内容参考自:https://zhuanlan.zhihu.com/p/20894041?refer=intelligentunit
用像素点的rgb值来判断图片的分类准确率并不高,但是作为一个练习knn的题目,还是挺不错的。
1. CIFAR-10
CIFAR-10是一个图像分类数据集。数据集包含60000张32*32像素的小图片,每张图片都有一个类别标注(总共有10类),分成了50000张的训练集和10000张的测试集。
然后下载后得到的并不是实实在在的图片(不然60000张有点可怕...),而是序列化之后的,需要我们用代码来打开来获得图片的rgb值。
1 import pickle 2 3 def unpickle(file): 4 with open(file, 'rb') as f: 5 dict = pickle.load(f, encoding='latin1') 6 return dict
由此得到的是一个字典,有data和labels两个值。
data:
一个10000*3072的numpy数组,这个数组的每一行存储了32*32大小的彩色图像。前1024个数是red,然后分别是green,blue。
labels:
一个范围在0-9的含有10000个数的一维数组。第i个数就是第i个图像的类标。
2. 基于曼哈顿距离的1NN分类
这个训练文件很大,如果全部读的话会占据很多内存...第一次全部读直接内存爆炸直接死机。所以这里我就读了一个文件的内容。
1 #! /usr/bin/dev python 2 # coding=utf-8 3 import os 4 import sys 5 import pickle 6 import numpy as np 7 8 def load_data(file): 9 with open(file, 'rb') as f: 10 datadict = pickle.load(f, encoding='latin1') 11 X = datadict['data'] 12 Y = datadict['labels'] 13 X = X.reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1).astype('float') 14 Y = np.array(Y) 15 return X, Y 16 17 def load_all(root): 18 xs = [] 19 ys = [] 20 for n in range(1, 2): 21 f = os.path.join(root, 'data_batch_%d' %(n,)) 22 X, Y = load_data(f) 23 xs.append(X) 24 ys.append(Y) 25 X_train = np.concatenate(xs) #转换为行向量 26 Y_train = np.concatenate(ys) 27 del X, Y 28 X_test, Y_test = load_data(os.path.join(root, 'test_batch')) 29 return X_train, Y_train, X_test, Y_test 30 31 32 def classTest(Xtr_rows, Xte_rows, Y_train): 33 count = 0 34 numTest = Xte_rows.shape[0] 35 result = np.zeros(numTest) #构造一维向量的结果 36 for i in range(numTest): 37 distance = np.sum(np.abs(Xtr_rows - Xte_rows[i,:]), axis=1) 38 min_dis = np.argmin(distance) 39 result[i] = Y_train[min_dis] 40 print('%d: %d' %(count, result[i])) 41 count += 1 42 return result 43 44 if __name__ == '__main__': 45 X_train, Y_train, X_test, Y_test = load_all('D:学习资料机器学习cifar-10-python\') 46 Xtr_rows = X_train.reshape(X_train.shape[0], 32 * 32 * 3) 47 Xte_rows = X_test.reshape(X_test.shape[0], 32 * 32 * 3) 48 result = classTest(Xtr_rows, Xte_rows, Y_train) 49 print('accuracy: %f' % (np.mean(result == Y_test)))
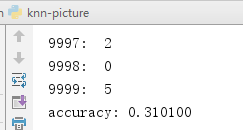
最后测试结果如下:(跑了很久...)
3. KNN
有了上面的基础,接下来要实现最KNN就很简单了,保存与测试数据最接近的k个数据,最后选出最多的即可。
1 def classTest(Xtr_rows, Xte_rows, Y_train, k): 2 count = 0 3 numTest = Xte_rows.shape[0] 4 result = np.zeros(numTest) #构造一维向量的结果 5 for i in range(numTest): 6 classCount = {} 7 distance = np.sum(np.abs(Xtr_rows - Xte_rows[i,:]), axis=1) 8 distance = distance.argsort() 9 for j in range(k): 10 votelabel = Y_train[distance[j]] 11 classCount[votelabel] = classCount.get(votelabel, 0) + 1 12 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) 13 result[i] = sortedClassCount[0][0] 14 print('%d: %d' % (count, result[i])) 15 count += 1 16 return result
4. 验证
对于如何确定一个最佳的k值,我们就需要去做验证,需要注意的是测试集不能作为验证集去验证。一般来说就是将训练数据分为两部分,一部分作为验证集去确定最佳的k值,最后再去用该k值去测试。
如果数据不是很多的话,那么就可以用交叉验证来寻找最佳的k值,交叉验证就是将数据分为多份,依次选一份作为验证集,比如将训练数据分为5分,然后进行5次训练,每次将其中一份作为验证集,另外四份作为训练集。