论文:
IMPROVING LATENCY-CONTROLLED BLSTM ACOUSTIC MODELS FOR ONLINE SPEECH RECOGNITION
思想:
BLSTM作为当前主流的序列建模算法,在语音识别领域取得了不错的效果。但因为BLSTM的双向LSTM结构,在序列建模时需要用到未来的时序信息,这使得算法在流式语音识别中受到制约,不满足流式语音识别对输出延迟的要求;而LCBLSTM结构将序列数据分割成指定长度的chunk进行训练,并通过有限长度的未来信息进行反向LSTM memory cell state的初始化,极大的加速了训练和解码过程;本文在LC-BLSTM基础上,提出了两种优化版本的结构LC-BLSTM-FABDI、LC-BLSTM-FABSR,这两种结构对BLSTM的反向初始化结构分别用前馈网络和SRNN网络进行替换,在精度几乎不损失的情况下,解码速度能够提升24%~61%
模型:
LCBLSTM的主要框架包含BLSTM层和前馈层;BLSTM层对序列数据的长时依赖性具有较好的建模能力;前馈层能够将特征转化到易于分离的空间;此外,对于反向LSTM memory cell state初始化部分论文还提出了两种建模方法,一种是前馈型结构,另外一种是SRNN结构,两种结构相比于LSTM进行建模,能够带来额外的训练和解码加速
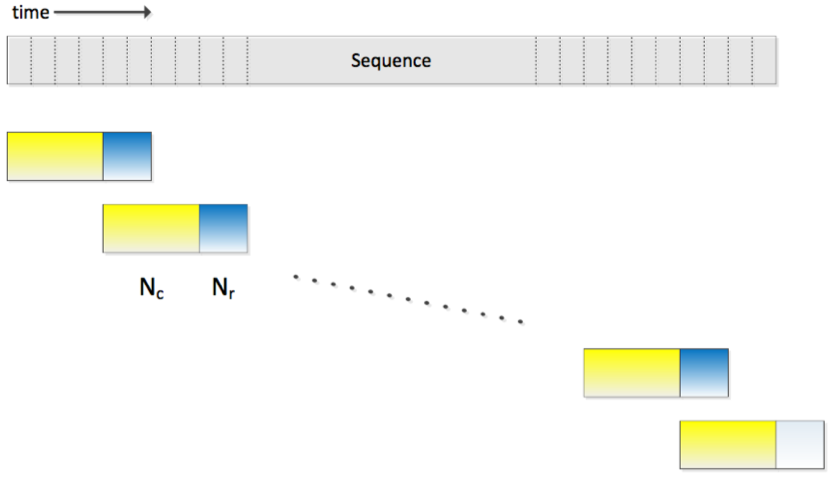
- 序列数据chunk化:为了适应流式语音识别延迟需要,LCBLSTM将输入序列数据进行切分成多个连续非重叠的chunk,每个chunk的长度为Nc,LCBLSTM的训练以chunk为一个输入序列;对于BLSTM的反向memory cell state,通过当前chunk的未来有限长度为Nr的chunk进行计算;显然,这种思路相比于利用未来所有的时序信息,有助于降低输出延迟
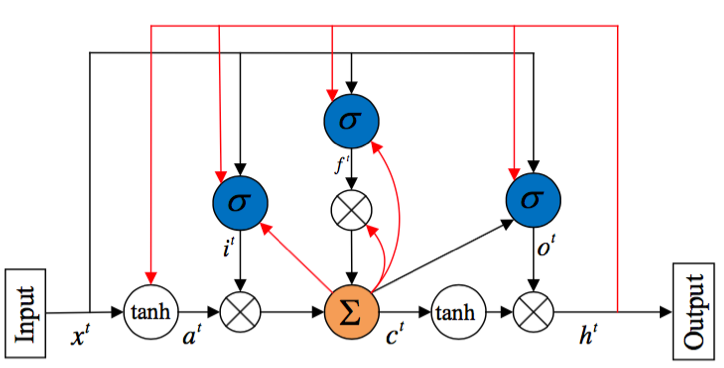
- LSTM:LSTM结构对长时依赖具有较好的建模能力,其主要通过门控单元控制信息的流入和流出;LSTM包括输入门i、遗忘门f和输出门o三种门控结构
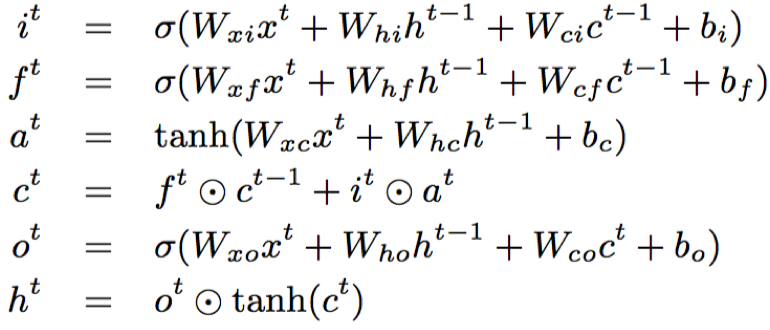
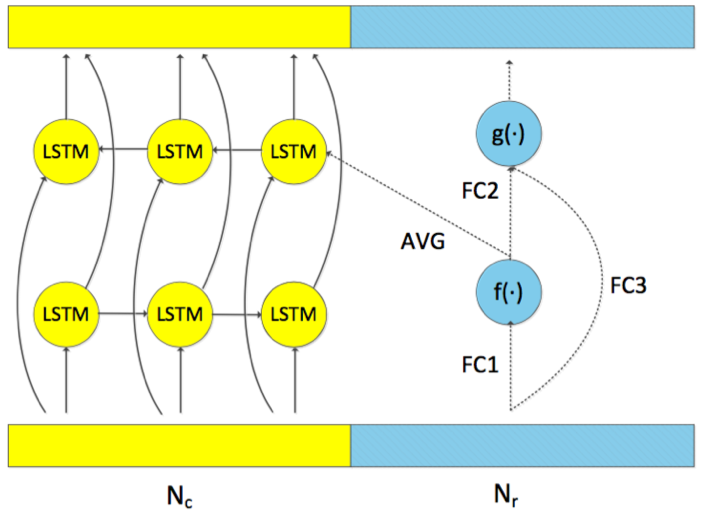
- LC-BLSTM-FABDI:LC-BLSTM-FABDI利用前馈网络结构来进行BLSTM反向memory cell state的初始化,相比于传统的LSTM结构,支持并行化计算;FABDI结构中包含三个全连接FC,FC1激活为sigmoid,FC2和FC3激活为ReLU,其中Nr中所有帧的sigmoid激活输出取平均作为第Nc帧的反向memory cell state的初始化;而对应ReLU激活的输出作为下一层FABDI层的输入,以便为下一层LSTM反向memory cell state提供初始化,以及与LSTM结构进行联合训练
- LC-BLSTM-FABSR:FABSR结构的作用与FABDI一致,但是FABSR的建模结构采用的是SRNN结构[1],该结构相对于LSTM,结构简单,参数量少,能够有效节省计算;
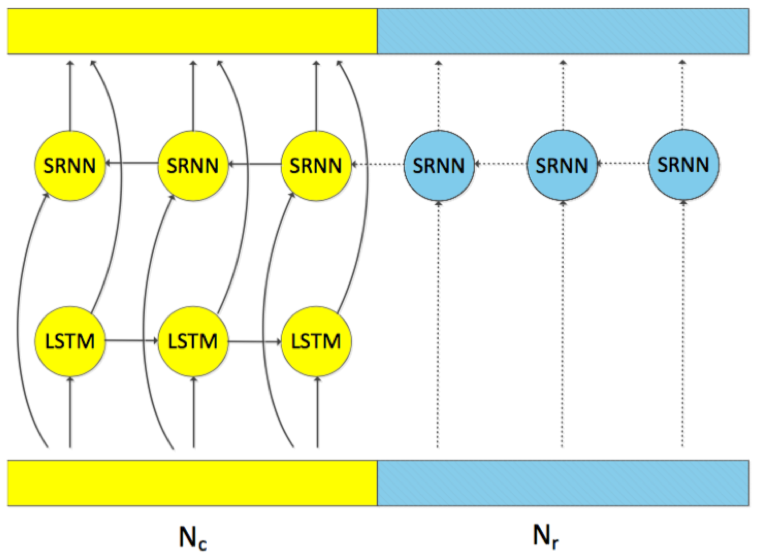
SRNN的结构如下:

训练:
- 声学数据集:Switchboard 320小时(309小时Switchboard-I+20小时call home);测试集:NIST 2000 Hub5e set(1831 utts);
- 语言模型数据集:14M文本数据(11M Fisher English Part 1+3M声学数据集对应标签)
- 输入特征:108维fbank(静态、一二阶差分)
- 输入序列切分成固定长度的chunk,长度为Nc=80,未来的信息长度Nr=30
- 状态对齐模型GMM-HMMs:输入特征39维mfccs(静态、一二阶差分);输出单元:8882;训练准侧:MLE(最大似然估计)
- 网络结构:3*BLSTM(500+500)+2*ReLU DNN(2048)+softmax
- 初始化:均匀分布初始化模型参数(-0.01~0.01)
- 训练参数:学习率:0.00005; momentum:0.9; 优化算法:异步随机梯度下降法ASGD(4 GPUs)
- 语言模型:4-gram
实验结果:
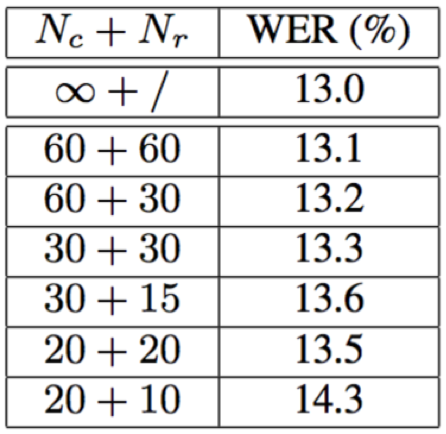
- Nc和Nr的长度变化会对识别结果造成一定影响,长度越长,效果越好;但是,选取合适长度的Nc和Nr,实际对精度的影响比较轻微,却可以显著提升解码速度
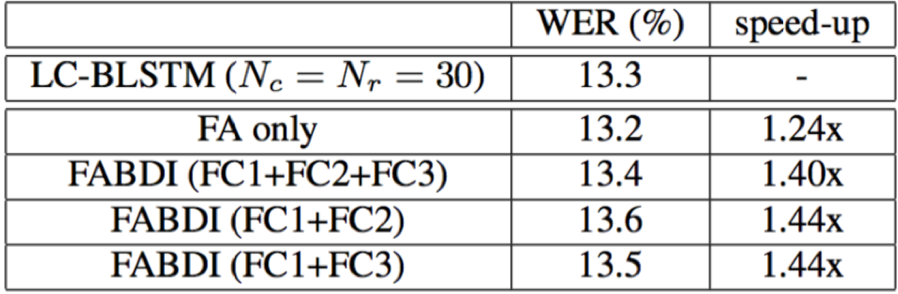
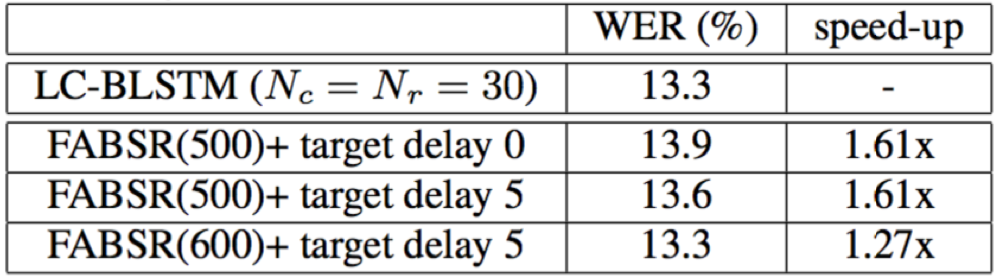
- 论文提出的两种LSTM反向memory cell state初始化结构FABDI和FABSR,相对于原始的LC-BLSTM,识别精度几乎不损失的情况下,能够带来24%~61%的解码速度提升;
结论:
本文在LC-BLSTM结构的基础上,对LSTM反向memory cell state初始化结构进行了改进,提出了两种建模的方法,一种是前馈网络FABDI,另外一种是简单RNN结构FABSR,这两种结构通过实验证明,都能够在精度几乎不损失的情况下,带来一定的解码速度提升
Reference: