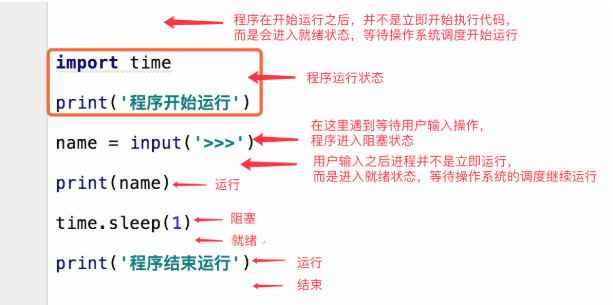
在理解进程之前我们先了解一下什么是进程的概念吧
以下就是我总结的一些基本的进程概念
进程就是正在运行的程序,它是操作系统中,资源分配的最小单位(通俗易懂点也就是电脑给程序分配的一定内存操作空间).
资源分配:分配的是cpu和内存等物理资源()
进程号是进程的唯一标识 (类似于身份证号,每个进程在运行的时候都有自己独特身份标识符)
同一个程序执行两次之后是两个进程(如python中我同时运行了两个py文件可以理解为我同时开了两个进程)
进程和进程之间的关系: 数据彼此隔离,通过socket通信
那么我们怎么获取当前的进程号呢?
·
在Linux下我们可也通过命令行来查看相关的进程
ps -aux 可以查看当前在Linux下所有的进程
ps -aux |grep pycharm 查看pycharm的进程号
那么我们如何通过命令行来关闭相应的进程呢??
kill -9 进程号
在Windows下面直接在任务管理器右键关闭即可
进程号的基本获取
os.getpid()是获取当前程序的
os.getppid() 是获取当前程序的父类进程号
以上就是我对进程了解
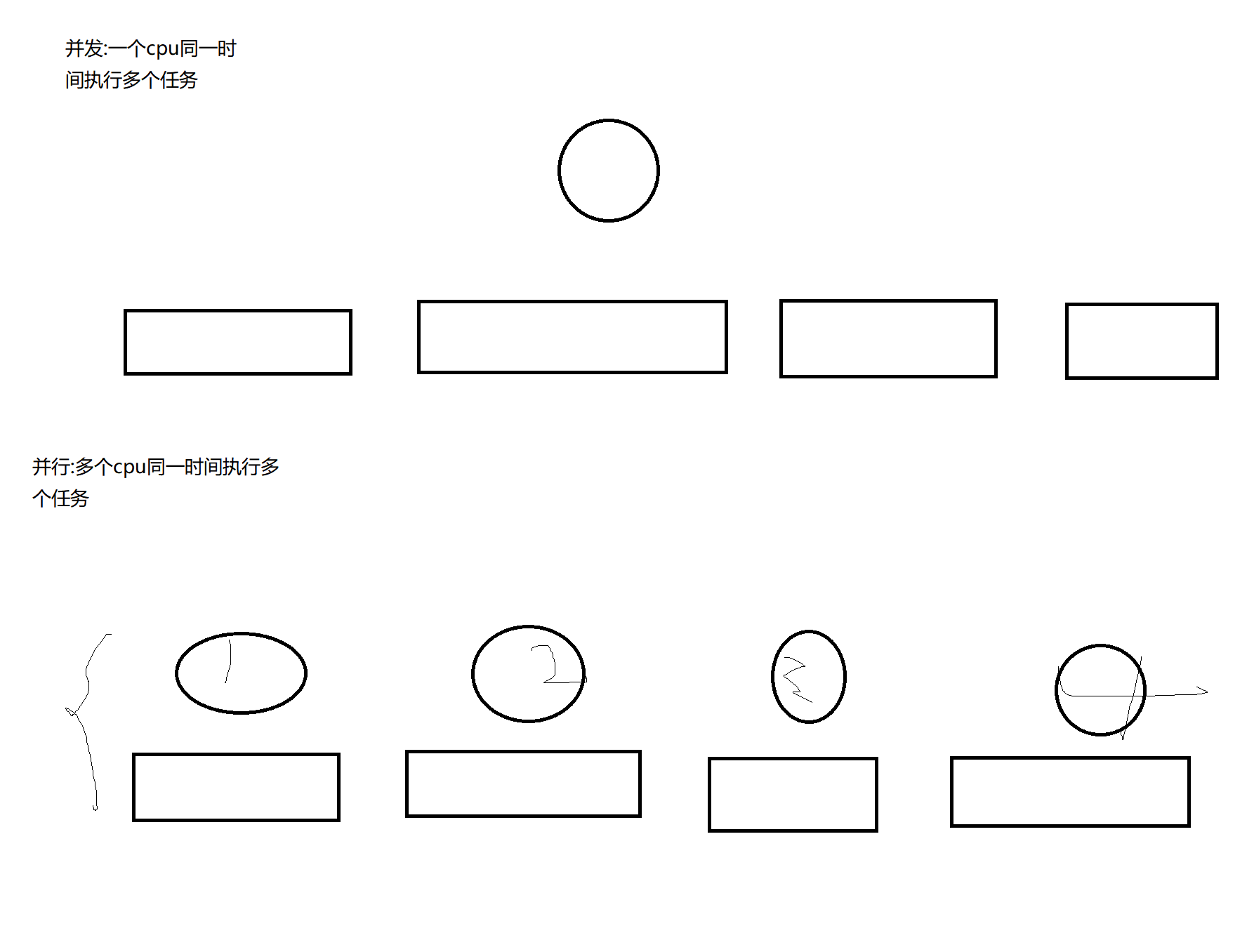
下面我介绍下什么是并发以及并行
并发:一个cpu同一时间不停执行多个程序 (python里面进程中没有用到多并行,如果同一时间在python中运行多个进程的话会导致CPU处理变慢)
并行:多个cpu同一时间不停执行多个程序
CPU进程的调度方法
# 先来先服务fcfs(first come first server):先来的先执行
# 短作业优先算法:分配的cpu多,先把短的算完
# 时间片轮转算法:每一个任务就执行一个时间片的时间.然后就执行其他的.
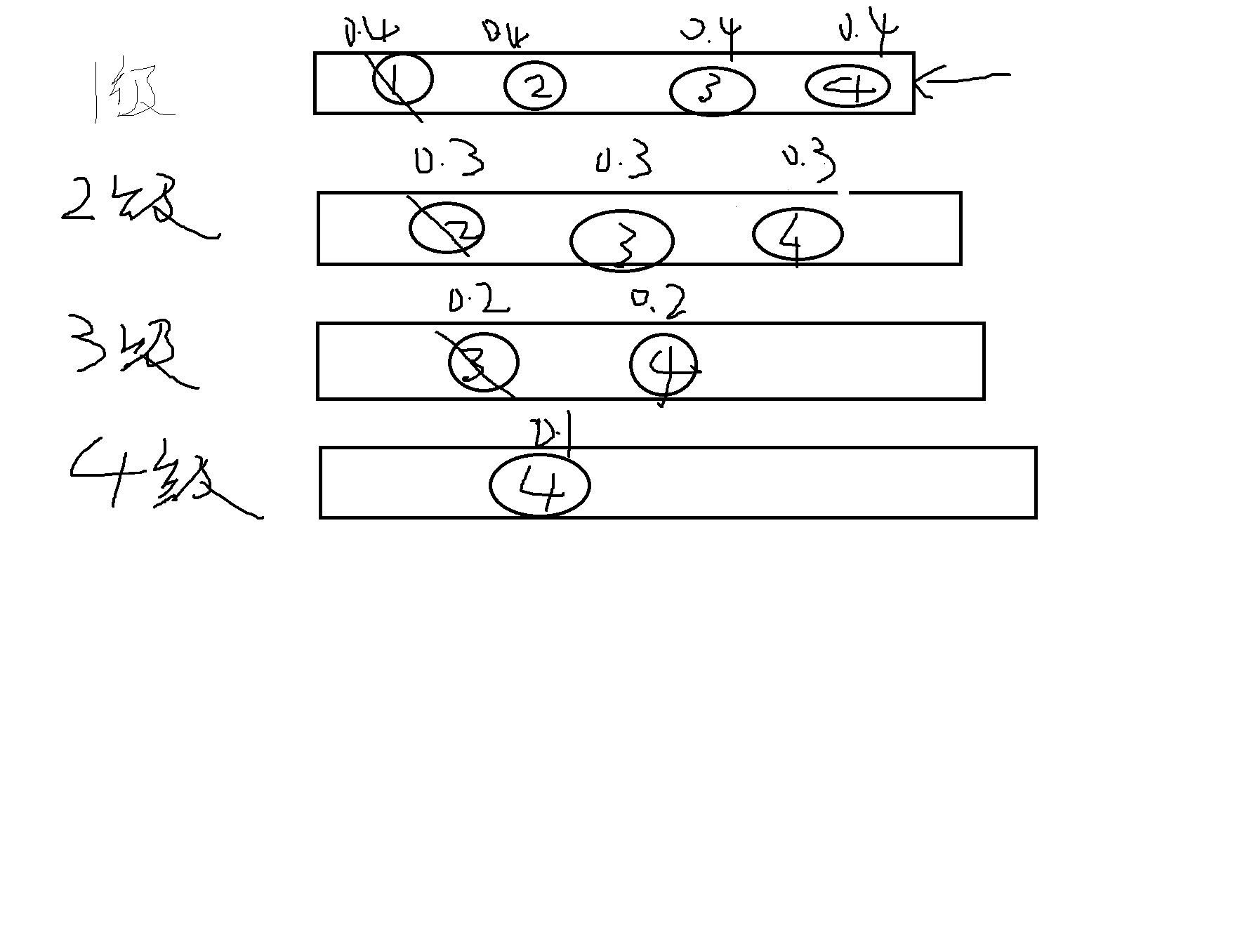
# 多级反馈队列算法
越是时间长的,cpu分配的资源越短,优先级靠后
越是时间短的,cpu分配的资源越多
多级反馈算法的额静态图
如何在pycharm里面创建一个进程呢?
首先我们要明白任何一个程序运行时计算机都需要为这个进程分配一定的资源,进程就是一个程序运行时的单位,默认一个程序只有一个进程,这个进程称为主进程
在当我们启动pycharm的时候就是一个进程,那么我们在这个软件下面所创建的任意一个py文件都是相对于pycharm的子进程那么下面我们通过代码实现以下进程的展示
###进程的查看 from multiprocessing import Process
import os
def func():
print("1.子进程id>>>%s , 2.父进程id>>>%s" % (os.getpid(),os.getppid()))
#每个进程号都是有系统直接随机分配的
if __name__ == "__main__":
print(os.getpid)#查看的是当前的主进程 print(os.getppid)#查看的是当前的进程的父id进程号
p = Process(target=func)
# 调用子进程
p.start()
由此我们可以得知所有的python文件都是一个子进程,在python文件里面创建的进程就是子进程
创建带有参数的子进程
方式一
# (2) 带有参数的函数任务
"""
Process 创建进程对象,参数要依靠args进行传递
args必须制定一个元素,参数和参数之间要用逗号进行分割
"""
def func(n):
for i in range(1,n+1):
print("1.子进程id>>>%s , 2.父进程id>>>%s" % (os.getpid(),os.getppid()))
if __name__ == "__main__":
n = 5
# 创建子进程
p = Process(target=func,args=(n,))
# 调用子进程
p.start()
for i in range(1,n+1):
print("*" * i)
# windows下开子进程必须在"main"下,因为在创建子进程时,会调用createprocess模块(会把父进程的内容导一遍,把父进程里面的数据完完整整的生成一份给子进程)
# 在linux系统下,不会有这个问题(两种系统造子进程的方式不一样)
p=Process(target=task,args=('子进程1',))
# 传参方式一:
# 因为导入的Process是一个类,所以需要实例化
# target:起的进程需要执行哪一段代码(这里指task)
# args:传参的方式,这里是一个元组(括号内需要加括号)
# p=Process(target=task,kwargs={'x':'任务1'})
# 传参方式二:
# kwargs:按照字典的方式进行传参,key是函数的参数'x',value是参数对应的值。
p.start()
# 给操作系统发信号,告诉操作系统有一个子进程要起来,让操作系统去申请内存空间,然后把父进程里面的数据拷贝一个给子进程,然后调用CPU来运行。
# 子进程被造出来后, 和父进程就没有任何关系,因为进程之间是隔离的
print('主进程')
方式二
from multiprocessing import Process import time class MyProcess(Process): def __init__(self,name): super().__init__() self.name=name def run(self): print('%s is runing' %self.name) time.sleep(3) print('%s is done' %self.name) if __name__ == '__main__': p=MyProcess('sudada') p.start() print('主进程') >>:主进程 >>:sudada is runing >>:sudada is done
2.5、进程对象的join方法 (主进程在等待子进程运行完毕之后,在运行下一行代码 ( 而不是主进程先运行代码,等待子进程运行结束 ) )
在单个子进程下join的表现
def func(): print("发送第一封邮件") if __name__ == "__main__": p = Process(target=func) p.start() # time.sleep(0.1) # 必须等待子进程执行完毕之后,在执行下面的代码 p.join() print("发送第二封邮件")
join加在需要执行的子程序之后,等待子进程执行完之后才会走主进程
join升级之多个子进程同事并发
print("发送%s个邮件" % (i)) if __name__ == "__main__": lst = [] for i in range(10): p = Process(target=func,args=(i,)) p.start() # 从结果上达到目的,但是严重损坏了性能,速度下降 # p.join() lst.append(p) # print(lst) for i in lst: i.join() print("主进程负责发送最后一封邮件 end ... ")
把每一个进程对象插入列表中,通过循环拿出一个个的进程对象
然后进程.join 执行阻塞,直到当前所有的子进程执行完毕,再去执行主进程最后的代码
如果直接把join放到for循环中,会导致进程创建时候,变成同步时候,严重影响性能速度;
默认程序在并发任务的时候,因为cpu调度策略,
不一定哪个进程先执行,哪个进程后执行,要参照哪个进程新变成就绪态,cpu就会优先执行
cpu遇到阻塞,就会立刻切换进程任务
主进程会在执行结束后,等所有子进程执行完毕,最后在关闭程序,释放资源
如果不等待子进程,子进程会在后台不停的占用资源,造成僵尸进程.
不方便对该进程进行管理,不知道该进程的来源,会导致维护困难;
在自定义的进程中程序也是有属于自己的name的默认第一个为
即当我有很多任务的时候我会把任务放到一个队列中,每个任务我给他 分配一定的时间处理,当我第一个队列中的某个任务执行完毕之后就会把剩余的任务丢到第二个队列中去,此时我的cup将对2级列表进行资源的分配,因为剩余的进程耗费的资源比较大那么此时我CPU分配给他们的资源也会更少依次类推,当我执行到最后一个队列时我此时的所存在的进程毫无疑问时所占的内存是最大的,那么如果我集中把资源全部分配到这个进程中的话势必会导致我其他的进程资源占用的少,从而导致我的CPU运行速度下降,所以在内存分配的静态图中我们可以得知内存占用越大的进程所获得的资源也就越少,从而提高了电脑的运行速度。
下面我们来看看进程执行是的状态图
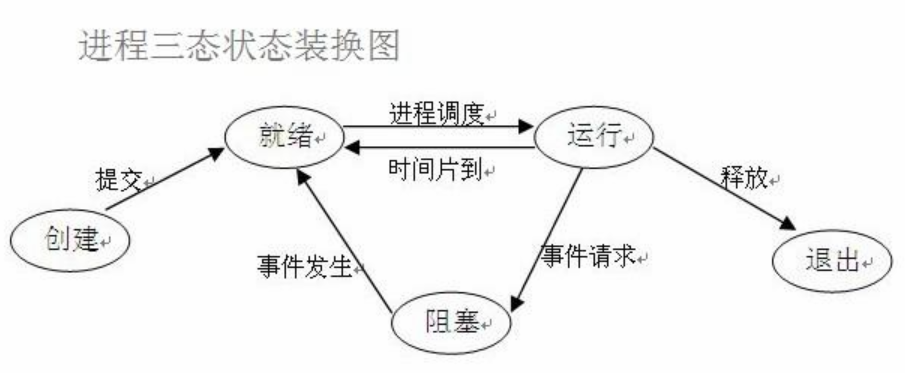
(1)就绪态 (ready)
只剩下CPU需要执行外,其他所有资源已分配完毕,称为就绪态
(2)执行(Running)状态
cup开始执行该进程时称为执行态(也可以称为进程的执行状态)
(3)阻塞(Blocked)状态
由于等待某个事件发生而无法执行时,便是阻塞状态,cpu执行其他进程.例如,等待I/O完成input、申请缓冲区不能满足等等。