Lambda 架构
Lambda 架构由Storm的作者Nathan Marz提出,其设计目的在于提供一个能满足大数据系统关键特性的架构,包括高容错、低延迟、可扩展等。其整合离线计算与实时计算,融合不可变性、读写分离和复杂性隔离等原则,可集成Hadoop, Kafka, Spark,Storm等各类大数据组件。
Lambda 架构可分解为三层Layer,即Batch Layer, Real-Time(Speed) Layer和Serving Layer。
- Batch Layer : 存储数据集,在数据集上预先计算查询函数,并构建查询所对应的View。Batch Layer可以很好的处理离线数据,但有很多场景数据是不断实时生成且需要实时查询处理,对于这情况, Speed Layer更为适合。
- Speed Layer : Batch Layer处理的是全体数据集,而Speed Layer处理的是最近的增量数据流。Speed Layer为了效率,在接收到新的数据后会不断更新Real-time View,而Batch Layer是根据全体离线数据集直接得到Batch View。
- Serving Layer : Serving Layer用于合并Batch View和Real-time View中的结果数据集到最终数据集。

一个典型的Lambda架构如下,
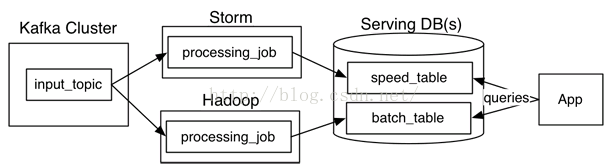
这种架构主要面向的场景是逻辑比较复杂同时又希望延迟比较低的异步处理程序,比如搜索引擎、推荐引擎等。
系统从一个流中读取被我们定义为不可变的数据,分别灌入实时系统如Storm和批处理系统如Hadoop,然后各自输出自己的结果,这些结果会在查询端进行合并。当然,这种系统也可有很多变种,比如上图中的Kafka也可替换成其他的分布式队列,Storm也可以替换成其他的流式计算引擎。
Kappa 架构
Kappa 架构是LinkedIn的Jay Kreps结合实际经验和个人体会,针对Lambda架构进行深度剖析,分析其优缺点并采用的替代方案。Lambda 架构的一个很明显的问题是需要维护两套分别跑在批处理和实时计算系统上面的代码,而且这两套代码得产出一模一样的结果。因此对于设计这类系统的人来讲,要面对的问题是:为什么我们不能改进流计算系统让它能处理这些问题?为什么不能让流系统来解决数据全量处理的问题?流计算天然的分布式特性注定其扩展性比较好,能否加大并发量来处理海量的历史数据?基于种种问题的考虑,Jay提出了Kappa这种替代方案。

那如何用流计算系统对全量数据进行重新计算,步骤如下:
- 用Kafka或类似的分布式队列保存数据,需要几天数据量就保存几天。
- 当需要全量计算时,重新起一个流计算实例,从头开始读取数据进行处理,并输出到一个结果存储中。
- 当新的实例完成后,停止老的流计算实例,并把老的一引起结果删除。
一个典型的Kappa架构如下,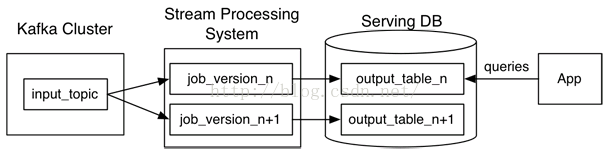
转载自https://blog.csdn.net/Post_Yuan/article/details/52241252