Hive:
hive不支持更改数据的操作,Hive基于Hadoop上运行,数据存储在HDFS上。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop
上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop
中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉
MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer
无法完成的复杂的分析工作。
参考:http://www.cstor.cn/textdetail_7444.html Hive:基于hadoop的数据仓库工具
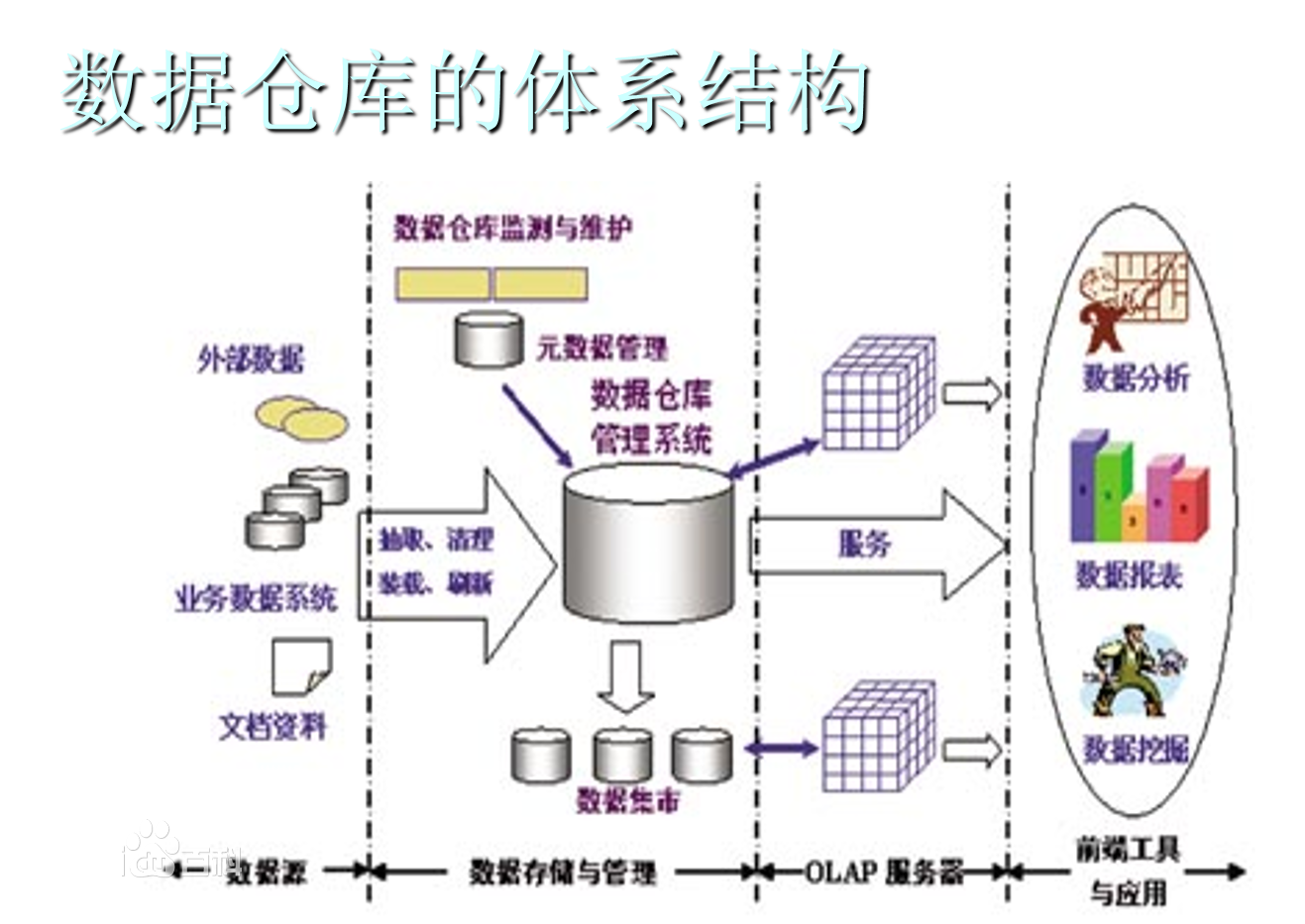
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
数据仓库是一个过程而不是一个项目。
HDFS:
HDFS是GFS的一种实现,他的完整名字是分布式文件系统,类似于FAT32,NTFS,是一种文件格式,是底层的。
Hive与Hbase的数据一般都存储在HDFS上。hadoop HDFS为他们提供了高可靠性的底层存储支持。
Hbase是Hadoop database,即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS(关系型数据库)数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
Pig:
Pig的语言层包括一个叫做PigLatin的文本语言,Pig Latin是面向数据流的编程方式。Pig和Hive类似更侧重于数据的查询和分析,底层都是转化成MapReduce程序运行。
区别是Hive是类SQL的查询语言,要求数据存储于表中,而Pig是面向数据流的一个程序语言。

Pig
一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了。当初雅虎自己慢慢退出pig的维护之后将它开源贡献到开源社区由所有爱好者来维护。不过现在还是有些公司在用。:)
Pig是一种数据流语言,用来快速轻松的处理巨大的数据。
Pig包含两个部分:Pig Interface,Pig Latin。
Pig可以非常方便的处理HDFS和HBase的数据,和Hive一样,Pig可以非常高效的处理其需要做的,通过直接操作Pig查询可以节省大量的劳动和时间。当你想在你的数据上做一些转换,并且不想编写MapReduce jobs就可以用Pig.
Hive
不想用程序语言开发MapReduce的朋友比如DB们,熟悉SQL的朋友可以使用Hive开离线的进行数据处理与分析工作。
注意Hive现在适合在离线下进行数据的操作,就是说不适合在挂在真实的生产环境中进行实时的在线查询或操作,因为一个字“慢”。相反起源于FaceBook,Hive在Hadoop中扮演数据仓库的角色。建立在Hadoop集群的最顶层,对存储在Hadoop群上的数据提供类SQL的接口进行操作。你可以用 HiveQL进行select,join,等等操作。
如果你有数据仓库的需求并且你擅长写SQL并且不想写MapReduce jobs就可以用Hive代替。
HBase
HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随即读写操作,HBase正是为此而出现。HBase以Google BigTable为蓝本,以键值对的形式存储。项目的目标就是快速在主机内数十亿行数据中定位所需的数据并访问它。
HBase是一个数据库,一个NoSql的数据库,像其他数据库一样提供随即读写功能,Hadoop不能满足实时需要,HBase正可以满足。如果你需要实时访问一些数据,就把它存入HBase。
你可以用Hadoop作为静态数据仓库,HBase作为数据存储,放那些进行一些操作会改变的数据。
Pig VS Hive
Hive更适合于数据仓库的任务,Hive主要用于静态的结构以及需要经常分析的工作。Hive与SQL相似促使 其成为Hadoop与其他BI工具结合的理想交集。
Pig赋予开发人员在大数据集领域更多的灵活性,并允许开发简洁的脚本用于转换数据流以便嵌入到较大的 应用程序。
Pig相比Hive相对轻量,它主要的优势是相比于直接使用Hadoop Java APIs可大幅削减代码量。正因为如此,Pig仍然是吸引大量的软件开发人员。
Hive和Pig都可以与HBase组合使用,Hive和Pig还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单
Hive VS HBase
Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。
想象你在操作RMDB数据库,如果是全表扫描,就用Hive+Hadoop,如果是索引访问,就用HBase+Hadoop 。
Hive query就是MapReduce jobs可以从5分钟到数小时不止,HBase是非常高效的,肯定比Hive高效的多。
参考: http://www.linuxidc.com/Linux/2014-03/98978.htm