论文:
Compact Feedforward Sequential Memory Networks for Large Vocabulary Continuous Speech Recognition
思想:
对FSMN的模型尺寸方面进行了优化改进,
1)隐藏层后接低秩的线性矩阵,并对线性层的输出进行时序建模;
2)cFSMN中隐藏层的输出和序列记忆模块输出先加性操作后线性映射,vFSMN中先线性映射再加性合并,相当于cFSMN采用跟序列记忆模块相同的权重矩阵,从而减少了训练参数;通过改进,相比于FSMN,cFSMN能够将模型尺寸缩小60%;并且与LSTM结构相比,训练速度提升了7倍的同时,取得了比LSTM和vFSMN更好的识别效果
模型:
类似于FSMN,cFSMN整体上依然采用前馈网络结构;不同的是,cFSMN在隐藏层后接入了低秩的线性层,并对该线性层输出进行时序建模;此外,下一隐藏层的输入仅仅采用序列记忆模块的输出,忽略了该层隐层的输出部分
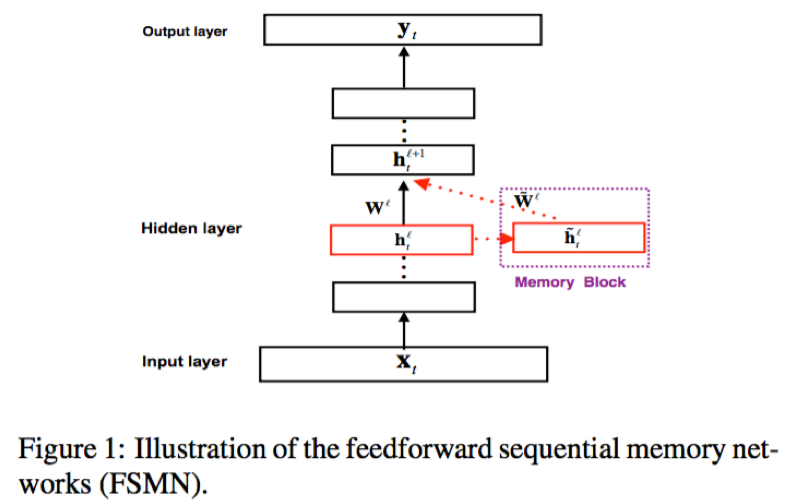
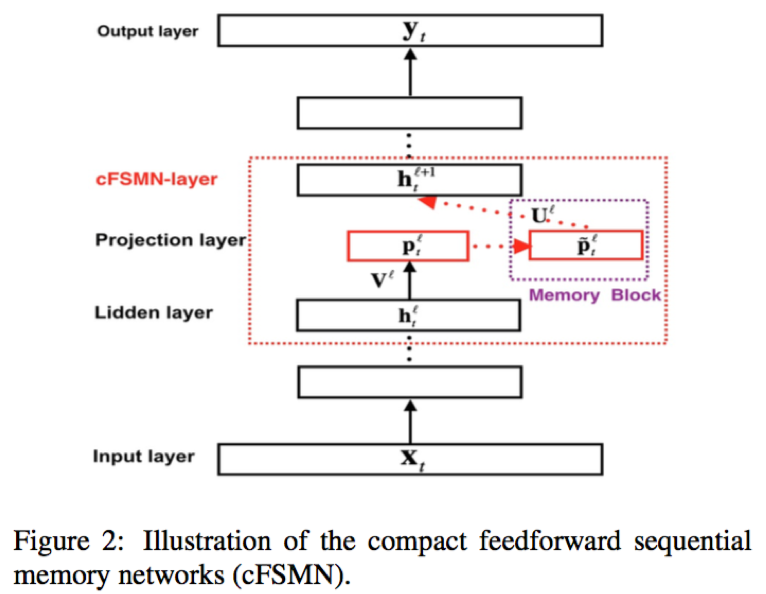
- 隐藏层:全连接层,激活函数一般为ReLU
- 线性映射层:低秩的线性结构,可以认为是没有激活且结点数较小的全连接
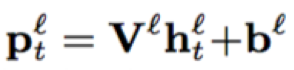
- 序列记忆模块:包含两部分,一部分来源于线性映射层的输出;另一部分即FSMN结构,对历史和未来的时序信息进行建模,整合成固定维度的编码;两部分进行加性操作后进行权重映射;单向和双向的序列记忆结构公式如下
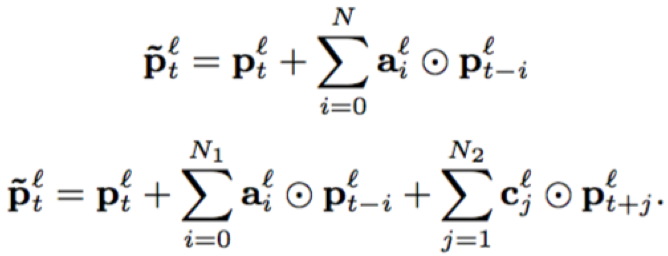
- 下一隐层的输入:从序列记忆模块的公式可以看到,当前隐层的输出采用加性操作与时序建模部分进行了合并,相当于,隐层部分输出与序列记忆模块的权重矩阵相同

将上式展开成FSMN中的形式,可以看出隐层输出和序列记忆模块输出的权重矩阵相同了
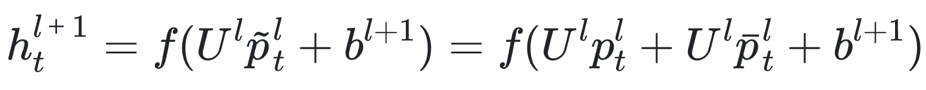
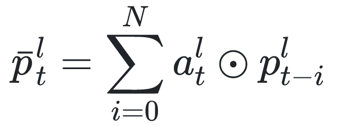
训练:
- 数据集:Switch-board (SWB),309小时Switchboard-I和20小时Call Home;99.5%train 0.5%dev;测试集:Hub5e00 1831utts
- 基线系统:
- DNN-HMM:
输入特征120维log fbank,输入包含连续上下文语音帧,窗口范围(5+1+5)
DNN结构,6*hidden layer(2048),激活函数ReLU或sigmoid
HMM,输出单元8991三音素单元
sigmoid DNN采样RBM初始化,ReLU DNN采用随机初始化
优化算法SGD,学习率/mini-batch:0.2/1024 for sigmoid DNN 0.08/4096 for ReLU DNN
目标函数:交叉熵
- LSTM-HMM
输入特征120维fbank
3*LSTMP(2048,512)
截断的BPTT训练,时间片长度16
目标函数:交叉熵
- BLSTM-HMM
输入特征120维fbank
3*BLSTMP(1024 forward,1024 backward,512)
截断的BPTT训练,时间片长度16
目标函数:交叉熵
- vFSMN
输入特征:120维fbank,输入包含连续的上下文语音帧,窗口范围(1+1+1)
6*hidden layer,奇数层添加序列记忆模块
- cFSMN
360-N × [2048-P(N1,N2)]-M × 2048-P-8991,N、M分别代表cFSMN层和全连接层;P代表线性映射层的大小(结点数);N1,N2代表历史和未来的时间片个数
实验结果:
- cFSMN结构采用4*cFSMN(全连接2048+线性映射512+历史和未来时间片长度N1=N2=30)+2全连接(2048)+1*线性映射512时取得了做好的识别效果;从结果来看,对于序列记忆模块,并不是历史和未来的时间依赖长度越长越好,当时序依赖达到一定的长度后,更多的上下文信息无用,反而形成冗余干扰
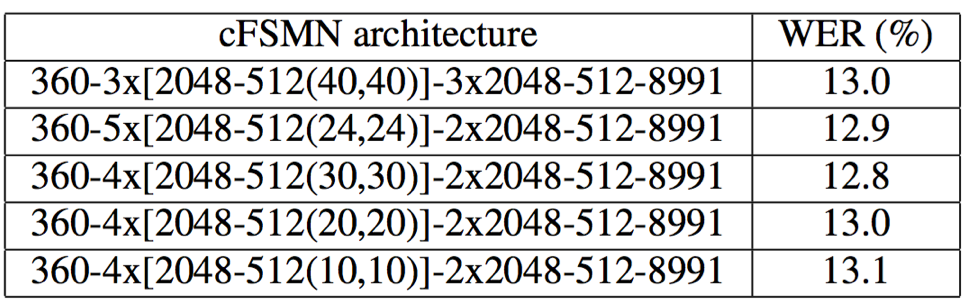
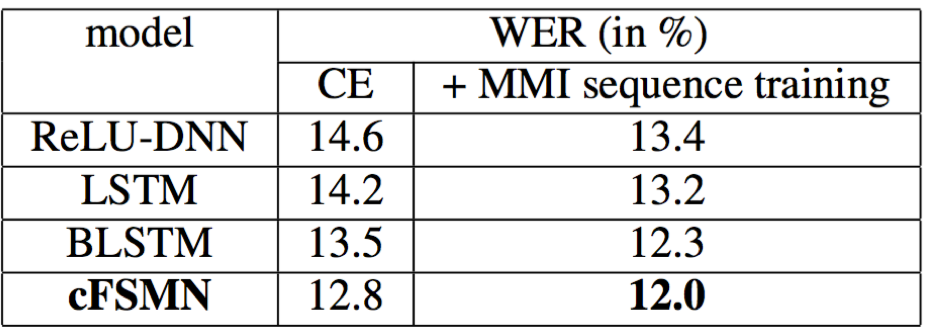
- cFSMN结构,相对于BLSTM和vFSMN,模型尺寸更小,只有vFSMN的40%;但识别效果却优于BLSTM和vFSMN;并且训练速度明显快于BLSTM和vFSMN,是BLSTM的7倍和vFSMN的2倍以上

- 当采用序列化训练策略时,cFSMN取得了更好的识别结果,同样优于相同训练策略的BLSTM结构
总结:
论文在FSMN结构的基础上对模型尺寸方面进行优化和改进,提出了一种压缩的FSMN结构,简称cFSMN;cFSMN相比于vFSMN,在参数量减少了60%的情况下,训练速度提升一倍以上的同时,在Switch-board数据集上取得了更好的识别结果。
Reference:
[1] https://arxiv.org/pdf/1512.08301.pdf(FSMN)