LSTM参数
input_size:输入维数 hidden_size:输出维数 num_layers:LSTM层数,默认是1 bias:True 或者 False,决定是否使用bias, False则b_h=0. 默认为True batch_first:True 或者 False,因为nn.lstm()接受的数据输入是(序列长度,batch,输入维数),这和我们cnn输入的方式不太一致,所以使用batch_first,我们可以将输入变成(batch,序列长度,输入维数) dropout:表示除了最后一层之外都引入一个dropout bidirectional:表示双向LSTM,也就是序列从左往右算一次,从右往左又算一次,这样就可以两倍的输出
输入
– input (seq_len, batch_size, input_size)
– h_0 (num_layers * num_directions, batch_size, hidden_size)
– c_0 (num_layers * num_directions, batch_size, hidden_size)
输出
– output (seq_len, batch_size, num_directions * hidden_size)
– h_n (num_layers * num_directions, batch_size, hidden_size)
– c_n (num_layers * num_directions, batch_size, hidden_size)
【注】如果batch_first = True,则output (batch_size, num_directions * hidden_size)
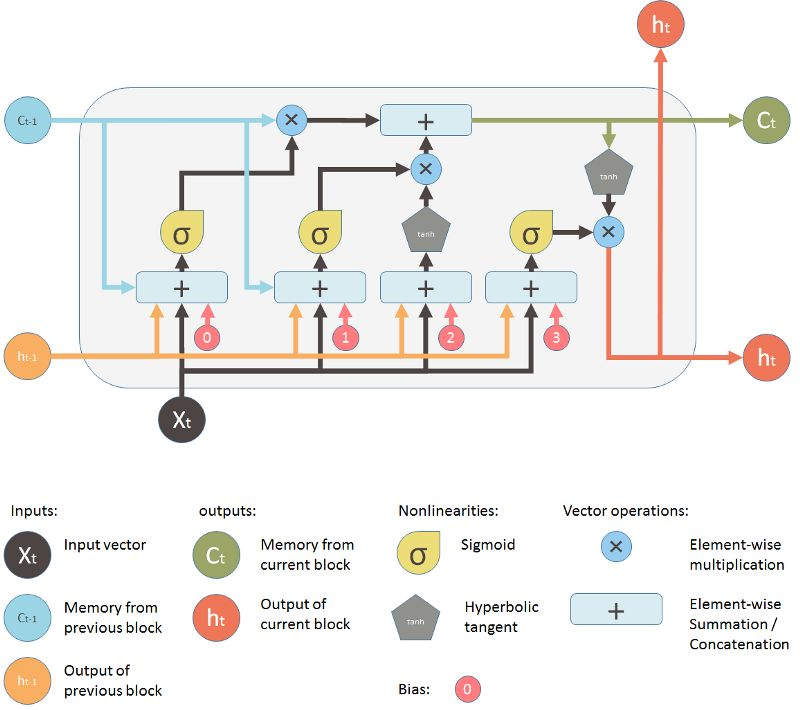
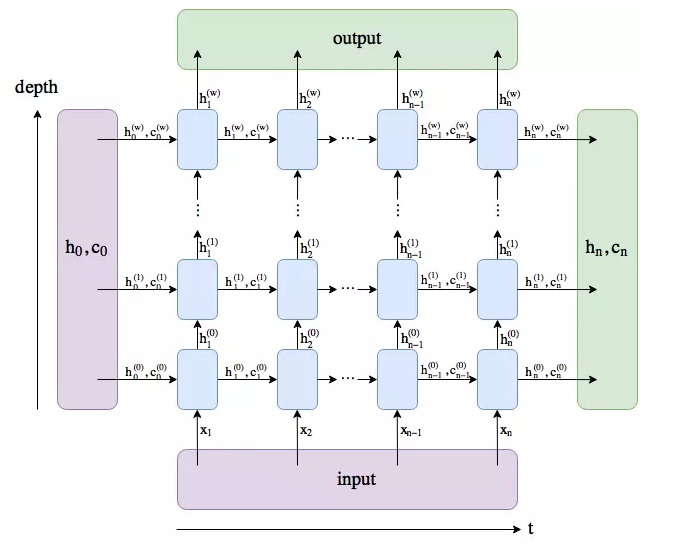
上图是LSTM的执行数据流程图,可以看到第$i$层会输出$h_{n}^{(i)}$,所以第一维为num_layers * num_directions,而对于每个批次,有batch_size个样本,每个样本都要输出,所以第二维的维度为batch_size,第三位就是$h$本身的维度大小了,及hidden_size。
$c_n$的维度大小同$h_n$是相同的。
对于句子中的每个单词,output都有一个输出,所以第一维为seq_len,第二维依然还是batch_size,第三位就是hidden_size,双向的话拼接起来就是2*hidden_size,所以就是num_directions * hidden_size。
由此可以看到当模型为LSTM时,$output[-1,:,:] = h_n[-1,:,:]$。
参考: