问题引入
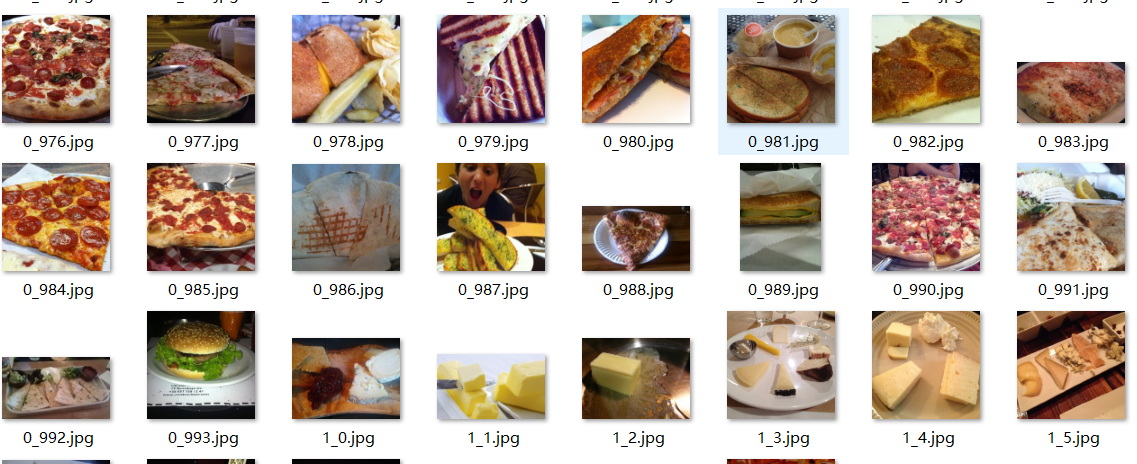
使用cnn进行食物分类,给出的图片如上所示,前面的是分类,后面的是编号。
数据处理
首先读入图片,并进行缩放处理,使像素数相同。
def readfile(path, flag):
"""
:param path: 图片所在文件夹位置
:param flag: 1:训练集或验证集 0:测试集
:return: 图片数值化后的数据
"""
image_dir = os.listdir(path)
x = np.zeros((len(image_dir), 128, 128, 3), dtype=np.uint8) # 因为是图片,所以这里设为uint8
y = np.zeros((len(image_dir)))
# print(x.shape)
# print(y.shape)
for i, file in enumerate(image_dir): # 遍历每一张图片
img = cv2.imread(os.path.join(path, file)) # cv2.imread()返回多维数组,前两维表示像素,后一维表示通道数
x[i, :, :, :] = cv2.resize(img, (128, 128)) # 因为每张图片的大小不一样,所以先统一大小,每张图片的大小为(128,128,3)
# cv2.imshow('new_image', x[i])
# cv2.waitKey(0)
if flag:
y[i] = file.split('_')[0]
if flag:
return x, y
else:
return x
PyTorch中的DataSet和DataLoader用来处理数据十分方便。
DataSet可以实现对数据的封装,当我们继承了DataSet类后,需要重写len和getitem这两个方法,len方法提供了dataset的大小, getitem方法支持索引从 0 到 len(self)的数据,这也是为什么需要len方法。
DataLoader通过getitem函数获取单个的数据,然后组合成batch。
class ImgDataset(Dataset):
def __init__(self, x, y=None, transform=None):
self.x = x
# label is required to be a LongTensor
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
self.transform = transform
def __len__(self):
return len(self.x)
def __getitem__(self, index):
res_x = self.x[index]
if self.transform is not None:
res_x = self.transform(res_x)
if self.y is not None:
res_y = self.y[index]
return res_x, res_y
else: # 如果没有标签那么只返回x
return res_x
在训练之前,还可以做一些数据增强,并且需要把数据转换成张量的形式。
train_transform = transforms.Compose([
transforms.ToPILImage(),
# 增强数据
transforms.RandomHorizontalFlip(), # 随即将图片水平翻转
transforms.RandomRotation(15), # 随即旋转图片15度
transforms.ToTensor(), # 将图片转成Tensor
])
# testing 時不需做 data augmentation
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
])
接下来就可以使用下面的语句来调用上面的定义:
train_set = ImgDataset(train_x, train_y, train_transform) val_set = ImgDataset(val_x, val_y, test_transform) train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True) val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
网络构建
构建网络的话需要继承nn.Module,并且调用nn.Module的构造函数。
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__() # 需要调用module的构造函数
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
self.cnn = nn.Sequential( # 模型会依次执行Sequential中的函数
# 卷积层1
nn.Conv2d(3, 64, 3, 1, 1), # output: 64 * 128 * 128
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 64 * 64 * 64
# 卷积层2
nn.Conv2d(64, 128, 3, 1, 1), # output: 128 * 64 * 64
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 128 * 32 * 32
# 卷积层3
nn.Conv2d(128, 256, 3, 1, 1), # output: 256 * 32 * 32
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 256 * 16 * 16
# 卷积层4
nn.Conv2d(256, 512, 3, 1, 1), # output: 512 * 16 * 16
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 512 * 8 * 8
# 卷积层5
nn.Conv2d(512, 512, 3, 1, 1), # output: 512 * 8 * 8
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 512 * 4 * 4
)
self.fc = nn.Sequential(
nn.Linear(512 * 4 * 4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
模型训练
def training(train_loader, val_loader):
model = Classifier().cuda()
loss = nn.CrossEntropyLoss() # troch.nn中已经封装好了各类损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
num_epoch = 30 # 迭代次数
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train() # 保证BN层用每一批数据的均值和方差
for i, data in enumerate(train_loader):
optimizer.zero_grad() # 清空之前的梯度
train_pred = model(data[0].cuda()) # data[0] = x, data[1] = y
batch_loss = loss(train_pred, data[1].cuda())
batch_loss.backward()
optimizer.step()
# .data表示将Variable中的Tensor取出来
# train_pred是(50,11)的数据,np.argmax()返回最大值的索引,axis=1则是对行进行,返回的索引正好就对应了标签,然后和y真实标签比较,则可得到分类正确的数量
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item() # 张量中只有一个值就可以使用item()方法读取
model.eval() # 固定均值和方差,使用之前每一批训练数据的均值和方差的平均值
with torch.no_grad(): # 进行验证,不进行梯度跟踪
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
batch_loss = loss(val_pred, data[1].cuda())
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
val_loss += batch_loss.item()
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' %
(epoch + 1, num_epoch, time.time() - epoch_start_time,
train_acc / train_set.__len__(), train_loss / train_set.__len__(), val_acc / val_set.__len__(),
val_loss / val_set.__len__()))
之前一直迷惑为什么train_pred = model(data[0].cuda())没提到forward函数却可以正常运行?后来查询资料明白:
因为nn.Module的__call__函数中调用了forward()函数,那么__call__作用是什么呢?它允许我们把一个实例当作对象一样来调用,举个简单的例子吧:
class test():
def __call__(self):
return 1
def forward(self):
return 2
if __name__ == '__main__':
t = test()
print(t())
上面的代码输出结果为1。
接下来我们再看下nn.Module中的__call__,可以看到它调用了forward。
def __call__(self, *input, **kwargs):
for hook in self._forward_pre_hooks.values():
result = hook(self, input)
if result is not None:
if not isinstance(result, tuple):
result = (result,)
input = result
if torch._C._get_tracing_state():
result = self._slow_forward(*input, **kwargs)
else:
result = self.forward(*input, **kwargs)
for hook in self._forward_hooks.values():
hook_result = hook(self, input, result)
if hook_result is not None:
result = hook_result
if len(self._backward_hooks) > 0:
var = result
while not isinstance(var, torch.Tensor):
if isinstance(var, dict):
var = next((v for v in var.values() if isinstance(v, torch.Tensor)))
else:
var = var[0]
grad_fn = var.grad_fn
if grad_fn is not None:
for hook in self._backward_hooks.values():
wrapper = functools.partial(hook, self)
functools.update_wrapper(wrapper, hook)
grad_fn.register_hook(wrapper)
return result
最后训练的结果如下所示,结果不是很好,验证集上的正确率并不高。
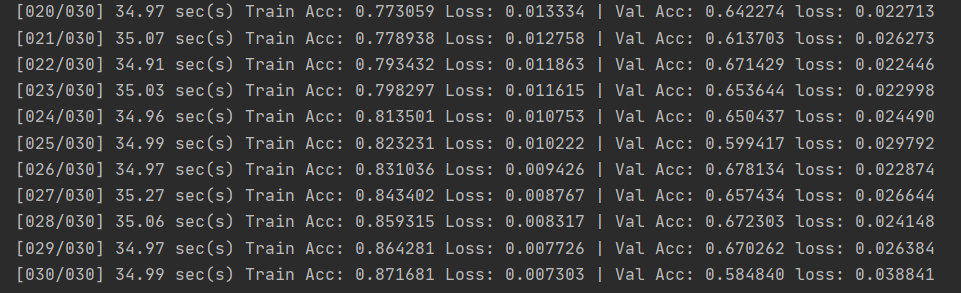
数据预测
def predict(test_loader, model):
model.eval()
result = []
with torch.no_grad():
for i, data in enumerate(test_loader):
test_pred = model(data.cuda())
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
for y in test_label:
result.append(y)
return result
def writefile(result):
f = open('result.csv', 'a')
f.write('Id,Category
')
for i, res in enumerate(result):
f.write('{},{}
'.format(i, res))
f.close()
完整代码
import os
import torch
import cv2
import time
import numpy as np
import torch.nn as nn
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
train_transform = transforms.Compose([
transforms.ToPILImage(),
# 增强数据
transforms.RandomHorizontalFlip(), # 随即将图片水平翻转
transforms.RandomRotation(15), # 随即旋转图片15度
transforms.ToTensor(), # 将图片转成Tensor
])
# testing 時不需做 data augmentation
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
])
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__() # 需要调用module的构造函数
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
self.cnn = nn.Sequential( # 模型会依次执行Sequential中的函数
# 卷积层1
nn.Conv2d(3, 64, 3, 1, 1), # output: 64 * 128 * 128
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 64 * 64 * 64
# 卷积层2
nn.Conv2d(64, 128, 3, 1, 1), # output: 128 * 64 * 64
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 128 * 32 * 32
# 卷积层3
nn.Conv2d(128, 256, 3, 1, 1), # output: 256 * 32 * 32
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 256 * 16 * 16
# 卷积层4
nn.Conv2d(256, 512, 3, 1, 1), # output: 512 * 16 * 16
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 512 * 8 * 8
# 卷积层5
nn.Conv2d(512, 512, 3, 1, 1), # output: 512 * 8 * 8
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 512 * 4 * 4
)
self.fc = nn.Sequential(
nn.Linear(512 * 4 * 4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
class ImgDataset(Dataset):
def __init__(self, x, y=None, transform=None):
self.x = x
# label is required to be a LongTensor
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
self.transform = transform
def __len__(self):
return len(self.x)
def __getitem__(self, index):
res_x = self.x[index]
if self.transform is not None:
res_x = self.transform(res_x)
if self.y is not None:
res_y = self.y[index]
return res_x, res_y
else: # 如果没有标签那么只返回x
return res_x
def readfile(path, flag):
"""
:param path: 图片所在文件夹位置
:param flag: 1:训练集或验证集 0:测试集
:return: 图片数值化后的数据
"""
image_dir = os.listdir(path)
x = np.zeros((len(image_dir), 128, 128, 3), dtype=np.uint8) # 因为是图片,所以这里设为uint8
y = np.zeros((len(image_dir)))
# print(x.shape)
# print(y.shape)
for i, file in enumerate(image_dir): # 遍历每一张图片
img = cv2.imread(os.path.join(path, file)) # cv2.imread()返回多维数组,前两维表示像素,后一维表示通道数
x[i, :, :, :] = cv2.resize(img, (128, 128)) # 因为每张图片的大小不一样,所以先统一大小,每张图片的大小为(128,128,3)
# cv2.imshow('new_image', x[i])
# cv2.waitKey(0)
if flag:
y[i] = file.split('_')[0]
if flag:
return x, y
else:
return x
def training(train_loader, val_loader):
model = Classifier().cuda()
loss = nn.CrossEntropyLoss() # troch.nn中已经封装好了各类损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
num_epoch = 30 # 迭代次数
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train() # 保证BN层用每一批数据的均值和方差
for i, data in enumerate(train_loader):
optimizer.zero_grad() # 清空之前的梯度
train_pred = model(data[0].cuda()) # data[0] = x, data[1] = y
batch_loss = loss(train_pred, data[1].cuda())
batch_loss.backward()
optimizer.step()
# .data表示将Variable中的Tensor取出来
# train_pred是(50,11)的数据,np.argmax()返回最大值的索引,axis=1则是对行进行,返回的索引正好就对应了标签,然后和y真实标签比较,则可得到分类正确的数量
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item() # 张量中只有一个值就可以使用item()方法读取
model.eval() # 固定均值和方差,使用之前每一批训练数据的均值和方差的平均值
with torch.no_grad(): # 进行验证,不进行梯度跟踪
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
batch_loss = loss(val_pred, data[1].cuda())
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
val_loss += batch_loss.item()
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' %
(epoch + 1, num_epoch, time.time() - epoch_start_time,
train_acc / train_set.__len__(), train_loss / train_set.__len__(), val_acc / val_set.__len__(),
val_loss / val_set.__len__()))
return model
def predict(test_loader, model):
model.eval()
result = []
with torch.no_grad():
for i, data in enumerate(test_loader):
test_pred = model(data.cuda())
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
for y in test_label:
result.append(y)
return result
def writefile(result):
f = open('result.csv', 'a')
f.write('Id,Category
')
for i, res in enumerate(result):
f.write('{},{}
'.format(i, res))
f.close()
if __name__ == '__main__':
train_x, train_y = readfile('./data/food-11/food-11/training', True)
val_x, val_y = readfile('./data/food-11/food-11/validation', True)
test_x = readfile('./data/food-11/food-11/testing', False)
batch_size = 50
train_set = ImgDataset(train_x, train_y, train_transform)
val_set = ImgDataset(val_x, val_y, test_transform)
test_set = ImgDataset(x=test_x, transform=test_transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
model = training(train_loader, val_loader)
result = predict(test_loader, model)
writefile(result)
参考:
[1].李宏毅机器学习-第三课作业