预定义的source和sink
大多都是在测试,开发验证中使用

自带的连接器
参考官网:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/connectors/

基于Apache Bahir的连接器
比如写redis: https://bahir.apache.org/docs/flink/current/flink-streaming-redis/

有时候在Flink 项目中访问 Redis 的方法都是自己进行的实现,推荐使用 Bahir 连接器。
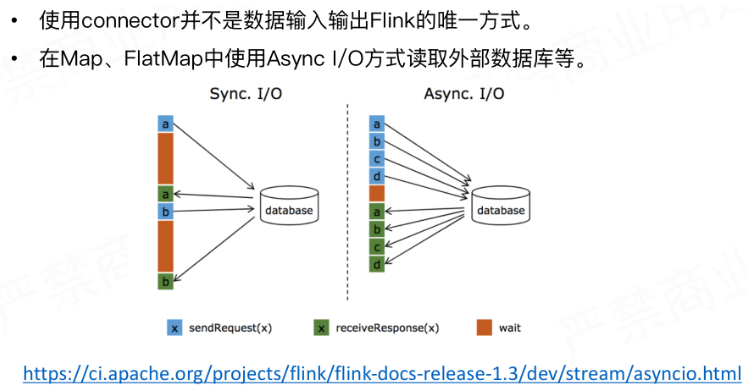
基于异步 I/O
异步 I/O 是 Flink 提供的非常底层的与外部系统交互的方式。
在流式系统中跟外部数据源做一个关联,比如跟mysql数据库中的一张表进行关联,即可在map或者flatmap中去跟数据库建立连接读取数据,,如果用同步IO的话会等待其响应的时间比较长,影响整个作业的吞吐。所以为了解决这种问题,而引入了异步IO的方式,以批量发送批量获取结果来提高吞吐,具体异步IO的实现原理可以通过下面的连接查看。
Flink kafka connector
Flink kafka consumer
1.构建consumer实例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //设置环境 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); env.enableCheckpointing(60*1000, CheckpointingMode.EXACTLY_ONCE); //设置kafka相关属性 Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); // properties.setProperty("zookeeper.connect", "localhost:2181");// only required for Kafka 0.8 properties.setProperty("group.id", "test"); FlinkKafkaConsumer010<String> myConsumer = new FlinkKafkaConsumer010<>("myTopic", new SimpleStringSchema(), properties); // new SimpleStringSchema():表示用什么样的方式来反序列化kafka中的二进制数据。这里按字符串的方式来反序列化 // new FlinkKafkaConsumer010:表示kafka版本为0.10.x // 如果kafka为0.8.x或者0.9.x 则使用FlinkKafkaConsumer08或者FlinkKafkaConsumer09 // 如果Kafka >= 1.0.0 则使用FlinkKafkaConsumer
2.反序列化数据
Flink Kafka Consumer需要知道怎么将kafka中的二进制数据转换为Java/Scala对象,我们在使用时候通过定义DeserializationSchema来指定如何反序列化数据,然后在处理每一条kafak message时候通过调用deserialize(byte[] message) 方法来进行反序列化。
常用的DeserializationSchema
-
SimpleStringSchema:按字符串的方式进行序列化和反序列化
-
TypeInformationSerializationSchema:基于flink的TypeInformation来构建schema
-
JsonDeserializationSchema:使用jackson反序列化json格式消息,并返回ObjectNode,通过objectNode.get("field").as(Int/String/...)()来访问字段
3.设置消费起始offset
// 从kafka最早的位置开始读取 myConsumer.setStartFromEarliest(); // 从kafka最新的数据开始读取 myConsumer.setStartFromLatest(); // 从时间戳>=1561281792000L的数据开始读取 myConsumer.setStartFromTimestamp(1561281792000L); // (默认配置)从kafka记录的group.id的位置开始记录,如果没有则根据auto.offset.reset设置 myConsumer.setStartFromGroupOffsets(); // 指定确切的offset位置 Map<KafkaTopicPartition, Long> specificStartOffsets = new HashMap<>(); specificStartOffsets.put(new KafkaTopicPartition("myTopic", 0), 23L); specificStartOffsets.put(new KafkaTopicPartition("myTopic", 1), 31L); specificStartOffsets.put(new KafkaTopicPartition("myTopic", 2), 43L); myConsumer.setStartFromSpecificOffsets(specificStartOffsets);
注意:作业故障从checkpoint自动恢复,以及手动做savepoint时,消费的位置从保存状态中恢复,与该配置无关
4.Topic和Partition动态发现
Partition discovery:
kafka 分区的增加在企业中很常见,在当前分区数不能满足以下几种情况时就需要新增分区数
-
流量增大,当前分区数无法支持大数据量的写入。
-
业务复杂,虽然写入正常,但是后端消费处理并行度不够。
默认情况下,分区发现是没有开启的,开启也很简单,只需要给参数flink.partition-discovery.interval-millis 赋值一个非负值即可,该非负值代表制检测的周期,是以毫秒为单位的。实现原理是内部有一个单独的线程定义检测kafka meta信息进行更新。新发现的分区从earliest的位置开始读取。 限制是动态分区发现一旦开启无法从 flink 1.3.x 以前应用的 savepoint 恢复。这种情况下,必须先用 flink 1.3.x 创建一个 savepoint,然后从该savepoint 恢复。
Topic discovery:
增加 topic 的形式来增加并行度和吞吐量。要识别新增的 topic,除了发现新增分区里说的配置 flink.partition-discovery.interval-millis 为 非负值,以外还要求我们在配置 topic 的时候以正则表达式的形式。
FlinkKafkaConsumer011<String> myConsumer = new FlinkKafkaConsumer011<>( java.util.regex.Pattern.compile("test-topic-[0-9]"), new SimpleStringSchema(), properties);
也即是以正则的形式指定要消费的 topic。
5.Commit Offset的方式
分两种情况:
1.checkpoint禁用
-
基于kafka客户端的auto commit定期提交offset
-
需要配置enable.auto.commit (or auto.commit.enable for Kafka 0.8) / auto.commit.interval.ms参数到consumer properties中。
2.checkpoint开启
-
offset自己在checkpoint state中管理和容错,提交kafka仅作为外部监视消费进度
-
通过setCommitOffsetsOnCheckpoints(boolean)方法控制checkpoint成功之后是否提交offset到kafka当中
6.Timestamp Extraction/Watermark生成
per kafka partition watermark
-
assignTimestampsAndWatermarks,每个partition一个assigner,watermark为多个partition对齐后值(木桶短板原理)
-
不在kafka source后生成watermark,会出现扔掉部分数据情况
Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); FlinkKafkaConsumer010<String> myConsumer = new FlinkKafkaConsumer010<>("topic", new SimpleStringSchema(), properties); myConsumer.assignTimestampsAndWatermarks(new CustomWatermarkEmitter()); DataStream<String> stream = env .addSource(myConsumer) .print();
Flink kafka Producer
1.构建FlinkKafkaProducer
FlinkKafkaProducer011<String> myProducer = new FlinkKafkaProducer011<String>( "localhost:9092", // broker list "my-topic", // target topic new SimpleStringSchema()); // serialization schema // versions 0.10+ allow attaching the records' event timestamp when writing them to Kafka; // this method is not available for earlier Kafka versions myProducer.setWriteTimestampToKafka(true); stream.addSink(myProducer);
代码中是对应kafka 0.11.x,其他版本构建与上面消费者基本一样。
2.Kafka Producer Partitioning Scheme
-
FlinkFixedPartitioner
默认情况下producer会使用FlinkFixedPartitioner,每个flink Kafka Producer 子任务就会写到一个kafka分区里.
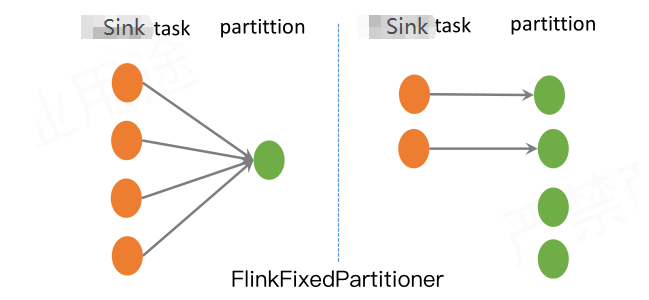
Sink task与kafka partition有一个对应关系:parallelInstanceId % partitions.length,如果sink task多于partition,比如4个sink task,1个partition,则4个sink task会均写入到那一个partition中,如果sink task小于 partition,比如2个sink,4个partition,则sink task会一一对应kafka partition。剩余2个partition不会有数据写入。
-
Partitioner设置为null
round-robin kafka partitioner 在写数据到kafka partition时,对数据做轮询插入,这样数据分布会比较均匀,但是有个缺点,就是每个sink task都会跟下游的每个kafka partition维持一个连接,这样会导致维持太多的连接
-
自定义partitioner
flink是支持自定义分区的,比如将一定规则的数据发送到指定kafka分区。需要继承FlinkKafkaPartitioner类,实现自定义的partitioner,注意partitioner必须是可序列化的。
3.Kafka Producer 容错
-
Kafka 0.8
在kafka 0.9之前,kafka没法保证至少一次或者精准一次的实现。
-
Kafka 0.9 and 0.10
在这两个版本中(FlinkKafkaProducer09和FlinkKafkaProducer010),如果开启了checkpoint,是可以实现
至少一次。除了开启checkpoint,还需要设置setLogFailuresOnly(boolean)和setFlushOnCheckpoint(boolean)
setLogFailuresOnly(boolean):默认false,表示在写失败时,是否只打印失败log
setFlushOnCheckpoint(boolean):默认true,checkpoint时保证数据写入kafka
如果要实现至少一次,需要配置:
setLogFailuresOnly(false)+setFlushOnCheckpoint(true)
-
Kafka 0.11 and newer
开启checkpoint,两阶段提交sink结合kafka事物,可以保证端到端的精准一次。
https://www.ververica.com/blog/end-to-end-exactly-once-processing-apache-flink-apache-kafka
Flink Kafka 代码示例
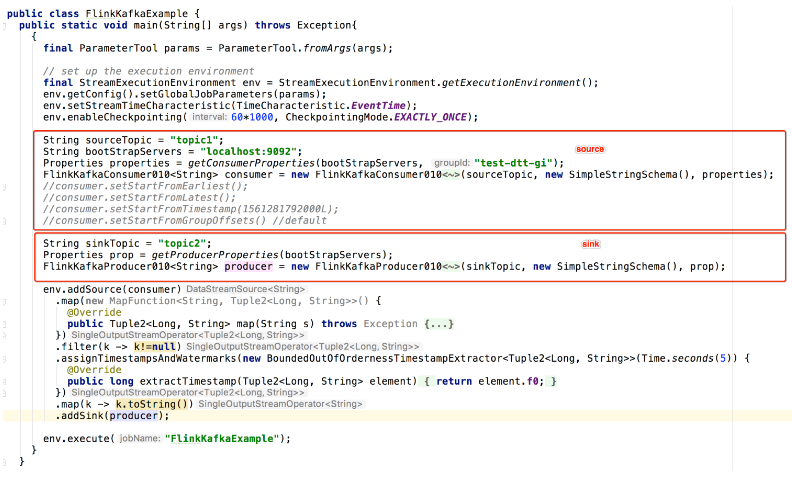
参考:flink-china 董亭亭 快手实时计算引擎团队负责人
参考:flink 官网