论文:
Self-Attentive Speaker Embeddings for Text-Independent Speaker Verification
思想:
本文主要是对x-vector的统计池化结构进行改进,引入self-attention机制,得到带权重的均值和标准方差,这样一方面可以学习时序特征的重要性,另一方面可以有效降低噪声和静音等干扰,因而取得了比之x-vector更好的效果
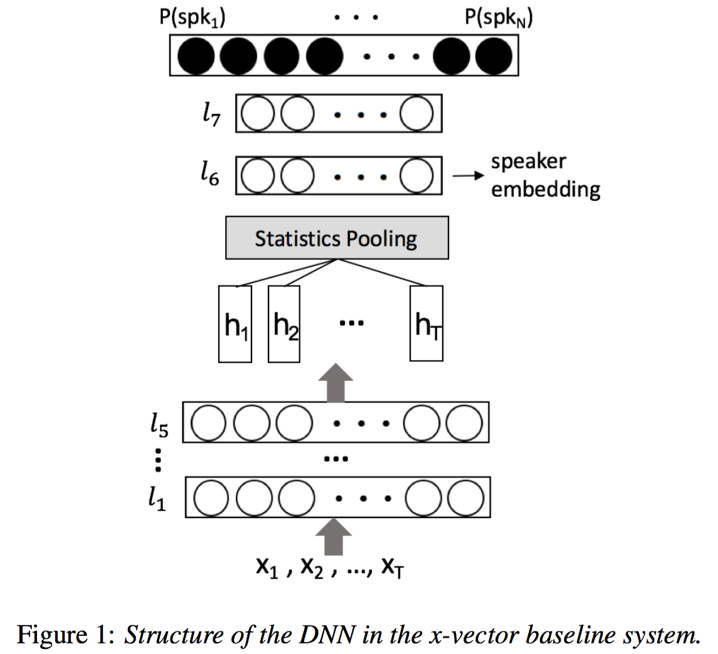
模型:本文模型大体采用x-vector结构,只是对统计池化层部分,引入了self-attention机制,将之前等权重的均值计算,优化为带self-attention权重的均值,得到句子级别的编码
- 帧级别的TDNN:模型的前几层采用TDNN结构来提取输入序列帧级别的特征表达,TDNN结构实质上就是DNN结构,只不过输入为历史帧、当前帧和未来帧之间的拼接,并且采用BN进行归一化,激活为ReLU

- self-attention:self-attention是一种非循环的注意力机制,常用于基于transformer的e2e语音识别任务;一般,self-attention由multi-head attention和feed-forward network串接而成,并且引入skip-connection保证训练稳定;
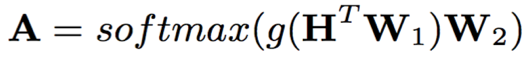
其中,H={h1,h2,...,hT},H尺寸为dh*T,W1尺寸为dh*da,g()代表激活函数,W2尺寸为da*dr,这样A尺寸为T*dr

A的每一列代表一个权重向量,不同的列代表self-attention中不同head学习不同的说话人区分性特征,E为权重均值
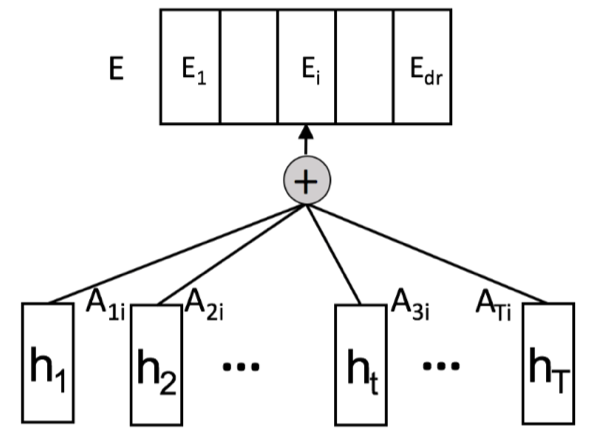
- 句子级别的DNN:self-attention后接两层DNN,学习具有区分性的说话人编码
- PLDA:将不同的说话人编码中心化,LDA降维并长度归一化后进行PLDA计算,即计算两个说话人编码属于同一说话人和不同说话人似然的比值,得到相似度得分
训练:
