实验二 树
0.目录
- [树-1-实现二叉树](#1) - [树-2-中序先序序列构造二叉树](#2) - [树-3-决策树](#3) - [树-4-表达式树](#4) - [树-5-二叉查找树](#5) - [树-6-红黑树分析](#6)树-1-实现二叉树
实验过程
- 首先,我补全了getRight,contains,toString,preorder,postorder方法的代码。
- 其次,我使用Junit写了测试代码,期间遇到了一些问题。
- 后来,问了老师之后,加入了
toString()方法和indexOf方法,换了种思路测试,测试通过了。 - 另外,我还自己写了测试类。
实验问题
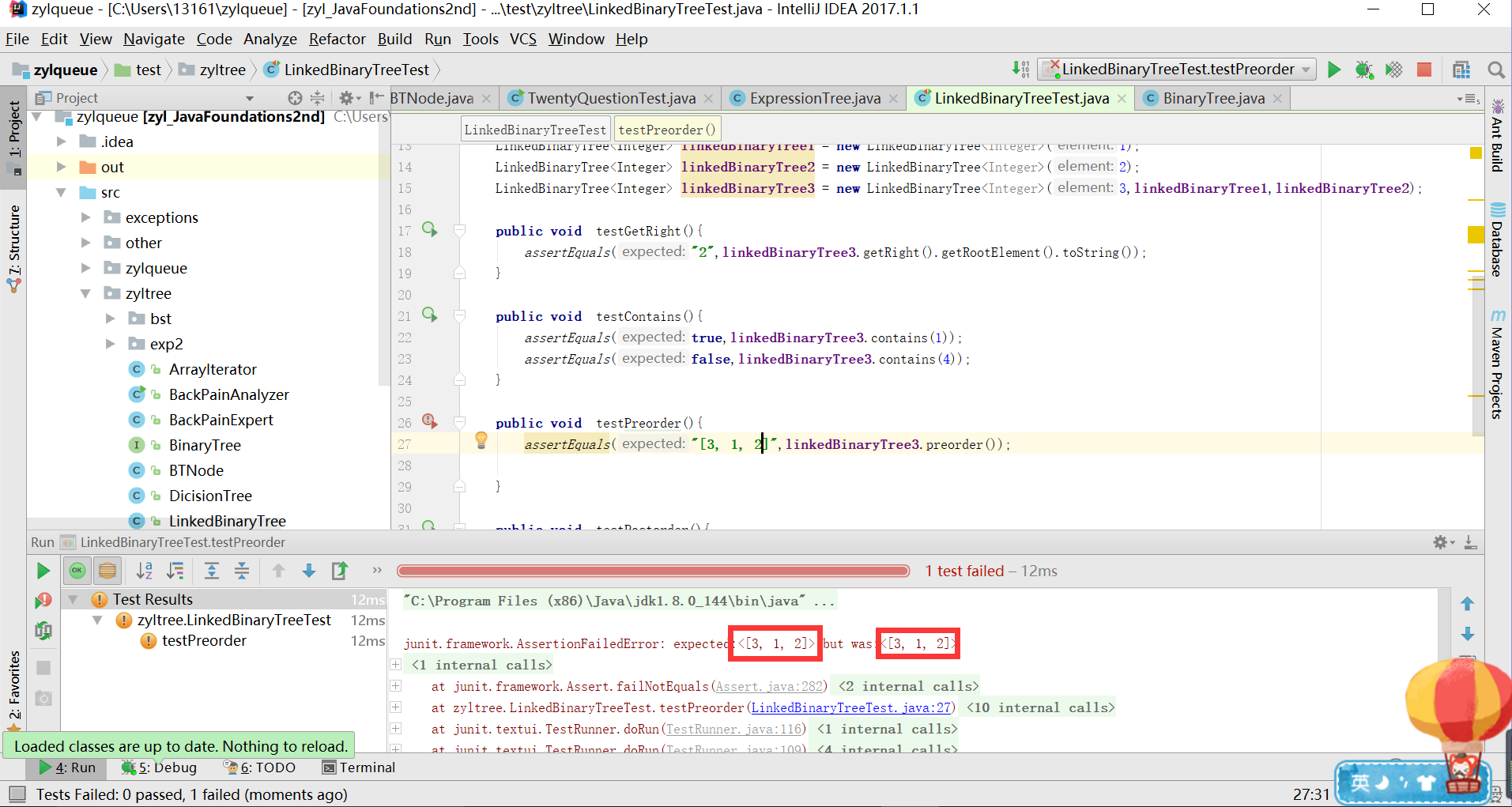
- 期望值和实际值相同,可是测试却无法通过
- 询问娄老师之后,娄老师提供了另一种测试思路,修改代码之后,测试通过了。
- 修改后的代码如下
public void testPreorder(){
assertEquals(1,linkedBinaryTree3.preorder().toString().indexOf("3"));
assertEquals(4,linkedBinaryTree3.preorder().toString().indexOf("1"));
assertEquals(7,linkedBinaryTree3.preorder().toString().indexOf("2"));
}
- 探究原因,究竟为何会出现这样的问题呢?
- 猜测:在遍历时空格可能不同
- 验证方法:在新建测试类,单步跟踪
- 问题暂未解决
实验结果
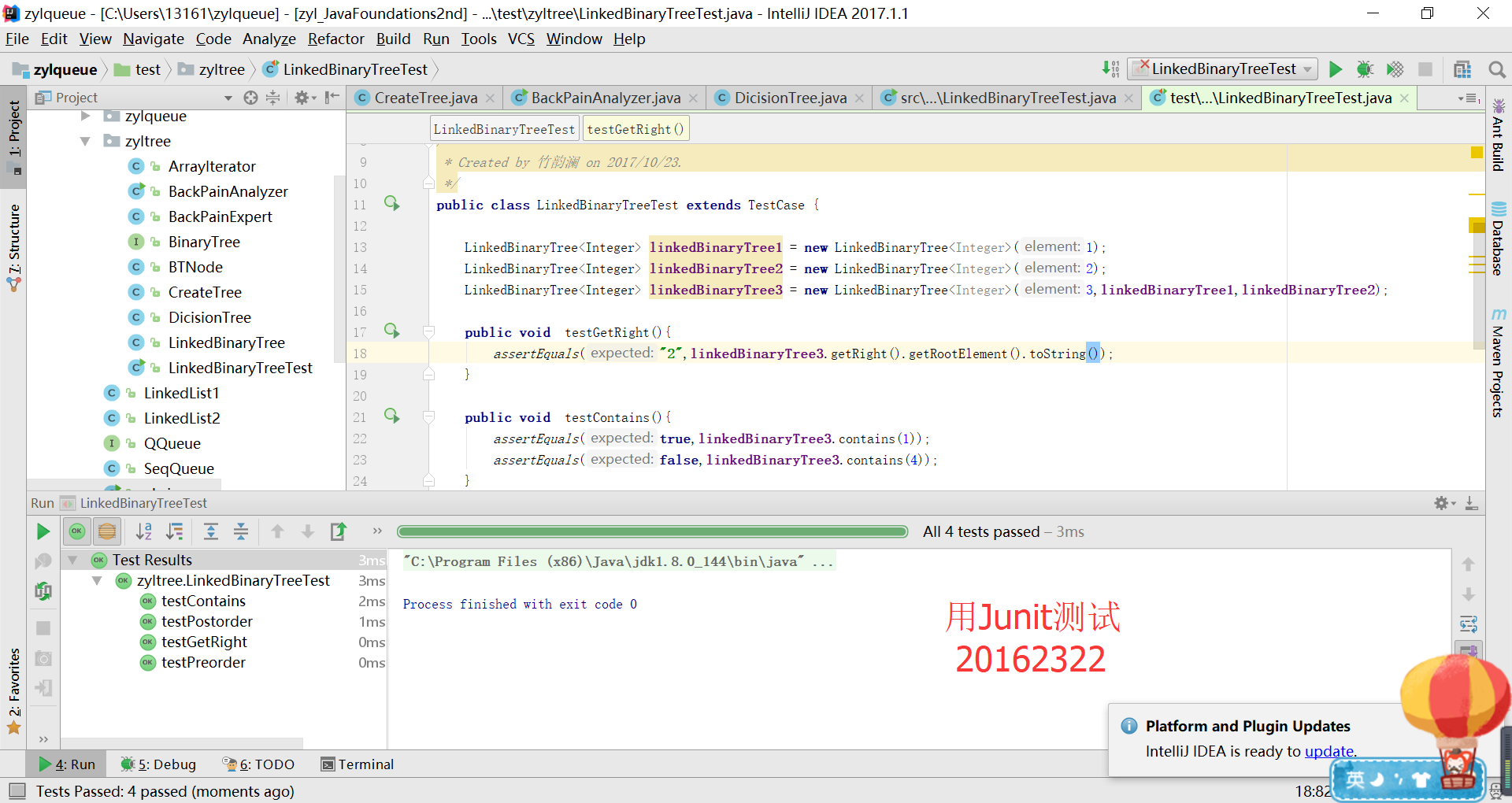

代码链接
LinkedBinaryTree
Junit Test
LinkedBinaryTreeTest自己写的测试
树-2-中序先序序列构造二叉树
实验过程
- 抓住前序遍历的第一个元素为根结点的特点,找到根结点
- 在中序遍历中找到根结点,根结点左边的即左子树,右边的即右子树
- 抓住前序遍历和中序遍历中的左子树与右子树的元素个数相等,且均在一起
- 重复步骤一、二
实验结果
- 代码1.0
public CreateTree(String preoder, String inorder){
// 前序遍历的第一个元素为根结点、
// 获取根结点
String root = (String)preoder.subSequence(0,1);
// 在中序遍历中找到root,root左边的是左子树部分,root的右边是右子树部分
String leftchild = inorder.substring(0,getInorderRoot(root,inorder) - 1);
String rightchild = inorder.substring(getInorderRoot(root,inorder) + 1, inorder.length());
}
public int getInorderRoot(String root, String inorder){
int index = 0;
for (int n = 0; n <= inorder.length(); n++){
if (root == inorder.substring(n, n+1)){
index = n;
break;
}
}
return index;
}
- 问题:
- 抽象不完全,还需要增添迭代部分。
- 由于需要将左子树和右子树部分分开,因此在得到左子树和右子树的元素个数的情况下,用可以索引的数组更方便
-
解决问题:百度到了这个方法能够解决问题:

-
代码2.0
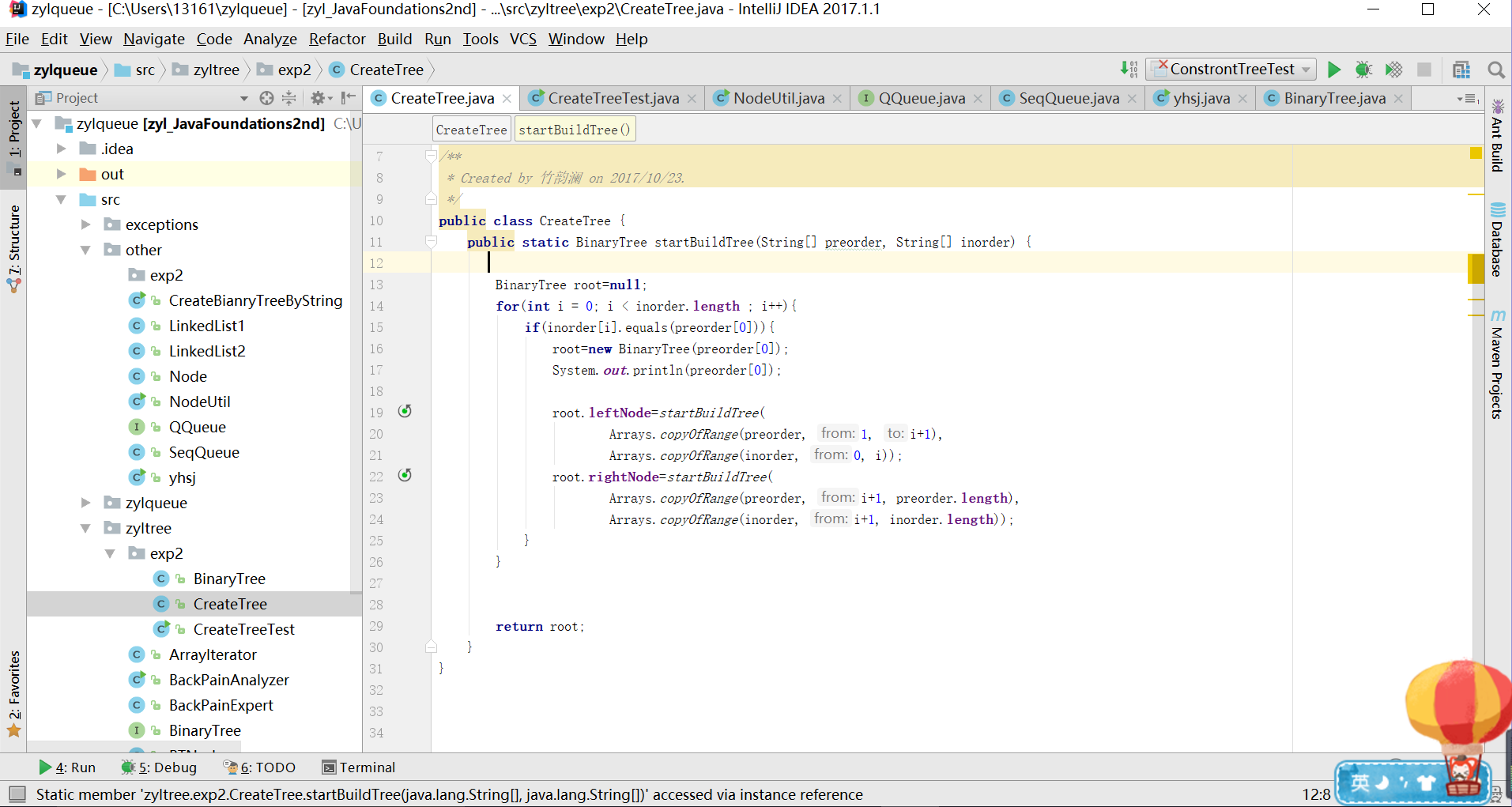
-
问题:已经很好了,能够完成任务了。又考虑了一下异常情况:preorder或inorder数组为空,或preorder和inorder的元素个数不同。
-
代码3.0

代码链接
BinaryTree
CreateTree
CreateTreeTest
树-3-决策树
实验过程
- 随机在自己的歌单中选了几首歌作为预设物体
- 自己在草稿纸中画了棵问题树
- 根据草稿修改教材中的程序16.5,构造自己的树
- 运行,测试
实验结果
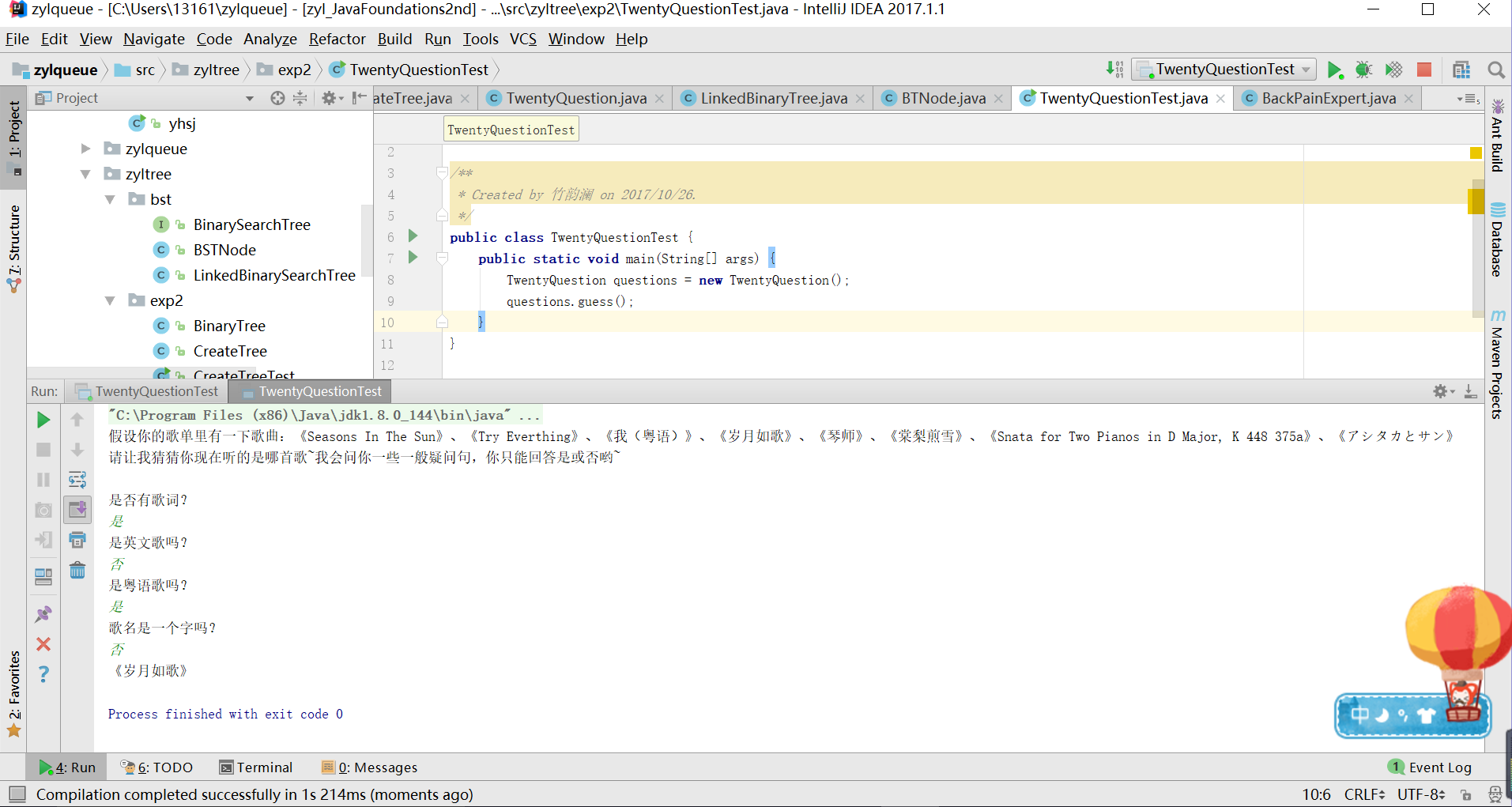
代码链接
TwentyQuestion
TwentyQuestionTest
树-4-表达式树
实验过程
- 使用ArrayList分别存放操作符和数字
- 分出操作符与数据,存放在相应的列表中
- 取出前两个数字和一个操作符,组成一个新的数字节点
- 重复第二步,直到操作符取完为止
- 让根节点等于最后一个节点
实验结果
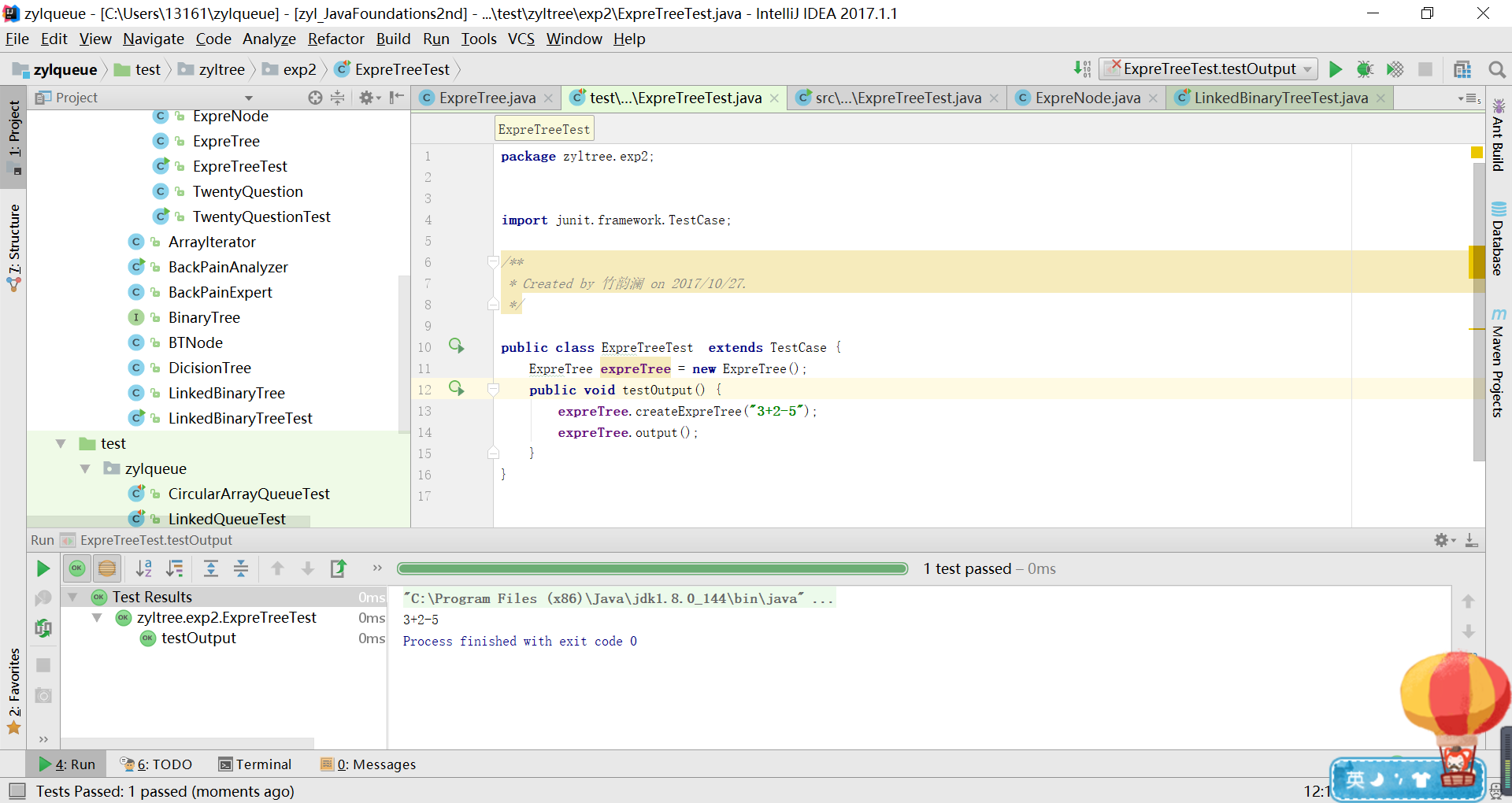
代码链接
ExpreNode
ExpreTree
ExpreTreeTest
树-5-二叉查找树
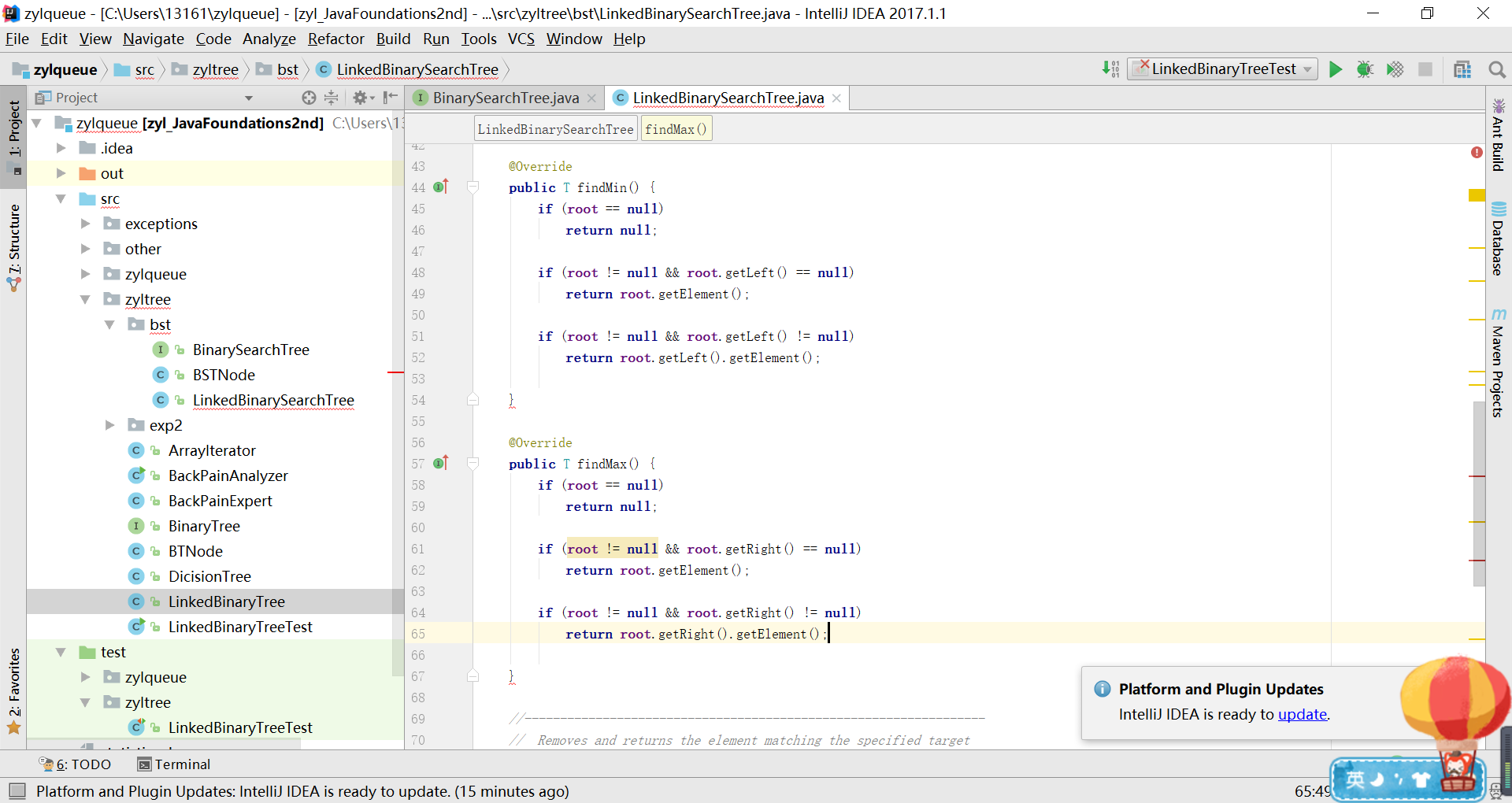
实验过程
-
实验任务是补充findMax和findMin方法,在查找树二叉树中,最小的数在最左最下端的子树,最大的数在最右端最下端的子树。
-
代码1.0
-
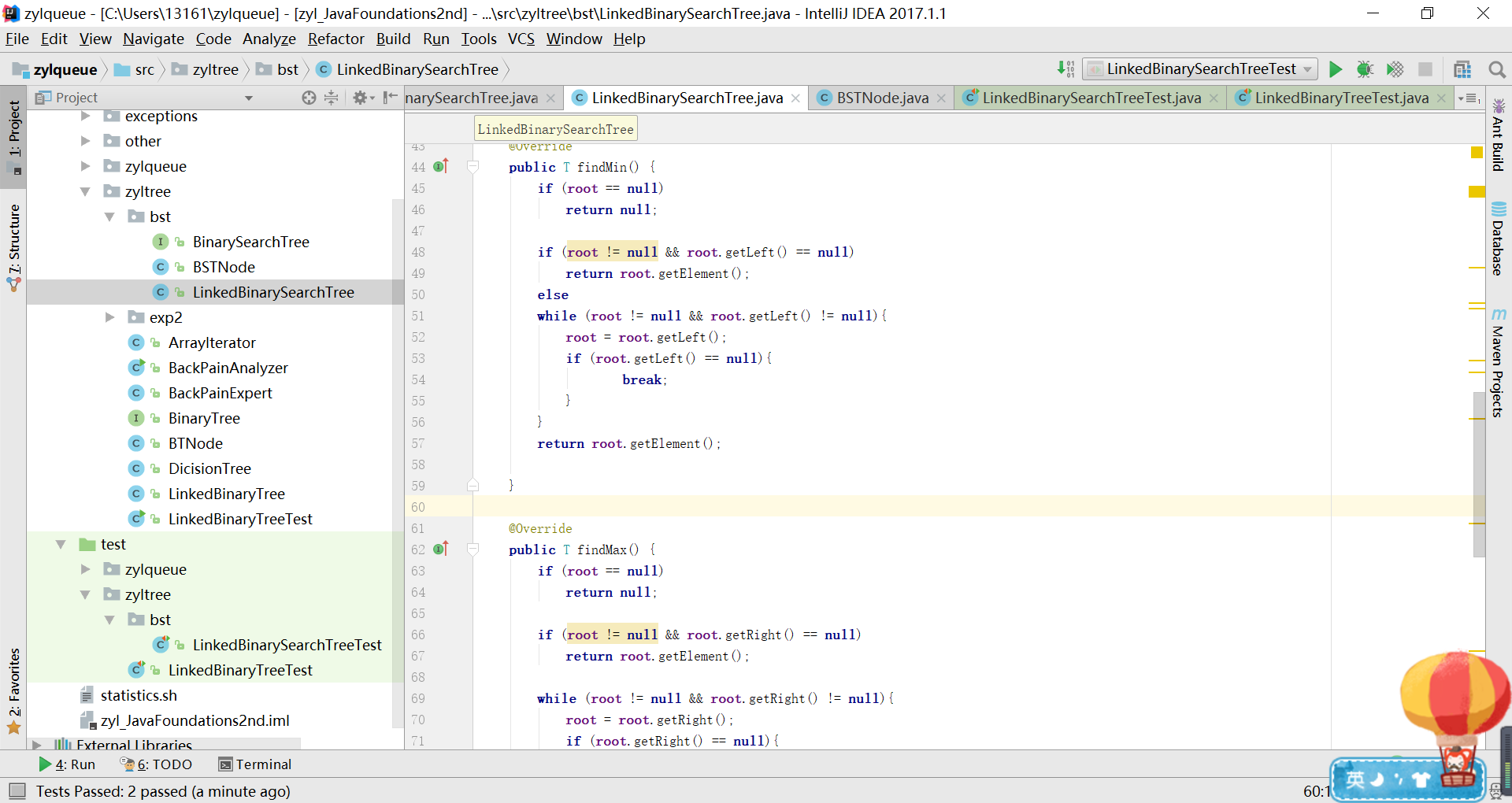
问题:第三种情况考虑不对,没有在root的左子树可能还含有左子树
-
注意:树的五种状态考虑全面:根为空,只有根,有根且有左子树,有根且有右子树,有根且有左子树和右子树。
-
代码2.0
实验结果
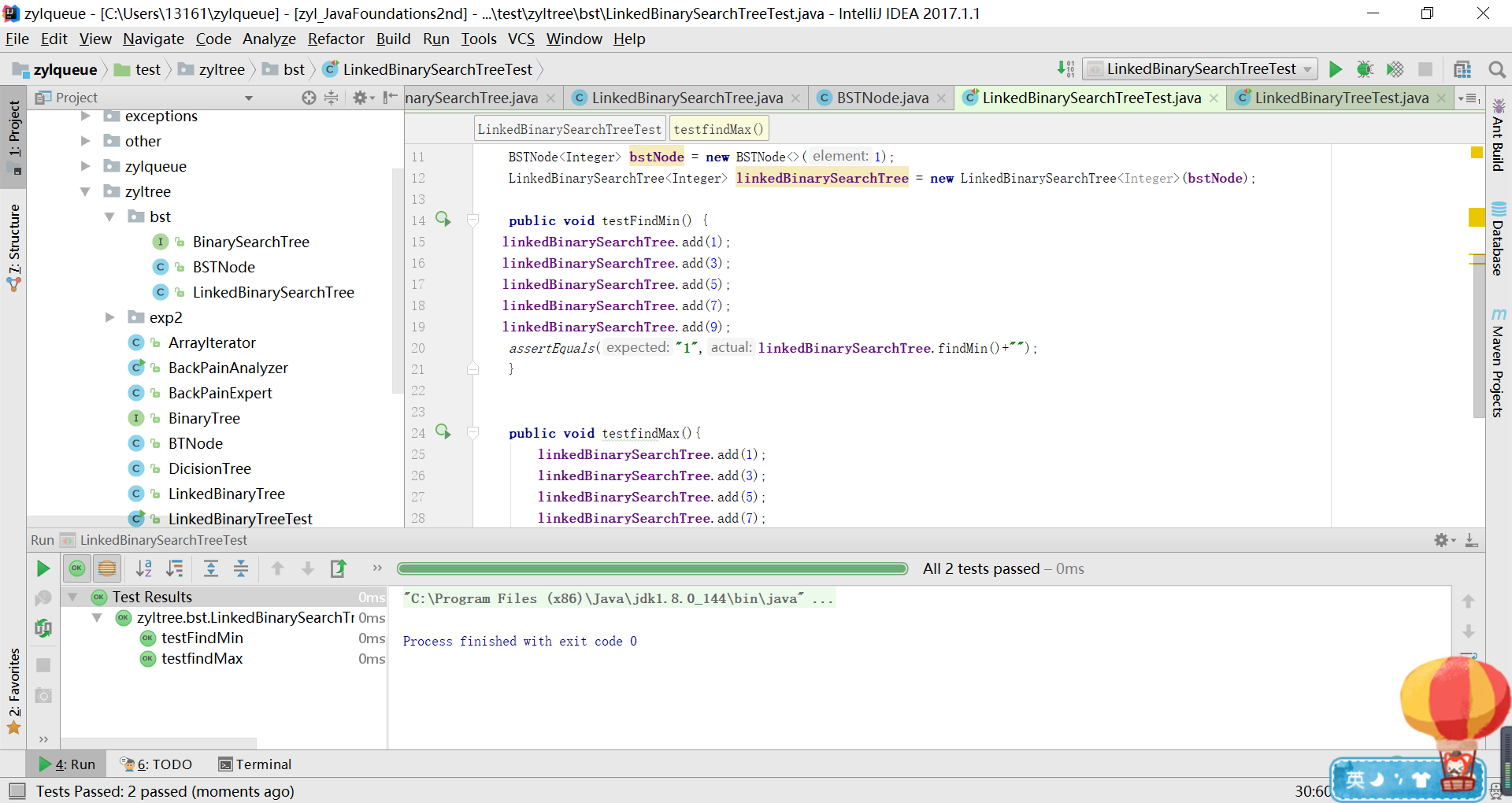
代码链接
树-6-红黑树分析
Map接口
Map 接口用于存储键/值对。Map 中的元素都是成对出现的,键值对就像数组的索引与数组的内容的关系一样,将一个键映射到一个值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。我们可以通过键去找到相应的值。value 可以存储任意类型的对象,我们可以根据 key 键快速查找 value。Map 中的键/值对以 Entry 类型的对象实例形式存在。
| 方法 | 返回值 | 说明 |
|---|---|---|
| clear() | void | 从此映射中移除所用映射关系(可选操作) |
| containsKey(Object key) | boolean | 如果此映射包含指定键的映射关系,则返回true |
| containsValue(Object value) | boolean | 如果此映射将一个或多个键映射到指定值,则返回 true |
| entrySet() | Set> | 返回此映射中包含的映射关系的 Set 视图 |
| equals(Object o) | boolean | 比较指定的对象与此映射是否相等 |
| get(Object key) | V | 返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null |
| hashCode() | int | 返回此映射的哈希码值 |
| isEmpty() | boolean | 如果此映射未包含键-值映射关系,则返回 true |
| keySet() | Set | 返回此映射中包含的键的 Set 视图 |
| put(K key, V value) | V | 将指定的值与此映射中的指定键关联(可选操作) |
| putAll(Map<? extends K, ? extends V> m) | void | 从指定映射中将所有映射关系复制到此映射中(可选操作) |
| remove(Object key) | V | 如果存在一个键的映射关系,则将其从此映射中移除(可选操作) |
| size | int | 返回此映射中的键-值映射关系数 |
| values() | Collection | 返回此映射中包含的值的 Collection 视图 |
HashMap 类
HashMap 是基于哈希表的 Map 接口的一个重要实现类。HashMap 中的 Entry 对象是无序排列的,Key 值和 value 值都可以为 null,但是一个 HashMap 只能有一个 key 值为 null 的映射(key 值不可重复)。
构造方法
- HashMap()
- 构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
- HashMap(int initialCapacity)
- 构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
- HashMap(int initialCapacity, float loadFactor)
- 构造一个带指定初始容量和加载因子的空 HashMap。
- HashMap(Map<? extends K,? extends V> m)
- 构造一个映射关系与指定 Map 相同的新 HashMap。
加载因子是表示Hsah表中元素的填满的程度.若:加载因子越大,填满的元素越多,好处是,空间利用率高了,但:冲突的机会加大了.反之,加载因子越小,填满的元素越少,好处是:冲突的机会减小了,但:空间浪费多了.
TreeMap 类
基于红黑树(Red-Black tree)的 NavigableMap 实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
构造方法
- TreeMap()
- 使用键的自然顺序构造一个新的、空的树映射。
- TreeMap(Comparator<? super K> comparator)
- 构造一个新的、空的树映射,该映射根据给定比较器进行排序。
- TreeMap(Map<? extends K,? extends V> m)
- 构造一个与给定映射具有相同映射关系的新的树映射,该映射根据其键的自然顺序 进行排序。
- TreeMap(SortedMap<K,? extends V> m)
- 构造一个与指定有序映射具有相同映射关系和相同排序顺序的新的树映射。