写在前面:
上周微调一个文本检测模型seglink,将特征提取层进行冻结,只训练分类回归层,然而查看tensorboard发现里面有histogram显示模型各个参数分布,看了目前这个训练模型参数分布压根就看不懂,很想知道我的预训练模型的参数分布是怎么个情况,训练了一天了,模型的参数分布较预训练的模型参数有啥变化没有,怎么办呢?
利用tf.summary将模型参数分布在tensorboard可视化:
导入需要的库 设置模型文件夹路径
1 import TensorFlow as tf 2 from tensorflow.python import pywrap_tensorflow
model_dir="___"
定义可视化方法:
1、获取ckpt路径,这里的路径是checkpoint文件中的路径(ckpt文件夹中包括:checkpoint文件,index,meta,data四个文件)
code:
ckpt=tf.train.get_checkpoint_state(model_dir)
ckpt_path=ckpt.model_checkpoint_path
2、读取checkpoint 文件中模型的变量名和变量值
这里是使用get_variable_to_shape_map()获取了一个[key:name of variable value:the shape of variable]的list
code:
reader=pywrap_tensorflow.NewCheckpointReader(ckpt_path)
param_dict=reader.get_variable_to_shape_map()
3、开一个session,
code:
with tf.Session() as sess: validate_writer=tf.summary.FileWriter('./run') for key in param_dict: if(key.startwith('vgg')): vgg_summary=tf.summary.histogram(key,reader.get_tensor(key)) merge_summary=tf.summary.merge([vgg_summary])#这里可以添加其他需要merge的summary项,如果只有一个summary也可以不用merge, test_summary=sess.run(merge_summary) validate_writer.add_summary(test_summary)
tf.summary.FileWriter(event_dir_path)#event_dir_path为事件日志文件夹,运行程序之后会在该指定的文件夹中生产events文件。运行TensorFlow计算后,会将各类数据汇总记录进该日志文件,tensorboard会读取这些数据进行解析并生成数据可视化的web页面。
key.startwith('vgg')在param_dict字典中提取以vgg开头的key,并获取相关tensor以histogram的形式汇总
merge_summary=tf.summary.merge([.....])合并指定数据汇总
test_summary=sess.run(merge_summary)执行一步run,得到merge_summary,并将该summary
validate_writer.add_summary(test_summary)#将当前一步run得到的summary加入之前设置的validate_writer
附上summary示意图帮助理解,图片引用自CSDN网址:https://blog.csdn.net/hongxue8888/article/details/78610305
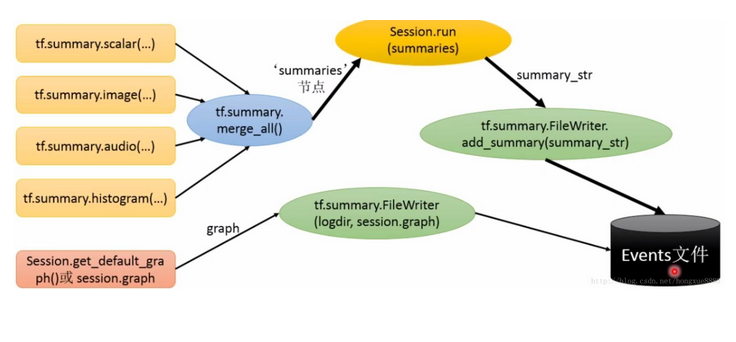
最后还要关闭writer
validate_writer.close()
运行代码之后,执行如下指令:
tensorboard --logdir="./run"#就是之前设置的events日志文件夹的路径
然后根据执行结果上的网址,打开浏览器即可观察模型参数分部情况:
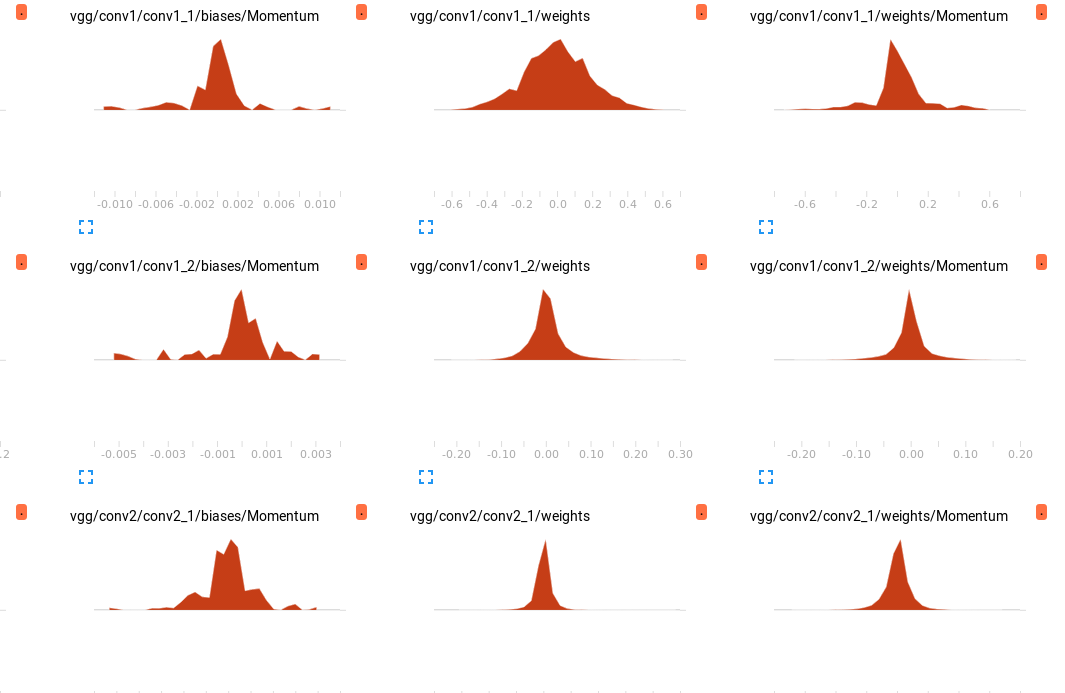
附一张参数分布图,具体怎么研究比较这个直方图,接下去再研究吧~
小白一枚,进步很慢,希望各路大神道友指教和批评~~~~