- 数据集
- 训练集
Switchboard 2 Phase 1, 2, 3 and Switchboard Cellular:2.6k speakers 28k utts
NIST SREs data from 2004 to 2010 along with Mixer 6: 4.4k speakers 63k utts
数据增强:MUSAN噪声(babble, music, noise), and 模拟混响reverb
- 验证集:SRE16,enroll segments 60s;test segments 10~60s
- 模型参数
- 输入特征:包含上下文的115维特征
- 帧级别DNN:4*TDNN layer(512节点)+1*TDNN layer(1500节点)
- self-attention:da=500
- 句子级别DNN:2*DNN(512)
- LDA: 512->150
实验:
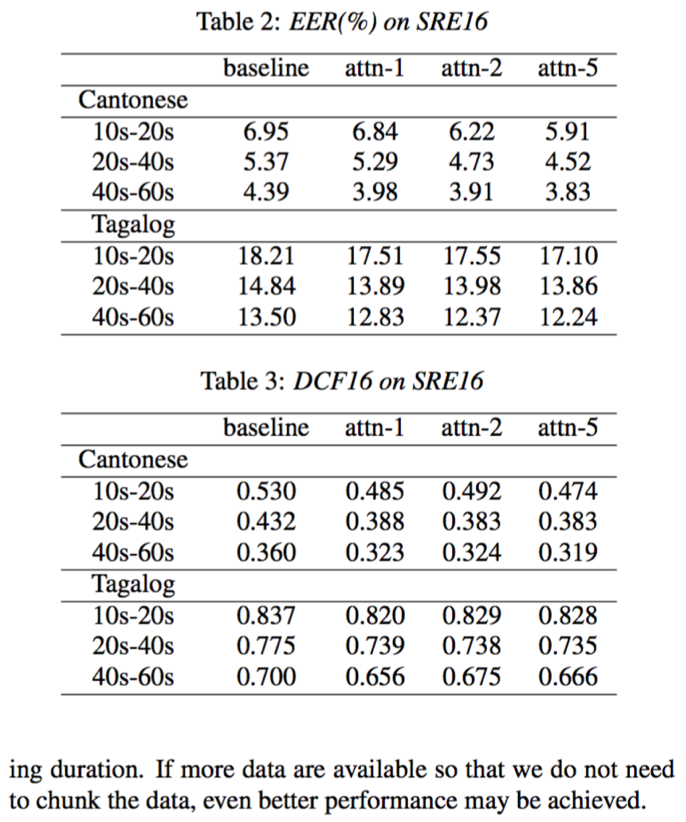
- 基于self-attention的x-vector能够提升说话人验证效果;增加self-attention的head个数有助于学到更多更具区分性的说话人特征;从实验效果来看,带权重均值+标准差能够更好的结果
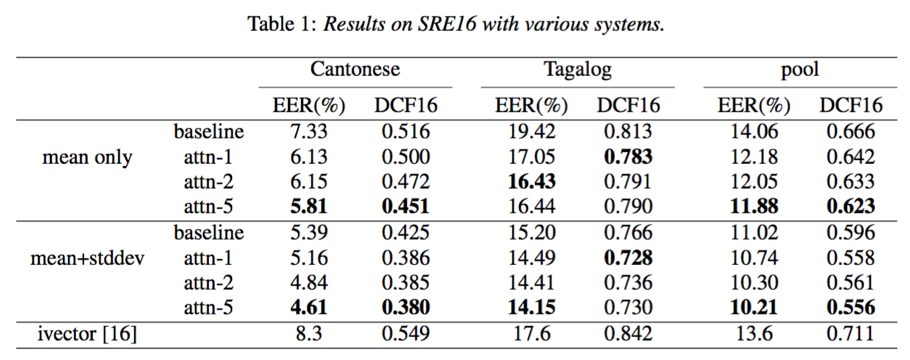
- 从DCF曲线来看,self-attention相比x-vector能够降低错误接受率和错误拒绝率;增加head个数或采用mean+stddev有助于进一步降低错误接受率和错误拒绝率
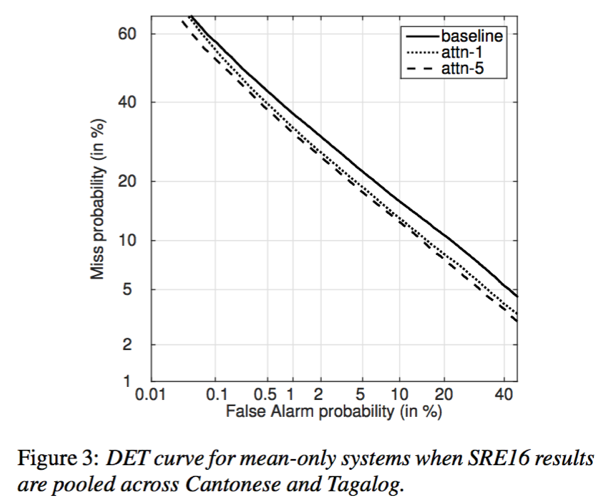
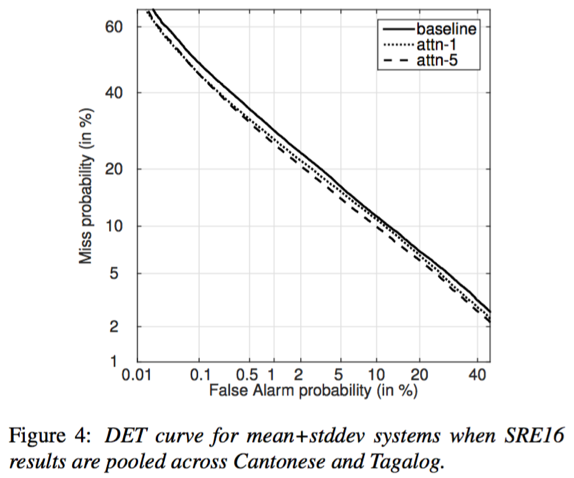
- test segments越长时,包含说话人信息越多,相应的说话人确认效果越好
结论:
本文提出了基于self-attention的x-vector结构,将之前的等权重的均值转化为带权重的均值向量,并且通过增加head个数可以使模型学到更多具有说话人区分性的特征;在文本无关说话人验证任务实验中,该方法取得了比x-vector更好的效果。
Reference: