论文:
CTC:Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks
思想:
语音识别中,一般包含语音段和对应的文本标签,但是却并不知道具体的对齐关系,即字符和语音帧之间对齐,这就给语音识别训练任务带来困难;而CTC在训练时不关心具体的唯一的对齐关系,而是考虑所有可能对应为标签的序列概率和,所以比较适合这种类型的识别任务。
细节:
- 输入: x = (x1, x2, ..., xT )
- 字符集: L' = 有效字符集 L U{blank}, blank用于处理当字符连续出现的情况
- 对齐序列和标签序列的多对一关系: 对于一个标签序列l,其对应的所有可能的路径集合为B(e.g. B(a-ab-) = B(-aa--abb) = aab),其中任意一条路径为π
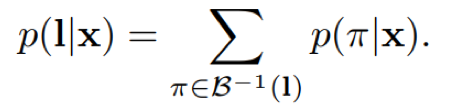
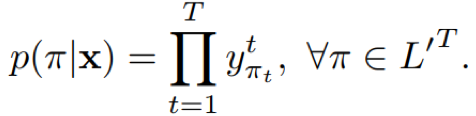
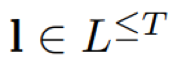
其中,y项为路径π在t时刻的的字符所对应的概率,l不包含blank

- CTC的优化目标为最大化所有映射为标签的路径的log概率和,如果取负号,则变成最小化

其中,D为训练集合,X为输入序列,Y为标签序列对应的对齐序列
- 路径搜索:在计算目标函数时,我们需要计算训练集中每个标签序列对应的对齐序列的概率,对于一个标签序列可能对应很多的对齐,计算和存储较大,影响训练效率;CTC中采用一种动态规划算法,即前向后向算法来高效计算对齐路径的概率p(l|x)
- 为了处理字符连续重复出现的情况,需要在标签序列每个字符的前后插入blank,这样原始标签l,变成l',长度变成2|l|+1,l=(y1, y2,…, yU),变成l'=(ϵ, y1, ϵ, y2,…, ϵ, yU, ϵ)
- 前向
定义αt(s) 为时刻t处于状态s的前向路径l1:s对应的概率和,αt(s)可以通过αt-1(s)和αt-1(s-1)递归计算


1)路径的起始字符可以是blank,也可以是第一个有效字符l1,基于此进行递归计算后续路径概率
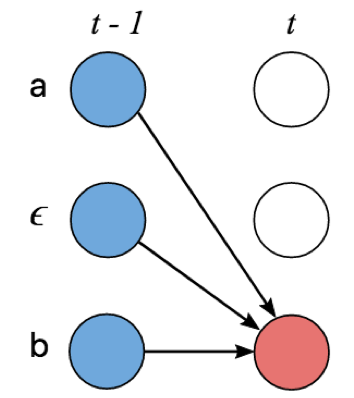
2)对t时刻的字符s,其来自于上一时刻的可能字符有两种情形:
当t时刻字符s=blank或者s=s-2,其上一时刻可以是字符本身s或者s-1,两种情况
其他情况时,其上一时刻可以是本身s、blank s-1和l'的前一有效字符s-2,三种情况
- 后向
定义βt(s) 为时刻t处于状态s的后向路径ls:|l|对应的概率和,同理,βt(s)可以通过βt+1(s)和βt+1(s+1)递归计算

1)路径的起始字符是blank,也可以是l的最后一个有效字符l|l|,基于此进行递归计算后续路径概率
2)对t时刻的字符s,其概率合并的形式分两种:
当t时刻字符s=blank或者s=s+2,t+1可以是字符本身s或者s-1,两条路径来源概率叠加
其他情况时,t+1时刻可以是本身s、blank(s-1)和l的后有效字符s+2,三条路径来源概率叠加
- 前向后向整合
由前向概率和后向概率计算得到标签路径对应的所有可能对齐序列的概率和p(l|x)
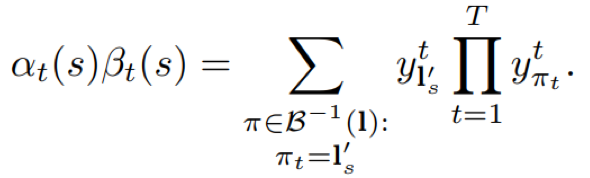
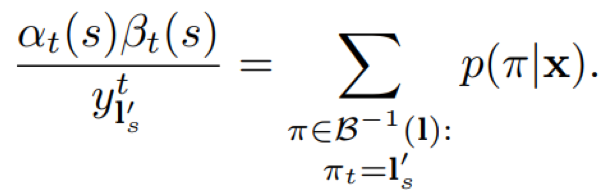
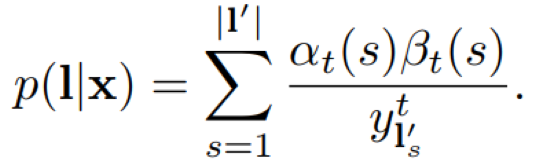
训练:
- 网络结构BLSTM(单向结点数100)+full_connected(26)+softamx(62,61字符+blank)
- 数据集TIMIT,train+dev 4620utts、test 1680utts
- 声学特征:13维MFCCs+13维delta=26维
- SGD,学习率10-4,momentum=0.9
- 权重初始化维均匀分布[-0.1,0.1]
预测:模型训练完成后,对于给定的输入序列,计算最可能的输出序列

- 直观的办法是将每一个时间片最大预测概率对应的字符串联起来,得到输出序列,但此方法的缺点是没有考虑一个输出序列可能对应多条对齐路径的情况,这样可能得不到最大概率对应的输出,比如aaϵ和aaa单独每个路径概率可能小于bbb,但因为二者对应同一个输出p(a),所以二者累加后概率可能大于bbb对应输出p(b),从而导致错失最佳路径
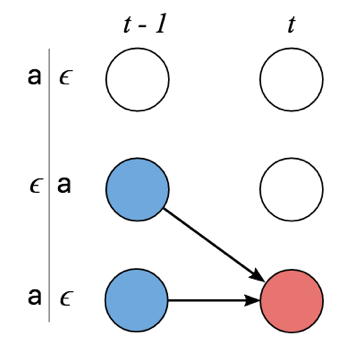
- CTC中采用prefix beam search算法,想比于beam search 增加了路径合并的操作,即一方面在路径搜索的过程中对相同映射的路径进行合并;另一方面选取合适的beam size,仅保持最优的n条路径,剔除概率较少的候选路径,节约计算;

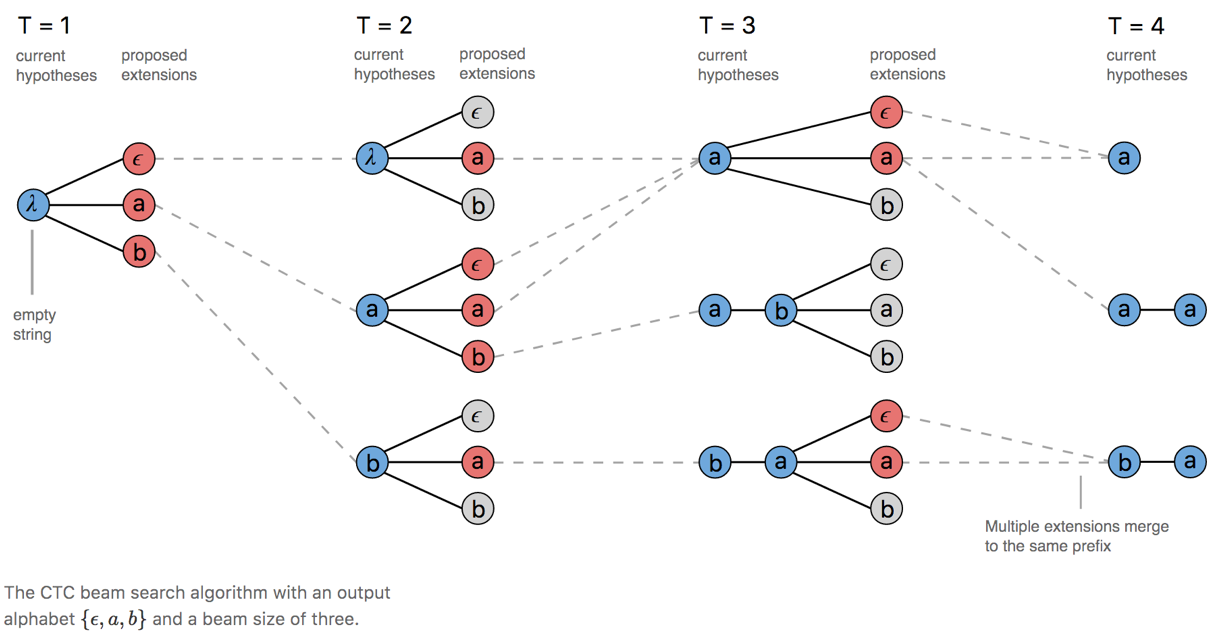
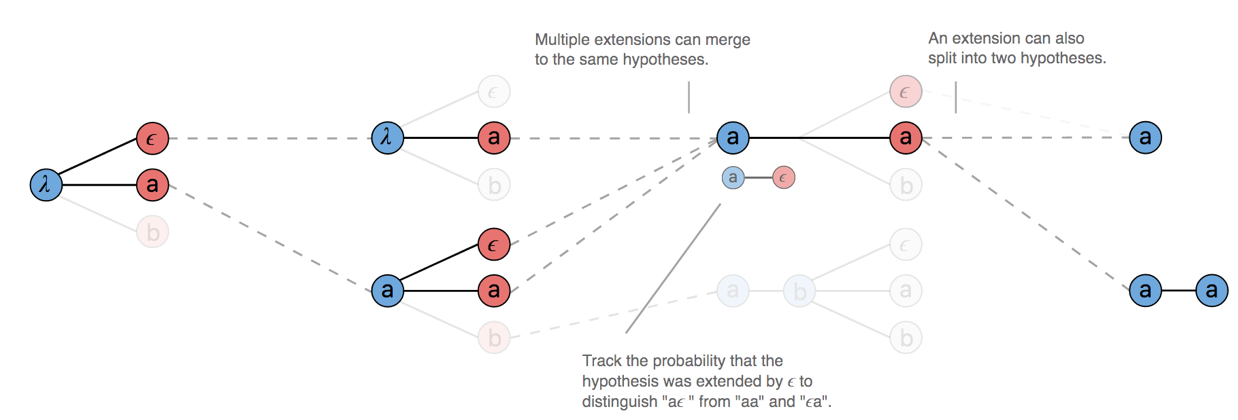
上图中,存在路径的合并操作,在T=2时刻aϵ和aa都对应a,于是二者概率叠加,路径合并为a;在T=3时刻,对于prefix路径a,当前时刻字符可以是ϵ或者a,此时需要考虑字符连续情况(否则,可能会将连续字符合并为单一字符,比如实际为aa,输出为a情况),所以,prefix路径分为两部分,以ϵ结束和不以ϵ结束两部分,以ϵ结束与t时刻a组成aa,不以ϵ结束部分与t时刻ϵ和a合并仍为a;所以,在prefix beam search算法中需要迭代维护两个概率,一个是prefix以ϵ结束的概率,另一个是prefix不以ϵ结束的概率
- 在实际语音识别中,还可能会与语言模型进行结合,提升识别效果

