分量的方法。
-
在图中找有向环。
-
扩展该有向环:如果某个顶点到该环中任一顶点有路径,并且该环中任一顶点到这个顶点也有路径,则加入这个顶点。
权和网
图中每一条边都可以附带有一个对应的数值,这种与边相关的数值称为权。权可以表示从一个顶点到另一个顶点的距离或花费的代价。
边上带有权的图称为带权图,也称作网。

图的存储结构
图的两种主要存储结构:邻接矩阵、邻接表。
存储每个顶点的信息、每条边的信息
邻接矩阵存储方法
邻接矩阵是表示顶点之间相邻关系的矩阵。设G=(V,E)是具有*n*(*n*>0)个顶点的图,顶点的编号依次为0~*n*-1。
G的邻接矩阵A是n阶方阵,其定义如下:
(1)如果G是无向图,则:
A[i][j]=1:若(i,j)∈E(G) 0:其他
(2)如果G是有向图,则:
A[i][j]=1:若<i,j>∈E(G) 0:其他
(3)如果G是带权无向图,则:
A[i][j]= wij:若i≠j且(i,j)∈E(G) 0:i=j ∞:其他
(4)如果G是带权有向图,则:
A[i][j]= wij:若i≠j且<i,j>∈E(G) 0:i=j∞:其他
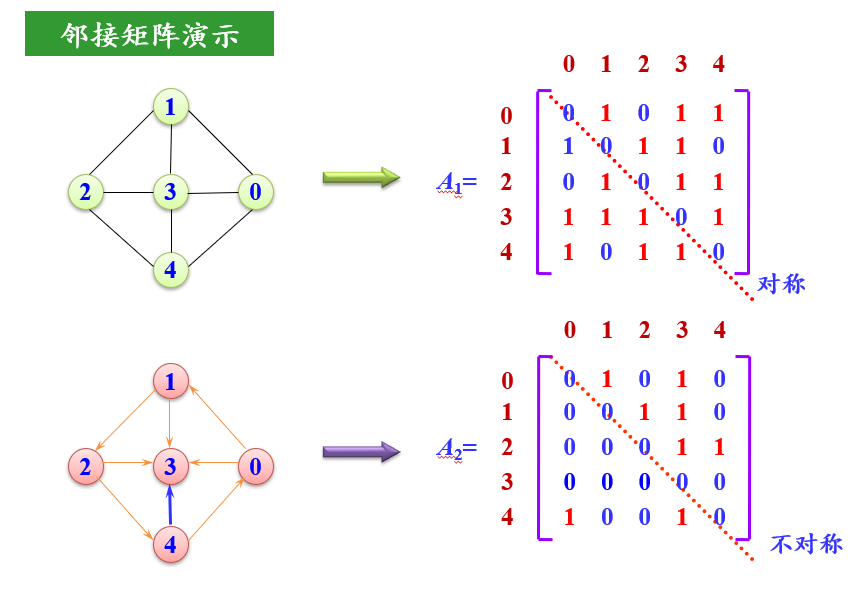
邻接矩阵的存储空间为O(n2)
邻接矩阵的主要特点:
-
一个图的邻接矩阵表示是唯一的。
-
特别适合于稠密图的存储。
图的邻接矩阵存储类型定义
#define MAXV <最大顶点个数>
typedef struct
{
int no; //顶点编号
InfoType info; //顶点其他信息
} VertexType;//声明顶点的类型
typedef struct //图的定义
{
int edges[MAXV][MAXV]; //邻接矩阵
int n,e; //顶点数,边数
VertexType vexs[MAXV]; //存放顶点信息
} MatGraph;//声明邻接矩阵的类型
邻接表存储方法
-
对图中每个顶点*i*建立一个单链表,将顶点*i*的所有邻接点链起来。
-
每个单链表上添加一个表头结点(表示顶点信息)。并将所有表头结点构成一个数组,下标为*i*的元素表示顶点*i*的表头结点。
图的邻接表存储方法是一种顺序分配与链式分配相结合的存储方法。

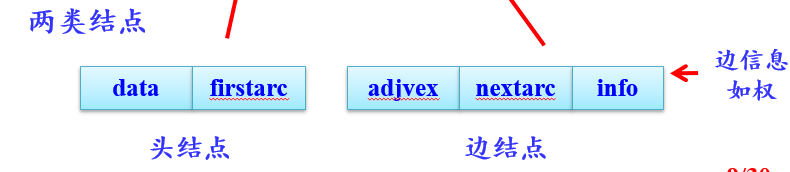
邻接表的特点如下:
- 邻接表表示不唯一。
- 特别适合于稀疏图存储。
- 邻接表的存储空间为O(*n+e*)
图的邻接表存储类型定义
typedef struct ANode
{
int adjvex; //该边的终点编号
struct ANode* nextarc; //指向下一条边的指针
InfoType info; //该边的权值等信息
} ArcNode;//声明边界点类型
typedef struct Vnode
{
Vertex data; //顶点信息
ArcNode* firstarc; //指向第一条边
} VNode;//声明邻接表头结点类型
typedef struct
{
VNode adjlist[MAXV]; //邻接表
int n,e; //图中顶点数n和边数e
} AdjGraph;//声明图邻接表类型
图基本运算算法设计(邻接表)
创建图
根据邻接矩阵数组A、顶点个数n和边数e来建立图的邻接表G(采用邻接表指针方式)。
void CreateAdj(AdjGraph*& G,int A[MAXV][MAXV],int n,int e)
//创建图的邻接表
{
int i, j;
ArcNode* p;
G = (AdjGraph*)malloc(sizeof(AdjGraph));
for (i = 0; i < n; i++) //给邻接表中所有头结点的指针域置初值
G->adjlist[i].firstarc = NULL;
for (i = 0; i < n; i++) //检查邻接矩阵中每个元素
for (j = n - 1; j >= 0; j--)
if (A[i][j] != 0 && A[i][j] != INF) //存在一条边
{
p = (ArcNode*)malloc(sizeof(ArcNode)); //创建一个结点p
p->adjvex = j; //存放邻接点
p->weight = A[i][j]; //存放权
p->nextarc = G->adjlist[i].firstarc; //采用头插法插入结点p
G->adjlist[i].firstarc = p;
}
G->n = n; G->e = n;
}
输出图
void CreateAdj(AdjGraph*& G,int A[MAXV][MAXV],int n,int e)
//创建图的邻接表
{
int i, j;
ArcNode* p;
G = (AdjGraph*)malloc(sizeof(AdjGraph));
for (i = 0; i < n; i++) //给邻接表中所有头结点的指针域置初值
G->adjlist[i].firstarc = NULL;
for (i = 0; i < n; i++) //检查邻接矩阵中每个元素
for (j = n - 1; j >= 0; j--)
if (A[i][j] != 0 && A[i][j] != INF) //存在一条边
{
p = (ArcNode*)malloc(sizeof(ArcNode)); //创建一个结点p
p->adjvex = j; //存放邻接点
p->weight = A[i][j]; //存放权
p->nextarc = G->adjlist[i].firstarc; //采用头插法插入结点p
G->adjlist[i].firstarc = p;
}
G->n = n; G->e = n;
}
销毁图
void DestroyAdj(AdjGraph*& G) //销毁邻接表
{
int i; ArcNode* pre,* p;
for (i = 0; i < G->n; i++) //扫描所有的单链表
{
pre = G->adjlist[i].firstarc;//p指向第i个单链表的首结点
if (pre != NULL)
{
p = pre->nextarc;
while (p != NULL) //释放第i个单链表的所有边结点
{
free(pre);
pre = p; p = p->nextarc;
}
free(pre);
}
}
free(G); //释放头结点数组
}
将邻接矩阵转为邻接表
void MatToList(MatGraph g,AdjGraph*& G)
//将邻接矩阵g转换成邻接表G
{
int i,j;
ArcNode* p;
G = (AdjGraph*)malloc(sizeof(AdjGraph));
for (i = 0; i < g.n; i++) //将邻接表中所有头结点的指针域置初值
G->adjlist[i].firstarc = NULL;
for (i = 0; i < g.n; i++) //检查邻接矩阵中每个元素
for (j = g.n - 1; j >= 0; j--)
if (g.edges[i][j] != 0 && g.edges[i][j] != INF) //存在一条边
{
p = (ArcNode*)malloc(sizeof(ArcNode)); //建一个边结点p
p->adjvex = j; p->weight = g.edges[i][j];
p->nextarc = G->adjlist[i].firstarc; //采用头插法插入结点p
G->adjlist[i].firstarc = p;
}
G->n = g.n; G->e = g.e;
}
将邻接表转为邻接矩阵
void ListToMat(AdjGraph* G,MatGraph& g)
//将邻接表G转换成邻接矩阵g
{
int i;
ArcNode* p;
for (i = 0; i < G->n; i++) //扫描所有的单链表
{
p = G->adjlist[i].firstarc; //p指向第i个单链表的首结点
while (p != NULL) //扫描第i个单链表
{
g.edges[i][p->adjvex] = p->weight;
p = p->nextarc;
}
}
g.n = G->n; g.e = G->e;
}
图的遍历
访问图中所有的顶点,每个顶点仅被访问一次
深度优先搜索
深度优先遍历的过程体现出后进先出的特点:用栈或递归方式实现。

邻接表的DFS算法
void DFS(AdjGraph* G,int v)
{
ArcNode* p; int w;
visited[v] = 1; //置已访问标记
printf("%d ",v); //输出被访问顶点的编号
p = G->adjlist[v].firstarc; //p指向顶点v的第一条边的边头结点
while (p != NULL)
{
w = p->adjvex;
if (visited[w] == 0)
DFS(G,w); //若w顶点未访问,递归访问它
p = p->nextarc; //p指向顶点v的下一条边的边头结点
}
}
时间复杂度O(n+e)
广度优先搜索
广度优先搜索遍历体现先进先出的特点,用队列实现。

邻接表的BFS算法
void BFS(AdjGraph* G,int v)
{
int w, i;
ArcNode* p;
SqQueue* qu; //定义环形队列指针
InitQueue(qu); //初始化队列
int visited[MAXV]; //定义顶点访问标记数组
for (i = 0; i < G->n; i++)
visited[i] = 0; //访问标记数组初始化
printf("%2d",v); //输出被访问顶点的编号
visited[v] = 1; //置已访问标记
enQueue(qu,v);
while (!QueueEmpty(qu)) //队不空循环
{
deQueue(qu,w); //出队一个顶点w
p = G->adjlist[w].firstarc; //指向w的第一个邻接点
while (p != NULL) //查找w的所有邻接点
{
if (visited[p->adjvex] == 0) //若当前邻接点未被访问
{
printf("%2d",p->adjvex); //访问该邻接点
visited[p->adjvex] = 1; //置已访问标记
enQueue(qu,p->adjvex); //该顶点进队
}
p = p->nextarc; //找下一个邻接点
}
}
printf("
");
}
时间复杂度O(n+e)
非连通图的遍历
l 无向连通图:调用一次DFS或BFS,能够访问到图中的所有顶点。
l 无向非连通图:调用一次DFS或BFS,只能访问到初始点所在连通分量中的所有顶点,不可能访问到其他连通分量中的顶点。可以分别遍历每个连通分量,才能够访问到图中的所有顶点。
最小生成树(带权无向图)
一个连通图的生成树是一个极小连通子图,它含有图中全部n个顶点和构成一棵树的(n-1)条边。
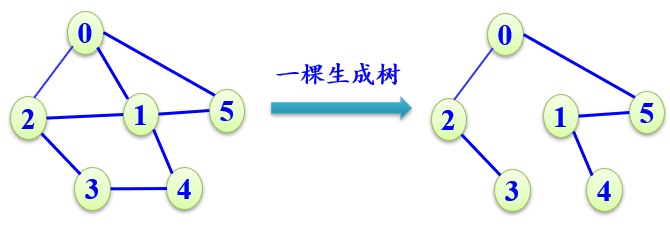
l 如果在一棵生成树上添加一条边,必定构成一个环。
l 一个连通图的生成树不一定是唯一的。
概念
l 对于带权连通图G(每条边上的权均为大于零的实数),可能有多棵不同生成树。
l 每棵生成树的所有边的权值之和可能不同。
l 其中权值之和最小的生成树称为图的最小生成树。
普里姆(prim)算法
l 从任意一个结点开始,将结点分成两类:已加入的,未加入的。
每次从未加入的结点中,找一个与已加入的结点之间边权最小值最小的结点。
然后将这个结点加入,并连上那条边权最小的边。
重复n-1次即可。
l 该算法的基本思想是从一个结点开始,不断加点
l 以无向带权图的邻接矩阵,自己对自己是0,邻接点为权值,非邻接点为∞。
l 局部最优 + 调整 = 全局最优
贪心算法→全局最优
l Prim算法更适合稠密图求最小生成树
l lowcost[] 和 closeset[],前者用来记录U集合和V集合的最小边,后者用来记录最小边的起始顶点
#define INF 32767 //INF表示∞
void Prim(MatGraph g,int v)
{
int lowcost[MAXV];
int min;
int closest[MAXV], i, j, k;
for (i = 0; i < g.n; i++) //给lowcost[]和closest[]置初值
{
lowcost[i] = g.edges[v][i]; //记录U集合的最小边
closest[i] = v;
}
for (i = 1; i < g.n; i++) //输出(n-1)条边
{
min = INF;
for (j = 0; j < g.n; j++) //在(V-U)中找出离U最近的顶点k
if (lowcost[j] != 0 && lowcost[j] < min)
{
min = lowcost[j];
k = j; //k记录最近顶点编号
}
printf(" 边(%d,%d)权为:%d
",closest[k],k,min);
lowcost[k] = 0; //标记k已经加入U
for (j = 0; j < g.n; j++) //修改数组lowcost和closest
修改U集合最小边
if (lowcost[j] != 0 && g.edges[k][j] < lowcost[j])
{
lowcost[j] = g.edges[k][j];
closest[j] = k; //若j为最小边,则它对应的顶点就是K
}
}
}
克鲁斯卡尔(Kruskal)算法
l 我们从最小边权的边开始,按边权从小到大依次加入,如果某次加边产生了环,就扔掉这条边,直到加入了n-1条边,即形成了一棵树。
l 该算法的基本思想是从小到大加入边,是个贪心算法。
typedef struct
{ int u; //边的起始顶点
int v; //边的终止顶点
int w; //边的权值
} Edge;
**Edge E[MAXV];**
void Kruskal(MatGraph g)
{
int i,j,u1,v1,sn1,sn2,k;
int vset[MAXV];
Edge E[MaxSize]; //存放所有边
k = 0; //E数组的下标从0开始计
for (i = 0; i < g.n; i++) //由g产生的边集E
for (j = 0; j < g.n; j++)
if (g.edges[i][j] != 0 && g.edges[i][j] != INF)
{
E[k].u = i; E[k].v = j; E[k].w = g.edges[i][j];
k++;
}
InsertSort(E,g.e); //用直接插入排序对E数组按权值递增排序
for (i = 0; i < g.n; i++) //初始化辅助数组:i对应的v[i]属于不同集合
vset[i] = i;
k = 1; //k表示当前构造生成树的第几条边,初值为1
j = 0; //E中边的下标,初值为0
while (k < g.n) //生成的边数小于n时循环
{
u1 = E[j].u; v1 = E[j].v; //取一条边的头尾顶点
sn1 = vset[u1];
sn2 = vset[v1]; //分别得到两个顶点所属的集合编号
if (sn1 != sn2) //两顶点属于不同的集合
{
printf(" (%d,%d):%d
",u1,v1,E[j].w);
k++; //生成边数增1
for (i = 0; i < g.n; i++) //两个集合统一编号
if (vset[i] == sn2) //集合编号为sn2的改为sn1
vset[i] = sn1;
}
j++; //扫描下一条边
}
}
上述算法不是最优的。
改进:堆排序、并查集
Kruskal算法的时间复杂度为O(elog2e)
Kruskal算法更适合稀疏图求最小生成树
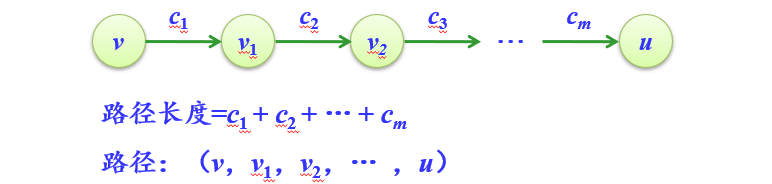
最短路径(带权有向图)
把一条路径(仅仅考虑简单路径)上所经边的权值之和定义为该路径的路径长度或称带权路径长度。
狄克斯特拉(Dijkstra)算法
主要思想是,将结点分成两个集合:已确定最短路长度的,未确定的。
一开始第一个集合里只有 S 。
然后重复这些操作:
-
对那些刚刚被加入第一个集合的结点的所有出边执行松弛操作。
-
从第二个集合中,选取一个最短路长度最小的结点,移到第一个集合中。
直到第二个集合为空,算法结束。
void Dijkstra(MatGraph g,int v)
{
int dist[MAXV],path[MAXV];
int s[MAXV];
int mindis, i, j, u;
for (i = 0; i < g.n; i++)
{
dist[i] = g.edges[v][i]; //距离初始化
s[i] = 0; //s[]置空
if (g.edges[v][i] < INF) //路径初始化
path[i] = v; //顶点v到i有边时
else
path[i] = -1; //顶点v到i没边时
}
s[v] = 1; //源点v放入S中
for (i = 0; i < g.n; i++) //循环n-1次
{
mindis = INF;
for (j = 0; j < g.n; j++)
if (s[j] == 0 && dist[j] < mindis)
{
u = j;
mindis = dist[j];
}
s[u] = 1; //顶点u加入S中
for (j = 0; j < g.n; j++) //修改不在s中的顶点的距离
if (s[j] == 0)
if (g.edges[u][j] < INF && dist[u] + g.edges[u][j] < dist[j])
{
dist[j] = dist[u] + g.edges[u][j];
path[j] = u;
}
}
Dispath(dist, path, s, g.n, v); //输出最短路径
}
Floyd算法
void Floyd(MatGraph g) //求每对顶点之间的最短路径
{
int A[MAXVEX][MAXVEX]; //建立A数组
int path[MAXVEX][MAXVEX]; //建立path数组
int i, j, k;
for (i = 0; i < g.n; i++)
for (j = 0; j < g.n; j++)
{
A[i][j] = g.edges[i][j];
if (i != j && g.edges[i][j] < INF)
path[i][j] = i; //i和j顶点之间有一条边时
else //i和j顶点之间没有一条边时
path[i][j] = -1;
}
for (k = 0; k < g.n; k++) //求Ak[i][j]
{
for (i = 0; i < g.n; i++)
for (j = 0; j < g.n; j++)
if (A[i][j] > A[i][k] + A[k][j]) //找到更短路径
{
A[i][j] = A[i][k] + A[k][j]; //修改路径长度
path[i][j] = path[k][j]; //修改最短路径为经过顶点k
}
}
}
拓扑排序
表头结点
typedef struct //表头结点类型
{
Vertex data; //顶点信息
int count; //存放顶点入度
ArcNode* firstarc; //指向第一条边
} VNode;
void TopSort(AdjGraph* G) //拓扑排序算法
{
int i,j;
int St[MAXV],top = -1; //栈St的指针为top
ArcNode* p;
for (i = 0; i < G->n; i++) //入度置初值0
G->adjlist[i].count = 0;
for (i = 0; i < G->n; i++) //求所有顶点的入度
{
p = G->adjlist[i].firstarc;
while (p != NULL)
{
G->adjlist[p->adjvex].count++;
p = p->nextarc;
}
}
for (i = 0; i < G->n; i++) //将入度为0的顶点进栈
if (G->adjlist[i].count == 0)
{
top++;
St[top] = i;
}
while (top > -1) //栈不空循环
{
i = St[top]; top--; //出栈一个顶点i
printf("%d ", i); //输出该顶点
p = G->adjlist[i].firstarc; //找第一个邻接点
while (p != NULL) //将顶点i的出边邻接点的入度减1
{
j = p->adjvex;
G->adjlist[j].count--;
if (G->adjlist[j].count == 0) //将入度为0的邻接点进栈
{
top++;
St[top] = j;
}
p = p->nextarc; //找下一个邻接点
}
}
}
关键路径
l 用一个带权有向图(DAG)描述工程的预计进度。
l 顶点表示事件,有向边表示活动,边e的权c(e)表示完成活动e所需的时间(比如天数)。
l 图中入度为0的顶点表示工程的开始事件(如开工仪式),出度为0的顶点表示工程结束事件。
从AOE网中源点到汇点的最长路径,具有最大长度的路径叫关键路径。
关键路径是由关键活动构成的,关键路径可能不唯一。
三、疑难问题及解决方案
#include<stdio.h>
#include<string.h>
#include<algorithm>
using namespace std;
const int maxn=550;
int n,m,k,vis[maxn],color[maxn],head[maxn],tot,t,viscolor[maxn],flag;
int mp[maxn][maxn];
void dfs(int u){
int i;
for(i=1;i<=n;i++){
if(mp[u][i]){
if(color[i]==color[u]){
flag=0;return ;
}
if(!vis[i]){
vis[i]=1;
dfs(i);
}
}
}
return ;
}
int main(){
int i,j;
scanf("%d%d%d",&n,&m,&k);
int u,v;
tot=0;
memset(mp,0,sizeof(mp));
while(m--){
scanf("%d%d",&u,&v);
mp[u][v]=mp[v][u]=1;
}
scanf("%d",&t);
while(t--){
int sum=0;
flag=1;
memset(viscolor,0,sizeof(viscolor));
for(i=1;i<=n;i++){
scanf("%d",&color[i]);
if(!viscolor[color[i]]){
sum++;
viscolor[color[i]]=1;
}
}
if(sum!=k){
printf("No
");
continue;
}
memset(vis,0,sizeof(vis));
for(i=1;i<=n;i++){
if(!vis[i]){
if(!flag) break;
vis[i]=1;
dfs(i);
}
}
if(!flag)
printf("No
");
else
printf("Yes
");
}
return 0;
}