1.字符串操作:
解析身份证号:生日、性别、出生地等。
主要代码如下:
# # -*- coding: utf-8 -*- import re pattern = r"^[1-6]d{5}[12]d{3}(0[1-9]|1[12])(0[1-9]|1[0-9]|2[0-9]|3[01])d{3}(d|X|x)$" ID = input("请输入身份证号:") res = re.match(pattern,ID) if res == None : print("身份证号输入错误") else: print("身份证号输入正确") print('身份证号是:{}'.format(ID)) year = ID[6:14] print('出生年月为:{}'.format(year)) sex = ID[17] if int(sex) % 2 == 1: print("性别:男") else: print("性别:女")
效果如下:
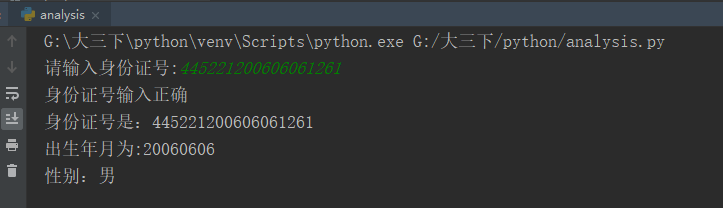
凯撒密码编码与解码
主要代码如下:
def getTranslatedMessage(mode, message, key): if mode[0] == 'd': key = -key translated = '' for symbol in message: if symbol.isalpha(): num = ord(symbol) num += key if symbol.isupper(): if num > ord('Z'): num -= 26 elif num < ord('A'): num += 26 elif symbol.islower(): if num > ord('z'): num -= 26 elif num < ord('a'): num += 26 translated += chr(num) else: translated += symbol return translated mode = getMode() message = getMessage() if mode[0] != 'b': key = getKey() print('根据你的输入获得到的信息为:') if mode[0] != 'b': print(getTranslatedMessage(mode, message, key))
效果如下:
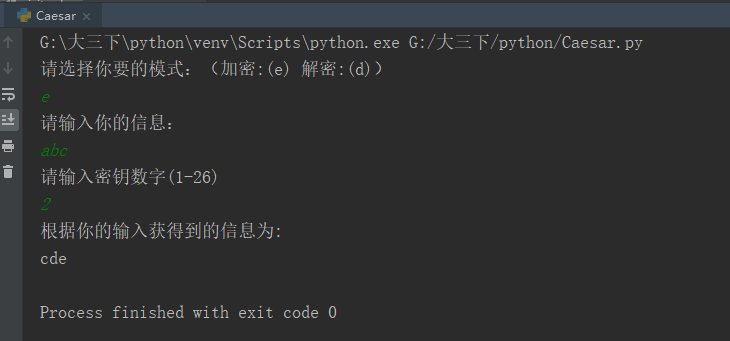
网址观察与批量生成
主要代码如下
import webbrowser as web # 引入第三方库,并用as取别名 url='http://news.gzcc.cn/html/xiaoyuanxinwen' web.open_new_tab(url) for i in range(2,4): url1='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) print(url1) web.open_new_tab('http://news.gzcc.cn/html/xiaoyuanxinwen/'+str(i)+'.html')
效果如下:
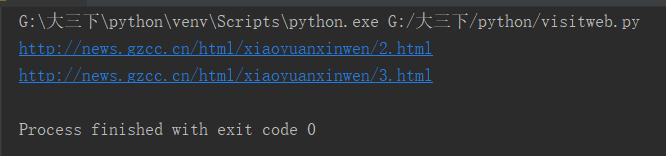
2.英文词频统计预处理
- 下载一首英文的歌词或文章或小说,保存为utf8文件。
- 从文件读出字符串。
- 将所有大写转换为小写
- 将所有其他做分隔符(,.?!)替换为空格
- 分隔出一个一个的单词
- 并统计单词出现的次数。
主要代码如下:
# # -*- coding: utf-8 -*- sep='.,:; !' fo = open(r'C:UserszyDesktopsong.txt','r',encoding='utf8') text = fo.read() fo.close text=text.lower() for ch in sep: text=text.replace(ch,' ') print(text.split()) print(text.count('you'))
效果如下:
