python3简明教程学习
基本概念
脚本文件:
脚本文件英文为Script。实际上脚本就是程序,一般都是由应用程序提供的编程语言。应用程序包括浏览器(javaScript、VBScript)、多媒体创作工具,应用程序的宏和创作系统的批处理语言也可以归入脚本之类。
脚本文件类似于DOS操作系统中的批处理文件,它可以将不同的命令组合起来,并按确定的顺序自动连续地执行。脚本文件是文本文件,用户可使用任一文本编辑器来创建脚本文件。
解释器:
解释器(英语:Interpreter),又译为直译器,是一种电脑程序,能够把高级编程语言一行一行直接转译运行。解释器不会一次把整个程序转译出来,只像一位“中间人”,每次运行程序时都要先转成另一种语言再作运行,因此解释器的程序运行速度比较缓慢。它每转译一行程序叙述就立刻运行,然后再转译下一行,再运行,如此不停地进行下去。
解释器
python是一个脚本语言,可以在python解释器中直接写代码或者将代码写到一个文件(脚本文件)然后执行这个文件。
可以用两种方式使用python语言:
- 在shell中输入python即可进入交互界面,交互界面中即可运行。
- 在vim编辑器中,创建一个.py的文件,并输入代码如下图所示

- 代码中的前两个字符`#!`称为shebang告诉shell使用python解释器执行下面的代码,同时需要为脚本文件添加可执行权限,最后执行文件即可。


模块
模块包含了可以复用的代码文件,包含了不同的函数定义,变量。模块文件通常以.py为扩展名,使用之前先需要导入它。
python基本的数据类型和变量
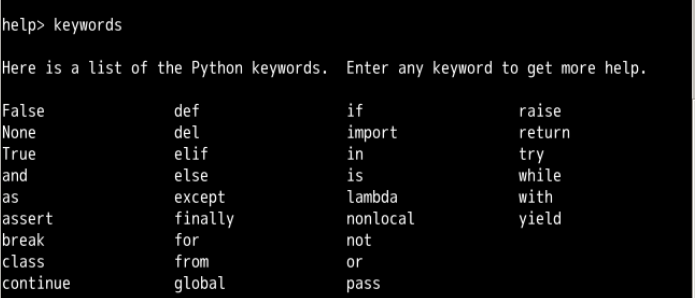
python的关键字必须完全按照下面来拼写
python不需要为变量指定数据类型,可以直接写出abc = 1同时python的字符串用单引号或双引号括起来即可。
从键盘读取输入
input()函数可以实现从键盘读取输入。
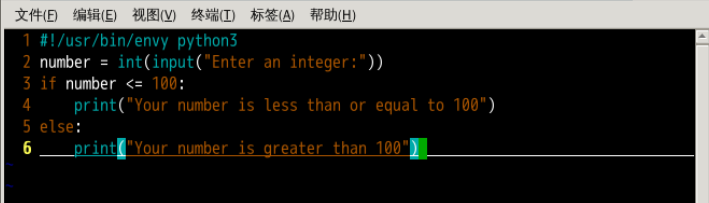
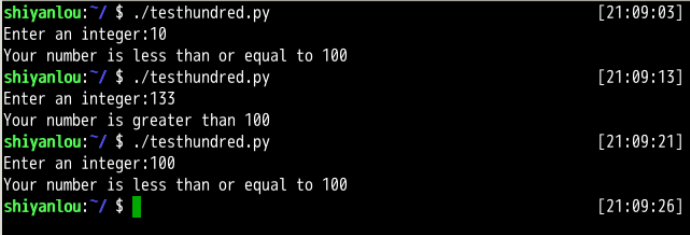
实现了从键盘读取一个数字并且检查这个数字是否小于100,运行结果如下图所示
计算投资:
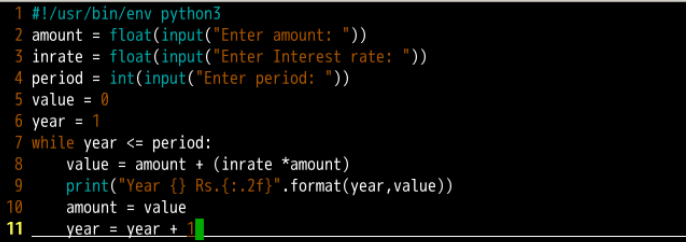
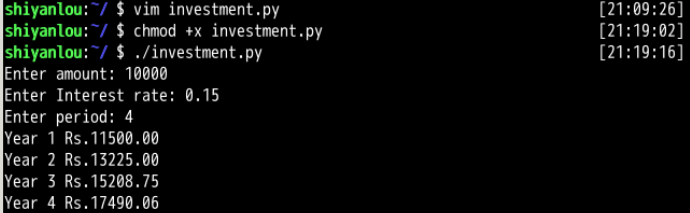
在看代码时不太能看懂输出语句的格式,对比执行后的结果
print("Year {} Rs. {:.2f}".format(year, value))
Year 1 Rs. 11400.00
可以看到,大括号和其中的字符会被替换成传入.format()中的变量的值,其中{:.2f}表示替换为2位精度的浮点数。
看不懂的地方涉及到函数str.format()是一个强大的格式化函数
通过位置
In [1]: '{0},{1}'.format('kzc',18)
Out[1]: 'kzc,18'
In [2]: '{},{}'.format('kzc',18)
Out[2]: 'kzc,18'
In [3]: '{1},{0},{1}'.format('kzc',18)
Out[3]: '18,kzc,18'
通过关键字参数:即大括号中包含对应的参数名
通过对象属性
class Person:
def __init__(self,name,age):
self.name,self.age = name,age
def __str__(self):
return 'This guy is {self.name},is {self.age} old'.format(self=self)
In [2]: str(Person('kzc',18))
Out[2]: 'This guy is kzc,is 18 old'
括号中的参数{:5d} {:7.2f}分别表示,替换为5个字节宽度的整数;替换为7个字节宽度并显示小数点后两位的浮点数。
单行定义多个变量或赋值
元组(truple)利用逗号创建元组,例如a , b = b, a在赋值语句的右边我们创建了一个元组,称为元组封装;赋值语句左边则是元组拆封。
>>> data = ("shiyanlou", "China", "Python")
>>> name, country, language = data
也就是说,data,(name, country, language)
是两个封装,而第二条语句对data进行了拆封。
运算符和表达式
运算符
- 数学操作符
+-/只要有一个操作符是浮点数,结果就会是浮点数。使用//将会返回商的整数部分。%求余运算符
计算月份和天数

divmod()函数
python divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
- 关系运算符与其他高级语言一致
- 逻辑运算符 and or not
逻辑运算符的优先级又低于关系运算符,在它们之中,not 具有最高的优先级,or 优先级最低,所以 A and not B or C 等于 (A and (notB)) or C
2 > 1 and not 3 > 5 or 4 这条语句可以看作是((2 > 1) and (not (3 > 5))) or 4 其中 2 > 1 为真 (not (3 > 5))也为真,故返回 True
程序理解
#!/usr/bin/env python3
sum = 0
for i in range(1, 11):
sum += 1.0 / i
print("{:2d} {:6.4f}".format(i , sum))

所涉及函数
python range()函数用法
range(start, stop[, step])
参数说明:
start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
所以在上面代码中的for循环,即i从1开始,到10结束,其中不包含11;每循环一次进行一次运算,同时打印i和sum的值。
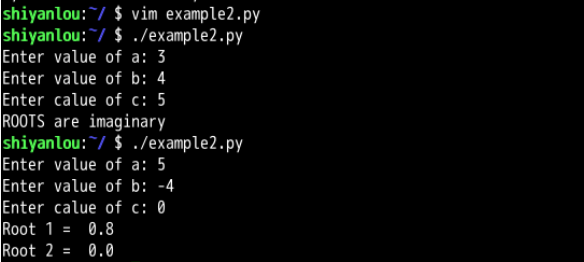
#!/usr/bin/env python3
import math
a = int(input("Enter value of a: "))
b = int(input("Enter value of b: "))
c = int(input("Enter value of c: "))
d = b * b - 4 * a * c
if d < 0:
print("ROOTS are imaginary")
else:
root1 = (-b + math.sqrt(d)) / (2 * a)
root2 = (-b - math.sqrt(d)) / (2 * a)
print("Root 1 = ", root1)
print("Root 2 = ", root2)
以上是一个求解二次方程的代码。
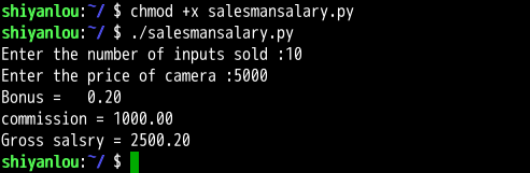
#!/usr/bin/env python3
basic_salary = 1500
bonus_rate = 200
commission_rate = 0.02
numberofcamera = int(input("Enter the number of inputs sold: "))
price = float(input("Enter the price of camera: "))
bonus = (bonus_rate * numberofcamera)
commission = (commission_rate * price * numberofcamera)
print("Bonus= {:6.2f}".format(bonus))
print("Commission = {:6.2f}".format(commission))
print("Gross salary = {:6.2f}".format(basic_salary + bonus + commission))
运行结果如下:
math模块调用的方法
- math.pi是一个模块变量不能当作函数调用使用
- math.sqrt() 是求平方根
if-else
语法格式:
if expression:
do this
else:
do this
或
if expression:
do this
elif experssion:
do this
else:
do this
注意if后面表达式的:不能少
if后面的表达式为真将执行缩进的所有行,要保证缩进的正确
while循环
语法格式
while condition:
statement1
statement2
要执行的语句必须以正确的缩进放在while语句下面,在表达式condition为真时执行
斐波那契数列实现
#!/usr/bin/env python3
a, b = 0, 1
while b < 100:
print(b, end=' ')
a, b = b, a + b
print()
对于语句a, b = b, a + b可以理解为Python会先对复制右边的表达式求值然后将值赋给左边的变量。即将b的值赋给a,a+b的值赋给b。
print()函数除了打印默认字符外,还会打印一个换行符,所以每次调用print()就会换一次行,利用end参数来替换换行符,如上代码中print(b, end=' ')
幂级数实现
#!/usr/bin/env python3
x = float(input("Enter the value of x: "))
n = term = num = 1
result = 1.0
while n <= 100:
term *= x / n
result += term
n += 1
if term < 0.0001:
break
print("No of Times= {} and Sum= {}".format(n, result))

乘法表
#!/usr/bin/env python3
i = 1
print("-" * 50)
while i < 11:
n = 1
while n <= 10:
print("{:5d}".format(i * n), end=' ')
n += 1
print()
i += 1
print("-" * 50)
以上代码是嵌套循环的代码,从其运行结果可以看出print("-" * 50)的作用

数据结构:列表
列表中的元素不必是同一类型,中间用逗号分隔。
a[256,1,23,'china','love']
其中每一位都有对应的下标,从0开始,可以利用a[4]对应‘love’使用负数索引,就会从尾部开始计数。
切片不会改变正在操作的列表,切片操作会返回其子列表,即一个新的列表副本。
例如: a[1:-2] 表示 [1,23]
a[:-2]则表示[256,1,23]

Python 中有关下标的集合都满足左闭右开原则,切片中也是如此,也就是说集合左边界值能取到,右边界值不能取到。
-
切片长度就是两个索引之差
-
[-1:-5]可以取到全部元素,但[-5:-1]取不到列表中的最后一个值。
-
切片的上边界大于下边界时,返回空列表;一个过大的索引值将被列表的实际长度所代替
-
可以检验某个值是否在列表中
'cool' ia a -
内建函数len()可以获得列表长度
-
列表允许嵌套
for循环
range()函数可以在for循环需要一个数值序列时使用,具体用法前面提到过。
在循环后面选择else语句,它将会在循环执行完毕后执行
数据结构
Python有许多内建的数据结构
其中包括列表、元组、
列表有关内容
-
列表a的建立:
a = [23, 45, 1, -3434, 43624356, 234] -
向列表添末尾加元素:
a.append(45)添加元素 45 到列表末尾。 -
向列表任何位置添加元素:
a.insert()方法a.insert(0,1)在列表0的位置添加元素1
-
列表计算指定值方法:count(s)会返回列表元素中s的数量
-
移除任意指定值:remove(s)将会移除在列表中的s值
-
删除指定位置的值:del()
-
翻转列表:reverse()
-
列表排序:sort()前提是列表的元素是可比较的
将列表用作栈和队列
-
pop(i)方法会将第i个元素出栈,例如a.pop(0)将第一个元素弹出列表
-
列表推导式为从序列中创建列表提供了一个简单的方法
- 列表推导式由包含一个表达式的中括号组成,表达式后面跟随一个 for 子句,之后可以有零或多个 for 或 if 子句,结果是一个列表。列表推导式也可以嵌套
squares = [x**2 for x in range(10)]
该语句组成的序列是[0,1,4,9,16,25,36,47,64,81][(x, y) for x in [1,2,3] for y in [3,1,4] if x != y]
[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
元组
元组是由数个逗号分隔的值所组成,可以对任何一个元组执行拆封操作并赋值给多个变量。
-
元组是不可变类型,元组内无法进行添加或删除任何值得操作。
-
要创建只有一个元素的元组,在值得后面跟一个逗号
a = 321,相当于(321,)
-
内建函数type()可以知道任意变量的数据类型;len()可以查询任意序列类型数据长度
集合
集合是一个无序不重复元素的集。基本功能有关系测试和消除重复元素。集合同时还支持数学运算。
-
大括号或set()函数可以用来创建集合。
-
a = set('abracadabra')得到的a集合是去重后的字母
字典
字典是无序键值对的集合,同一个字典内的键必须是互不相同的。键与值之间利用:分隔。用键来检索存储在字典中的值。
data
{'kushal': 'Fedora', 'Jace': 'Mac', 'kart_': 'Debian'}
查找字典中键对应的值
data['kart_']
'Debian'
删除字典中任意指定的键值对
del data['kushal']
查询指定关键字是否在字典中
'ShiYanLou' in data
遍历字典
items()方法
for x,y in data.items():
print("{} uses {}".format(x,y))
向字典中元素多次添加数据
dict.setdefault(key, default)
索引键,如果不存在将返回指定的default值
dict.get(key, default)
在便利列表的同时获得元素的索引值,使用enumerate()
for i, j in enumerate(['a', 'b', 'c']):
此时,列表的索引值将会存放在变量i中
字典中的键必须是不可变类型,比如列表就不能作为键。
输入学生的三科成绩计算是否通过考试
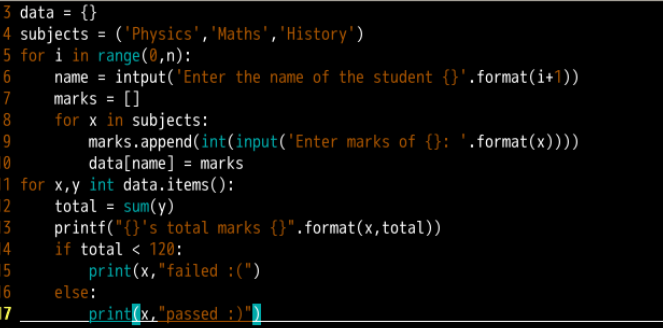
运行结果

代码分析
建立的data字典以学生的姓名作为键,对应的列表中包含的三门成绩作为对应学生的成绩,也就是字典的值。data[name] = marks就是一个创建字典的过程,将对应的列表作为值与姓名形成键值对。3
字符串
当输入几行字符串并且希望行尾换行符自动包含到字符串中,使用三对引号"""....."""或'''....'''
字符串的内建方法
-
s.split() 分隔字符串
语法方法:
str.split(str="", num=string.count(str)).参数
str -- 分隔符,默认为所有的空字符,包括空格、换行( )、制表符( )等。
num -- 分割次数。默认为 -1, 即分隔所有。返回值
返回分割后的字符串列表。 -
title()返回字符串的标题版本,即单词首字母大写其余字母小写
-
upper() 返回字符串的全部大写版本
-
lower()返回字符串的全部小写版本
-
swapcase() 返回字符串大小写交换后的版本
-
isalnum() 检查所有字符是否只包含数字和字母
-
isal
-pha() 检查字符串是否只有字母 -
join() 使用指定字符连接多个字符串
"-".join("GNU/Linux is great".split())
'GNU/Linux-is-great' -
lstrip(chars)或rstrip(chars) 对字符串左或右剥离
-
find()可以找到字符串中第一个匹配的字符串
检查回文数
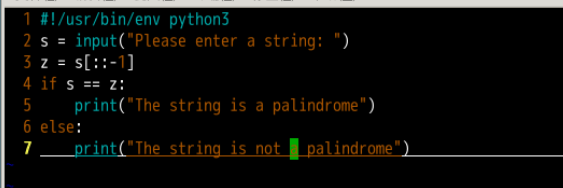
将字符串倒序的方式 z = s[::-1]
这是前面提到的切片的方法,可以对列表、元组等使用。
假如 a = (1,2,3,4,5)
那么 a[:] a[::] 都代表(1,2,3,4,5)使用默认值a[0:len(a):1]
前面提到过a[0:2]表示a(1,2)
在本题中a[::-1]表示步长为负数,从序列的最后一个元素开始切片,即倒序

函数
定义一个函数
使用关键字def定义函数
def 函数名(参数):
语句1
语句2
将回文判断写成一个函数
#!/usr/bin/env python3
def palindrome(s):
return s == s[::-1]
if __name__ == '__main__':
s = input("Enter a string: ")
if palindrome(s):
print("Yay a palindrome")
else:
print("Oh no, not a palindrome")
在这里很疑惑 name == 'main' 的作用是什么,参考一篇博客,明白__name__是函数的内置变量,详细参考博客https://blog.csdn.net/xyisv/article/details/78069129
局域或全局变量
在函数中创建的变量是局域变量,只在函数中可用,函数完成时销毁。同样在函数中,变量出现在表达式等号之前,就会被当做局部变量。
使用global关键字,对函数中的a标志为全局变量,让函数内部使用全局变量a,那么整个程序中出现a都将是一样的。
默认参数值
函数参数变量可以有默认值,如果对指定的参数变量没有给出任何值,则会赋其任意值。
def test(a , b=-99):
if a > b:
return True
else:
return False
需要注意的是:
- 具有默认值的参数后面不能再有普通参数
高阶函数
高阶函数或仿函数是可以接受函数作为参数的函数
map函数
它接受一个函数和一个序列(迭代器)作为输入,然后对序列(迭代器)的每一个值应用这个函数,返回一个序列(迭代器),其包含应用函数后的结果。
lst = [1, 2, 3, 4, 5]
return num * num
print(list(map(square, lst)))
[1, 4, 9, 16, 25]
文件处理
文件打开
使用open()函数打开文件,需要两个参数,第一个是文件路径或文件名;第二是文件的打开方式
- r 只读 (默认模式)
- w 写入 删除文件内所有内容,打开文件进行写入
- a 追加 写入到文件中的数据添加到末尾
文件关闭
使用close()关闭文件
文件读取
read()方法一次性读取整个文件。
-
read()有一个可选参数size用来返回指定字符串长度,如果没有指定size或size为负数,会读取整个文件
-
readline()每次读取文件的一行
- readlines()读取所有行到一个列表中
文件写入
write()方法打开文件然后随便写入一些文本
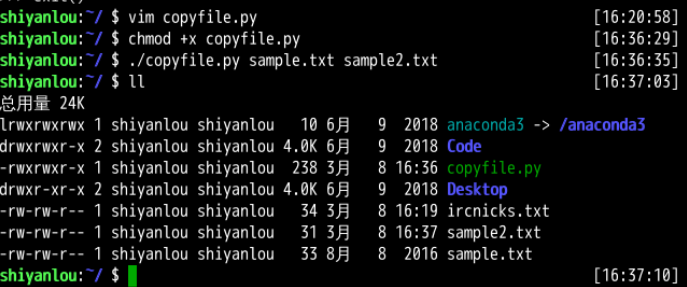
拷贝文本文件到另一个给定文本文件
#!/usr/bin/env python3
import sys
if len(sys.argv) < 3:
print("Wrong parameter")
print("./copyfile.py file1 file2")
sys.exit(1)
f1 = open(sys.argv[1])
s = f1.read()
f1.close()
f2 = open(sys.argv[2], 'w')
f2.write(s)
f2.close()
用到了sys模块的sys.argv函数,一开始不明的到底这个函数的功能是什么,参考了一篇博客,了解到sys.argv其实是外部命令与程序内部的桥梁,是一个列表,所以可以通过argv[]进行调用。
https://www.cnblogs.com/aland-1415/p/6613449.html
运行结果如图所示:
异常
在程序执行过程中发生的任何错误都是异常。每个异常显示一些相关的错误信息。
-
NameError访问一个未定义变量时会发生NameError异常
-
TypeError当操作或函数应用于不适当类型的对象时引发
处理异常
使用try...except快处理异常。
-
首先,执行 try 子句 (在 try 和 except 关键字之间的部分)。
-
如果没有异常发生,except 子句 在 try 语句执行完毕后就被忽略了。
-
如果在 try 子句执行过程中发生了异常,那么该子句其余的部分就会被忽略。
-
如果异常匹配于 except 关键字后面指定的异常类型,就执行对应的 except 子句。然后继续执行 try 语句之后的代码。
-
如果发生了一个异常,在 except 子句中没有与之匹配的分支,它就会传递到上一级 try 语句中。
-
如果最终仍找不到对应的处理语句,它就成为一个 未处理异常,终止程序运行,显示提示信息。
一个空的except()语句可以捕获任何异常。
抛出异常
使用raise()语句抛出异常
定义清理行为
try语句还有另一个可选的finally字句,在于定义任何情况下都一定要执行的功能。
不管有没有发生异常,finally 子句 在程序离开 try 后都一定会被执行。当 try 语句中发生了未被 except 捕获的异常(或者它发生在 except 或 else 子句中),在 finally 子句执行完后它会被重新抛出。
类
定义方式
class nameoftheclass(parent_class):
statement1
statement2
statement3
类的实例
x = MyClass()
以上类的实例用于创建一个空对象,创建一个有初始状态的类,需要用到方法 init()进行初始化。
继承
当一个类继承另一个类时,它将继承父类的所有功能(如变量和方法)。这有助于重用代码。
继承方式:
class Person(object):
def init(self,name):
def get_details(self):
class Student(Person):
class Teacher(Person):
有了init方法后,在创建类的对象时,不需要调用init方法,直接调用类的初始化方法即可。
person1 = Person('Sachin')
student1 = Student('Kushal', 'CSE', 2005)
teacher1 = Teacher('Prashad', ['C', 'C++'])
删除对象
del s 来删除对象
装饰器
你可能想要更精确的调整控制属性访问权限,你可以使用 @property 装饰器,@property 装饰器就是负责把一个方法变成属性调用的。
模块
模块是包括 Python 定义和声明的文件。文件名就是模块名加上 .py 后缀。__name__全局变量可以得到模块的模块名。
模块内的函数必须要用模块名来访问。
bars.hashbar(10)
bars.simplebar(10)
bars.starbar(10)
包
含有__init__.py文件的目录可以用来作为一个包,其中目录里的所有.py文件都是这个包的子模块
如果 init.py 文件内有一个名为 all 的列表,那么只有在列表内列出的名字将会被公开。
默认模块
-
os模块 提供了与操作系统相关的功能
- getuid() 函数返回当前进程的有效用户 id
- getpid() 函数返回当前进程的 id。getppid() 返回父进程的 id
- uname() 函数返回识别操作系统的不同信息,在 Linux 中它返回的详细信息可以从 uname -a 命令得到。
- getcwd() 函数返回当前工作目录。chdir(path) 则是更改当前目录到 path。
-
Requests模块
- 属于第三方模块,使用前需要安装
sudo apt-get update
sudo apt-get install python3-pip
sudo pip3 install requests- get()方法可以获取任意一个网页
从指定URL下载文件的程序
#!/usr/bin/env python3
import requests
def download(url):
# 检查 URL 是否存在
try:
req = requests.get(url)
except requests.exceptions.MissingSchema:
print('Invalid URL "{}"'.format(url))
return
# 检查是否成功访问了该网站
if req.status_code == 403:
print('You do not have the authority to access this page.')
return
filename = url.split('/')[-1]
with open(filename, 'w') as fobj:
fobj.write(req.content.decode('utf-8'))
print("Download over.")
if __name__ == '__main__':
url = input('Enter a URL: ')
download(url)
conllections模块
counter
counter是一个有助于hashable对象计数的dict子类。它是一个无序的集合,其中 hashable 对象的元素存储为字典的键,它们的计数存储为字典的值,计数可以为任意整数,包括零和负数。
- elements() 方法 依照计数重复重复元素相同次数,元素顺序是无序的。
- most_common() 方法返回最常见的元素及其计数,顺序为最常见到最少。
defaultdict
defaultdict() 第一个参数提供了 default_factory 属性的初始值,默认值为 None,default_factory 属性值将作为字典的默认数据类型。所有剩余的参数与字典的构造方法相同,包括关键字参数。
namedtuple
命名元组有助于对元组每个位置赋予意义,并且让我们的代码有更好的可读性和自文档性。你可以在任何使用元组地方使用命名元组。在例子中我们会创建一个命名元组以展示为元组每个位置保存信息。
迭代器、生成器、装饰器
迭代器
-
iter_(),返回迭代器对象自身。这用在 for 和 in 语句中。
-
next(),返回迭代器的下一个值。如果没有下一个值可以返回,那么应该抛出 StopIteration 异常。
生成器
生成器是更简单的创建迭代器的方法,这通过在函数中使用 yield 关键字完成。
def counter_generator(low, high):
while low <= high:
yield low
low += 1
for i in counter_generator(5,10):
print(i, end=' ')
5 6 7 8 9 10
在 While 循环中,每当执行到 yield 语句时,返回变量 low 的值并且生成器状态转为挂起。在下一次调用生成器时,生成器从之前冻结的地方恢复执行然后变量 low 的值增一。也就是说,在下一次执行生成器前,low的值不会改变。
虚拟Python环境virtualenv
安装两个不用的虚拟环境,并激活source virt1/bin/activate

安装redis这个Python模块
安装另一个虚拟环境,并安装不同版本的redis以满足不同的编程需要

测试
单元测试
在 Python 里我们有 unittest 这个模块来帮助我们进行单元测试。
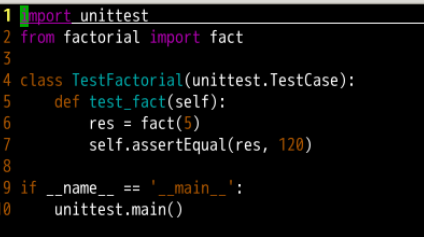
首先导入了 unittest 模块,然后测试我们需要测试的函数。
测试用例是通过子类化 unittest.TestCase 创建的。
覆盖测试率
测试覆盖率是找到代码库未经测试的部分的简单方法。它并不会告诉你的测试好不好。
项目结构
假设实验项目名为factorial创建/home/shiyanlou/factorial,将要创建的Python模块取名为myfact,创建目录/home/shiyanlou/factorial/myfact。主代码放在fact.py文件中,模块的__init.py__文件,将设定目录显示的文件。
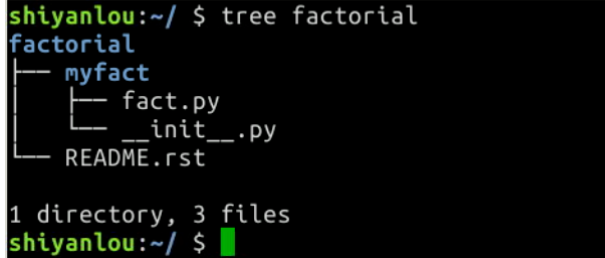
/home/shiyanlou/factorial/MANIFEST.in 文件,它用来在使用 sdist 命令的时候找出将成为项目源代码压缩包一部分的所有文件。
最终我们需要写一个 /home/shiyanlou/factorial/setup.py,用来创建源代码压缩包或安装软件。
要创建一个源文件发布版本,执行以下命令。
python3 setup.py sdist
我们能在 dist 目录下看到一个 tar 压缩包。执行下面的命令从源代码安装。
sudo python3 setup.py install
Flask框架基本使用
Flask 是一个 web 框架。也就是说 Flask 为你提供工具,库和技术来允许你构建一个 web 应用程序。这个 web 应用程序可以是一些 web 页面、博客、wiki、基于 web 的日历应用或商业网站。
Flask 属于微框架(micro-framework)这一类别,微架构通常是很小的不依赖于外部库的框架。这既有优点也有缺点,优点是框架很轻量,更新时依赖少,并且专注安全方面的 bug,缺点是,你不得不自己做更多的工作,或通过添加插件增加自己的依赖列表。
Flask 的依赖如下:
- Werkzeug 一个 WSGI 工具包
- jinja2 模板引擎
WSGI
Web服务器网关接口(Python Web Server Gateway Interface,缩写为WSGI)是为Python语言定义的Web服务器和Web应用程序或框架之间的一种简单而通用的接口。自从WSGI被开发出来以后,许多其它语言中也出现了类似接口。
flask框架使用
- templates 文件夹是存放模板的地方,
- static 文件夹存放 web 应用所需的静态文件(images, css, javascript)。
hello_flask.py 文件里编写如下代码:
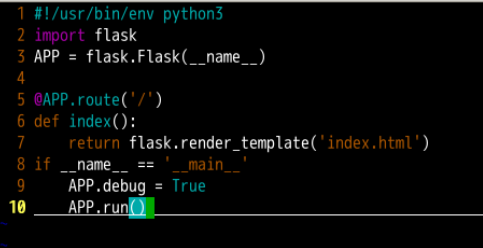
运行flask程序
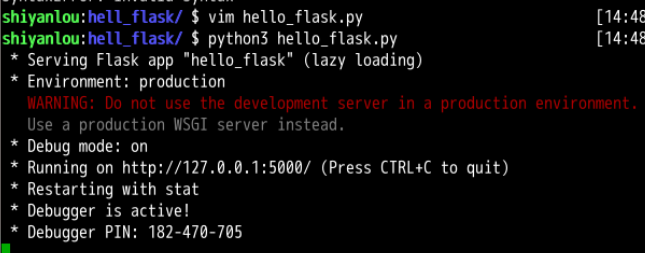
了解了微框架、WSGI、模板引擎等概念,学习使用 Flask 做一个 web 应用,在这个 web 应用中,我们使用了模板。而用户以正确的不同 URL访问服务器时,服务器返回不同的网页。
以上是这周在实验楼学习的关于Python3的相关知识,但是因为时间有限,很多内容还有待进一步深入,很多内容掌握的也不是很牢固,需要在以后的学习实践中不断巩固深入。