一 TensorFlow安装
TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理。Tsnsor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow为张量从流图的一端流动到另一端的计算过程。TensorFlow是将复杂的数据结构传输至人工神经网络中进行分析和处理过程的系统。
下载和安装:https://blog.csdn.net/darlingwood2013/article/details/60322258
本文是将tensorflow在原生windows系统上安装, 采用anocanda的安装方式, 安装的是cpu版本(我的显卡不支持CUDA)
1.按照官网的指示:
pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow-1.0.0-cp35-cp35m-win_x86_64.whl

2 上一步安装显示我的平台不支持,尝试使用 conda install tensorflow安装

这里安装成功了,我是AMD的卡,可能对应的安装不一样!
3.确认tensorflow安装成功: 错误尝试:直接在cmd里面键入python,然后键入import tensorflow as tf

显然到此我们已经安装成功了,参考tensorflow官方文档,请上英文官网,中文社区似乎没有更新windows上的安装
二 基本使用
使用TensorFlow,你必须明白TensorFlow:
- 使用图(graph)来表示计算任务
- 在被称之为会话(Session)的上下文(context)中执行图
- 使用tensor表示数据
- 通过变量(Variable)维护状态
- 使用feed和fetch可以为任意的操作(arbitrary operation)赋值或者从中获取数据
1.综述
TensorFlow是一个编程系统,使用图来表示计算任务,图中的节点被称作op(operation的缩写),一个op获得0个或者多个Tensor,执行计算,产生0个或者多个Tensor,每个tensor是一个类型的多维数组。例如,你可以将一小组图像集表示为一个四维浮点数数字,这四个维度分别是[batch,height,width,channels]。一个TensorFlow图描述了计算的过程,为了进行计算,图必须在会话里启动,会话将图的op分发到诸如CPU或者GPU的设备上,同时提供执行op的方法,这些方法执行后,将产生的tensor返回,在python语言中,返回的tensor是numpy array对象,在C或者C++语言中,返回的tensor是tensorflow:Tensor实例。
2.计算图
TensorFlow 程序通常被组织成一个构建阶段和一个执行阶段. 在构建阶段, op 的执行步骤被描述成一个图, 在执行阶段, 使用会话执行执行图中的 op。例如, 通常在构建阶段创建一个图来表示训练神经网络, 然后在执行阶段反复执行图中的训练 op。
TensorFlow 支持 C, C++, Python 编程语言. 目前, TensorFlow 的 Python 库更加易用, 它提供了大量的辅助函数来简化构建图的工作, 这些函数尚未被C 和 C++ 库支持。三种语言的会话库 (session libraries) 是一致的。
3.构建图
构建图的第一步, 是创建源 op (source op), 源 op 不需要任何输入, 例如 常量 (Constant), 源 op 的输出被传递给其它 op 做运算。
Python 库中, op 构造器的返回值代表被构造出的 op 的输出, 这些返回值可以传递给其它 op 构造器作为输入。
TensorFlow Python 库有一个默认图 (default graph), op 构造器可以为其增加节点. 这个默认图对 许多程序来说已经足够用了. 阅读 Graph 类 文档来了解如何管理多个图。
4.示例程序
# -*- coding: utf-8 -*- """ Created on Sat Mar 31 16:54:02 2018 @author: Administrator """ #TensorFlow第一节 import tensorflow as tf ''' 构建阶段:op 的执行步骤被描述成一个图 ''' #创建一个常量op,产生一个1 x 2矩阵,这个op被称做一个节点,加到默认图中,构造器的返回值代表常量op的输出 matrix1 = tf.constant([[3.,3.]]) #创建另一个常量op。产生一个2 x 1的矩阵 matrix2 = tf.constant([[2.],[2.]]) #创建一个矩阵乘法 matmul op,把matrix1和matrix2作为输入 product = tf.matmul(matrix1,matrix2) ''' 默认图现在有三个节点,两个常量 constant() op和一个 matmul() op,wile真正进行矩阵相乘运算,并得到矩阵 乘法的结果,你必须载会话中启动这个图 ''' ''' 执行阶段:使用会话执行执行图中的 op. ''' #构造阶段完成后,才能启动图,启动图的第一步是创建一个Session对象,如果无任何创建函数,会话构造器将启动默认图 sess = tf.Session() ''' 调用sess的run()方法来执行矩阵乘法op,传入product作为该方法的参数,上面提到,product代表矩阵乘法op的输出 #传入它是向方法表明,我们希望取回矩阵乘法op的输出 整个执行过程是自动化的,会话负责传递op所需的全部输入,op通常是并发执行的 函数调用run(product)触发了图中三个op的执行 返回值result是一个numpy.ndarray对象 ''' result = sess.run(product) print(result) #[[ 12.]] #任务完毕,关闭会话,Session对象在使用完毕后需要关闭以释放资源,除了显示调用close()外,也可以使用with代码块 sess.close() ''' 在实现上, TensorFlow 将图形定义转换成分布式执行的操作, 以充分利用可用的计算资源(如 CPU 或 GPU). 一般你不需要显式指定使用 CPU 还是 GPU, TensorFlow 能自动检测. 如果检测到 GPU, TensorFlow 会尽 可能地利用找到的第一个 GPU 来执行操作. 如果机器上有超过一个可用的 GPU, 除第一个外的其它 GPU 默认是不参与计算的. 为了让 TensorFlow 使用 这些 GPU, 你必须将 op 明确指派给它们执行. with...Device 语句用来指派特定的 CPU 或 GPU 执行操作: ''' ''' 设备用字符串进行标识. 目前支持的设备包括: "/cpu:0": 机器的 CPU. "/gpu:0": 机器的第一个 GPU, 如果有的话. "/gpu:1": 机器的第二个 GPU, 以此类推. ''' with tf.Session() as sess: with tf.device("/cpu:0"): print(sess.run(product)) #[[ 12.]] ''' 交互式使用 文档中的python实例使用一个会话Seesion来启动图,并调用Session.run()方法执行操作 为了方便使用诸如IPython之类的Python交互环境,可以使用InteractiveSession替代Session类,使用Tensor.eval() 和Operation.run()方法来代替Session.run(),这样可以避免使用一个变量来持有会话 ''' #进入一个交互式TensorFlow会话 sess = tf.InteractiveSession() x = tf.Variable([1.0,2.0]) a = tf.constant([3.0,3.0]) #使用初始化器 initinalizer op的run()初始化x x.initializer.run() #增加一个减去sub op,从 x 减去 a,运行减去op,输出结果 sub = tf.subtract(x,a) print(sub.eval()) #[-2. -1.]
5.Tensor
TensorFlow程序使用tensor数据结构来代表所有的数据,计算图中,操作间传递的数据都是tensor,你可以把TensorFlow tensor看做一个n维的数组或者列表。一个tensor包含一个静态类型rank,和一个shape。具体参见Rank, Shape, 和 Type.。
6.变量
Variables 变量维护图执行过程中的状态信息. 下面的例子演示了如何使用变量实现一个简单的计数器.
#创建一个变量,初始化为标量0 state = tf.Variable(0,name = 'counter') #创建一个op,其作用是使state增1 one = tf.constant(1) new_value = tf.add(state,one) ''' assign()操作室图所描述的表达式的一部分,正如add()操作一样,所以在调用run()执行表达式之前,它并不会 正则执行赋值操作 通常会将一个统计模型中的参数表示为一组变量. 例如, 你可以将一个神经网络的权重作为某个变量存储在一个 tensor 中. 在训练过程中, 通过重复运行训练图, 更新这个 tensor. ''' update = tf.assign(state,new_value) #启动图后,变量必须先经过'初始化' op #首先必须增加一个 '初始化' op 到图中 init_op = tf.global_variables_initializer() #启动图,运行op with tf.Session() as sess: sess.run(init_op) #打印state初始值 print(sess.run(state)) #0 #运行op,更新state,并打印 for _ in range(3): sess.run(update) print(sess.run(state)) #1 2 3
7.Fetch
为了取回操作中的输出内容,可以在使用Seesion对象的run()调用执行图时,传入一些tensor,这些tensor会帮助你取回结果,在之前的例子里,我们只取回了单个节点state,但是你可以取回多个tensor。
in1 = tf.constant(1.0) in2 = tf.constant(2.0) in3 = tf.constant(3.0) intermed = tf.add(in1,in2) mul = tf.multiply(in2,in3) #需要获取多个tensor,在op的一次运行中一起获得。 with tf.Session() as sess: re = sess.run([intermed,mul]) print(re) #[3.0, 6.0]
8.Feed
上述示例在计算图中引入了 tensor, 以常量或变量的形式存储. TensorFlow 还提供了 feed 机制, 该机制 可以临时替代图中的任意操作中的tensor可以对图中任何操作提交补丁, 直接插入一个 tensor。
feed 使用一个 tensor 值临时替换一个操作的输出结果. 你可以提供 feed 数据作为 run() 调用的参数. feed 只在调用它的方法内有效, 方法结束,feed 就会消失. 最常见的用例是将某些特殊的操作指定为 "feed" 操作, 标记的方法是使用 tf.placeholder() 为这些操作创建占位符。
input1 = tf.placeholder(tf.float32) input2 = tf.placeholder(tf.float32) output = tf.multiply(input1, input2) #使用7替代input1,2替代input2,feed操作相当于设置一个占位符 with tf.Session() as sess: print(sess.run([output], feed_dict={input1:[7.], input2:[2.]})) #[array([ 14.], dtype=float32)]
三 案例
在使用TensorFlow的时候,需要注意以下几点;
1.就是 Session() 和 InteractiveSession() 的用法。后者用 Tensor.eval() 和 Operation.run() 来替代了 Session.run(). 其中更多的是用 Tensor.eval(),所有的表达式都可以看作是 Tensor。
2.另外,tf的表达式中所有的变量或者是常量都应该是 tf 的类型。
3.只要是声明了变量,就得用 sess.run(tf.global_variables_initializer()) 或者 x.initializer.run() 方法来初始化才能用。
例一
通过切记多元线性回归问题熟悉机器学习的一个流程
1.准备数据
2.构造模型(主要是设置目标函数)
3.求解模型(不需要考虑反向传播问题)
#二元线性回归案例 import numpy as np ''' 准备数据,并设置目标函数 ''' #产生测试数据 def genDate(numPoints,bias,variance): ''' :param numPoints : 实例个数 两维数据 :param bias : 偏向值 :param variance : 变化 返回得到的x和y数据 ''' #产生numPoints*2的零矩阵 x = np.zeros(shape = (numPoints,2)) #产生一维数组 y = np.zeros(shape = numPoints) for i in range(0,numPoints): #x赋值 x = [[1,0],[1,1],[1,2]...] x[i][0] = 1 x[i][1] = i #y赋值 正太分布 y[i] = i + np.random.normal(loc=bias, scale=variance, size=None) return np.array(x,dtype = 'float32').reshape(numPoints,2),np.array(y,dtype = 'float32').reshape(numPoints,1) #生成数据 x_data,y_data = genDate(100,25,3) print(x_data.shape,y_data.shape) #print(training_x,training_y) import matplotlib.pyplot as plt fig = plt.figure(1,figsize=(8,4)) #http://blog.csdn.net/eddy_zheng/article/details/48713449 #ax=plt.subplot(111,projection='3d') #创建一个三维的绘图工程 ax = Axes3D(fig) #坐标轴 ax.set_zlabel('Z') ax.set_ylabel('Y') ax.set_xlabel('X') ax.scatter(x_data[:,0],x_data[:,1],y_data,c='r',s=1) #绘制数据点 #构造二元线性回归模型 b = tf.Variable(1.0) w = tf.Variable(tf.ones([2,1])) y = tf.matmul(x_data,w) + b #设置均方差损失函数,在使用梯度下架法的时候学习率不能选择太多,不然会震荡,不会收敛 cost = tf.reduce_mean(tf.square(y - y_data)) #拟合效果更好 #选择绝对损失函数可以拟合很好 #cost = tf.reduce_mean(tf.abs(y - y_data)) #选择梯度下降的方法 传入学习率 optimizer = tf.train.GradientDescentOptimizer(0.0001) #学习率不能选择过大,不然会震荡 #迭代的目标,最小化损失函数 train = optimizer.minimize(cost) ''' #开始求解 ''' #初始化变量:tf的准备工作,主要声明了变量,就必须先初始化才可以使用 init = tf.global_variables_initializer() #设置tensorflow对GPU使用按需分配 config = tf.ConfigProto() config.gpu_options.allow_growth = True #使用会话执行图 with tf.Session(config=config) as sess: sess.run(init) #迭代,重复执行最下化损失函数这一步骤 for step in range(100000): sess.run(train) if step % 10000 == 0: print('迭代次数{0}:W->{1},b->{2},{3}'.format(step,sess.run(w),sess.run(b),sess.run(cost))) #保存最后结果 rw = sess.run(w) rb = sess.run(b) #计算预测的结果 X, Y = np.meshgrid(x_data[:,0], x_data[:,1]) Z = rb + rw[0]*X + rw[1]*Y #绘制数据点 ax.scatter(X,Y,Z,'b--',s=1)
当选择绝对损失函数,迭代一万次之后的拟合曲线图。

当选择均方差损失函数,迭代一万次之后的拟合曲线图。

从上面可以看到,选择均方差损失函数,拟合效果更好。
注意:在使用梯度下降法求解多元线性回归问题时,如果学习率设置太大,则会一直震荡,不会收敛,当我把学习率从0.0001改为0.1时,我们会发现运行结果如下
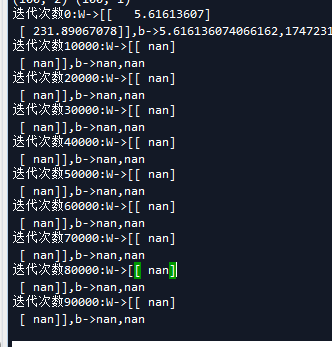
除此之外,我们也可以自己手写梯度下降法,或者使用sklearn库求解以上多元线性回归问题:
# -*- coding: utf-8 -*- """ Created on Thu Dec 21 22:06:59 2017 @author: zy """ #线性回归的例子 求解线性回归方程时采用的是梯度下降法 import numpy as np from sklearn import linear_model import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D #梯度下降法 def gradientDescent(x,y,theta,alpha,m,numIterations): ''' 损失函数取:L(θ)=1/2*m*Σ(h(xi) - yi)^2 :param x: traning set 训练集数据 :param y:输出 :param theta:估计的参数向量 依次为b,w1,w2.... :param alpha:梯度下降的步长 :param m:样本的总个数 :param numIterations : 迭代次数 返回最后迭代值 局部极小值 ''' #构建x的增广矩阵 temp = np.ones([x.shape[0],x.shape[1]+1]) temp[:,1:] = x x = temp xTrans = x.transpose() for i in range(0,numIterations): #hypothesis = X*θ hypothesis = np.dot(x,theta) #误差 error = hypothesis - y loss = hypothesis - y #损失函数值L(θ) #cost = np.sum(loss**2) / (2*m) #输出损失值 #print('Iteration %d | cost: %f'%(i,cost)) #梯度 x'*E gradient = np.dot(xTrans,loss)/m #更新参数 theta = theta - alpha * gradient return theta #产生测试数据 def genDate(numPoints,bias,variance): ''' :param numPoints : 实例个数 两维数据 :param bias : 偏向值 :param variance : 变化 返回得到的x和y数据 ''' #产生numPoints*2的零矩阵 x = np.zeros(shape = (numPoints,2)) #产生一维数组 y = np.zeros(shape = numPoints) for i in range(0,numPoints): #x赋值 x = [[1,0],[1,1],[1,2]...] x[i][0] = 1 x[i][1] = i #y赋值 正太分布 y[i] = i + np.random.normal(loc=bias, scale=variance, size=None) return np.array(x,dtype = 'float32'),np.array(y,dtype = 'float32') #生成测试数据 x,y = genDate(100,25,3) #print('x:',x) #print('y:',y) #获取行数和列数 m,n = np.shape(x) n = n+1 numIterations = 100000 alpha = 0.0005 #初始化参数值 theta = np.ones(n) #print(theta) #使用梯度下降法求解多元线性回归 theta = gradientDescent(x,y,theta,alpha,m,numIterations) print('theta',theta) #使用自带多元线性回归类库求解 可以看出下面求得与梯度下降的结果一样 #创建实例 regr = linear_model.LinearRegression() #开始训练算法 regr.fit(x,y) #打印权重系数 print('coefficients') print(regr.coef_) #打印截距 print('intercept') print(regr.intercept_) ''' 绘制结果 ''' fig = plt.figure(1,figsize=(8,4)) #http://blog.csdn.net/eddy_zheng/article/details/48713449 #ax=plt.subplot(111,projection='3d') #创建一个三维的绘图工程 ax = Axes3D(fig) #坐标轴 ax.set_zlabel('Z') ax.set_ylabel('Y') ax.set_xlabel('X') #将数据点分成三部分画,在颜色上有区分度 ax.scatter(x[:30,0],x[:30,1],y[:30],c='y',s=2) #绘制数据点 ax.scatter(x[30:70,0],x[30:70,1],y[30:70],c='r',s=2) ax.scatter(x[70:,0],x[70:,1],y[70:],c='g',s=2) #计算预测的结果 X, Y = np.meshgrid(x[:,0], x[:,1]) #print('X',X) #print('Y',Y) Z = theta[0] + theta[1]*X + theta[2]*Y #print('Z',Z) #绘制数据点 ax.scatter(X,Y,Z,'b--',s=1)
运行结果如下:
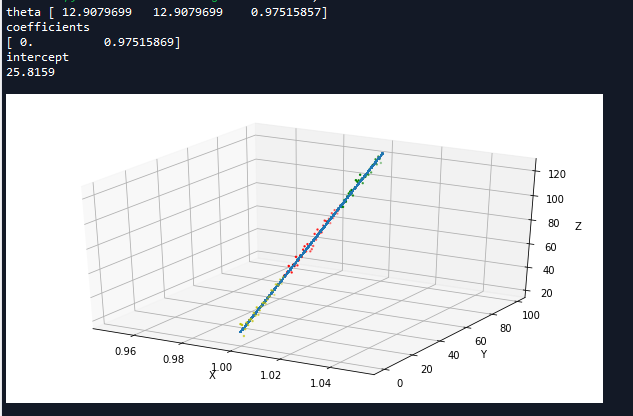
我们可以看到这个程序两种方法求解得到的的结果并不一样,但是从图形上看,拟合效果差不多,这主要是因为多元线性回归可能会有多个解,并且这多个解均能使均方差最小化。
例二:
使用tf来实现对一组数求和,再计算平均:
''' 使用tf来实现对一组数求和,再计算平均 ''' h_sum = tf.Variable(0.0,dtype=tf.float32) h_vec = tf.constant([1.0,2.0,3.0,4.0]) #把h_vec每个元素加到h_sum中,然后再除以10来计算平均值 #待添加的数 h_add = tf.placeholder(tf.float32) #添加之后的值 h_new = tf.add(h_sum,h_add) #更新h_new update = tf.assign(h_sum,h_new) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) #输出原始值 print('h_sum',sess.run(h_sum)) #h_sum 0.0 print('h_vec',sess.run(h_vec)) #h_vec [ 1. 2. 3. 4.] #循环添加 for i in range(4): sess.run(update,feed_dict={h_add:sess.run(h_vec[i])}) #输出每次求和之后的值 print('h_sum',sess.run(h_sum)) #h_sum 1.0 #h_sum 3.0 #h_sum 6.0 #h_sum 10.0 #计算平均值 print('The mean is:',sess.run(h_sum)/4.0) #The mean is: 2.5 #print('The mean is:',sess.run(sess.run(h_sum)/tf.constant(4.0))) #The mean is: 2.5 ''' 使用 tf.InteractiveSession() 来 求和 、平均 的操作呢? ''' sess = tf.InteractiveSession() #初始化变量 sess.run(tf.global_variables_initializer()) print('h_sum', h_sum.eval()) print("h_vec", h_vec.eval()) print("vec", h_vec[0].eval()) for i in range(4): update.eval(feed_dict={h_add: h_vec[i].eval()}) print('h_sum =', h_sum.eval()) sess.close()
参考文献
[2]http://wiki.jikexueyuan.com/project/tensorflow-zh/get_started/basic_usage.html