其中α、β为对应权重,L(Y)为路径的长度,缓解模型倾向于输出短路径的问题
论文效果:
相比于HMM和HMM-RNN结构提升了5~8%

实战分析:
DeepSpeech2:https://github.com/PaddlePaddle/DeepSpeech/
ideas:
- m*Conv2d+n*BIGRU+k*FC+wrapctc;
- BN,其中rnn BN仅对当前时刻激活前输出进行归一化,效果更好;
- sortedGrad,采用随机minibatch策略训练时,由于一些样本长度较长,路径的预测概率接近0,导致训练不稳定,论文采用第一个epoch通过排序的数据训练,第二个epoch开始随机minibatch训练;
环境安装:GPU和CPU两个版本;安装时会附加安装相应的版本对应的依赖包;注意GPU版deepspeeh2要求paddlepaddle==1.6以上;相应的cuda和cudnn也有版本对应要求,具体参照https://www.paddlepaddle.org.cn/documentation/docs/en/install/index_en.html
- 数据处理:训练和测试数据统一整理成manifest.train/dev/test形式,每一行包含{文件路径、时长、文本}
- 随机从训练集中抽取2000个样本,计算这批样本的功率谱均值和标准差用于数据归一化数据
- 数据增强:在配置文件中设置相关参数,包含语速、音量、帧移、噪声、混响等扰动,后两者需要事先准备噪声和混响文件
- 模型:2conv(bn)+3biGru(fc+bn+gru,fc+bn+gru reverse,concat)+fc(dict_size+1)+softmax+wrapctc
- 语言模型kenlm,可通过该工具训练自己的n-gram语言模型,参考链接:https://github.com/kpu/kenlm
实测效果:aishell test 百度提供的语言模型,cer: 0.080447/aishell语料单独训练的语言模型,cer:0.105999
idea:
- 输入特征: stft-161维;
- 11convBlock(conv1d+GLU+dropout)+ctc;
- GLU门控线性单元,收敛速度快、防止梯度弥散;

- 建模单元:单字4334;
- 训练集排序后划分minibatch;
- 语言模型基于kenlm;beamsearch解码;
- 注意,torch版本最好按照项目要求的1.0.1,本人安装高版本torch运行项目时发生内存泄漏问题,按照项目要求安装1.0.1后再运行问题解决
实测效果:aishell test cer:百度开源的语言模型 0.112/aishell语料单独训练的语言模型 0.192
idea:
- 输入特征:200维log频率谱
- 模型:
CNNs网络模型cnn-ctc: 2conv(3*3,输出通道数32)+max pooling(3*3)+
2conv(3*3,输出通道数64)+max pooling(3*3)+
2conv(3*3,输出通道数128)+max pooling(3*3)+
2conv(3*3,输出通道数128)+dense(256)+softmax+ctc; 每个卷积层采用BN;全连接层采用Dropout=0.2
RNN网络模型gru-ctc: 2dense(512)+3BiGRU(512)+dense(512)+softmax+ctc;全连接层采用Dropout=0.2
- 输出字符为带字符的拼音,比如:好--hao3
- 语言模型采用transforme训练得到
- 解码采用greey search/beam search
实测效果:
无论是在cnn-ctc还是在gru-ctc模型训练均出现问题,cnn-ctc是不收敛,而gru-ctc是出现aishell测试集识别率极低的问题;此外该项目作者Github貌似停止维护
Reference: