一、今日学习内容
爬虫是模拟人的浏览访问行为,进行数据的批量抓取。当抓取的数据量逐渐增大时,会给被访问的服务器造成很大的压力,甚至有可能崩溃。换句话就是说,服务器是不喜欢有人抓取自己的数据的。那么,网站方面就会针对这些爬虫者,采取一些反爬策略。
服务器第一种识别爬虫的方式就是通过检查连接的 useragent 来识别到底是浏览器访问,还是代码访问的。如果是代码访问的话,访问量增大时,服务器会直接封掉来访 IP。
那么应对这种初级的反爬机制,我们应该采取何种举措?
还是以前面创建好的爬虫为例。在进行访问时,我们在开发者环境下不仅可以找到 URL、Form Data,还可以在 Request headers 中构造浏览器的请求头,封装自己。服务器识别浏览器访问的方法就是判断 keyword 是否为 Request headers 下的 User-Agent,如图 22 所示。
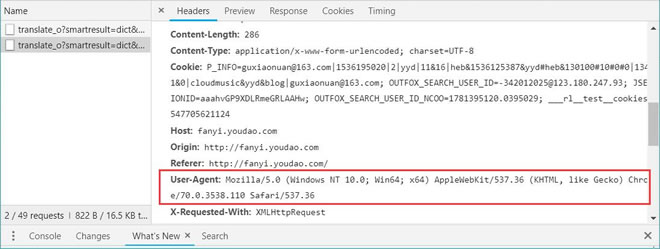
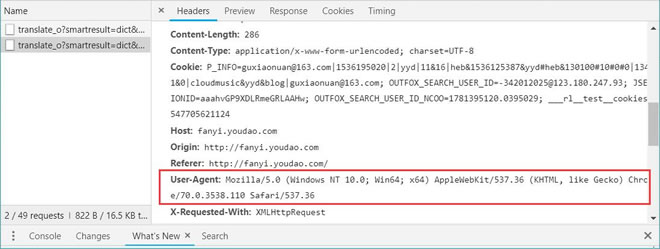
图 22
因此,我们只需要构造这个请求头的参数。创建请求头部信息即可,代码如下:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
response = request.get(url,headers=headers)
写到这里,很多读者会认为修改 User-Agent 很太简单。确实很简单,但是正常人1秒看一个图,而个爬虫1秒可以抓取好多张图,比如 1 秒抓取上百张图,那么服务器的压力必然会增大。也就是说,如果在一个 IP 下批量访问下载图片,这个行为不符合正常人类的行为,肯定要被封 IP。
其原理也很简单,就是统计每个IP的访问频率,该频率超过阈值,就会返回一个验证码,如果真的是用户访问的话,用户就会填写,然后继续访问,如果是代码访问的话,就会被封 IP。
这个问题的解决方案有两个,第一个就是常用的增设延时,每 3 秒钟抓取一次,代码如下:
import time
time.sleep(3)
但是,我们写爬虫的目的是为了高效批量抓取数据,这里设置 3 秒钟抓取一次,效率未免太低。其实,还有一个更重要的解决办法,那就是从本质上解决问题。
不管如何访问,服务器的目的就是查出哪些为代码访问,然后封锁 IP。解决办法:为避免被封 IP,在数据采集时经常会使用代理。当然,requests 也有相应的 proxies 属性。
首先,构建自己的代理 IP 池,将其以字典的形式赋值给 proxies,然后传输给 requests,代码如下:
- proxies={
- "http":"http://10.10.1.10:3128",
- "https":"http://10.10.1.10:1080",
- }
- response = requests.get(url, proxies=proxies)
二、遇到的问题
暂无
三、明日计划
继续python学习