论文:
TEXT-INDEPENDENT SPEAKER VERIFICATION USING 3D CONVOLUTIONAL NEURAL NETWORKS
思想:
本文提出了一种采用3D-CNN进行文本无关说话人验证任务的架构,相较于2D-CNN,3D-CNN增加了一个维度,使得网络能够一次性接受某个说话人的多个样本。这种策略相比于d-vector,一方面不需要逐个计算说话人每个样本的特征表达后再取平均;另一方面,使得网络模型对说话人内部变化和外部环境变化具有更好的鲁棒性
模型:该算法采用多层3D-conv结构,中间穿插pooling层缩减特征尺寸,最后才有全连阶层将特征转化到易于分类的空间,损失函数为CE交叉熵
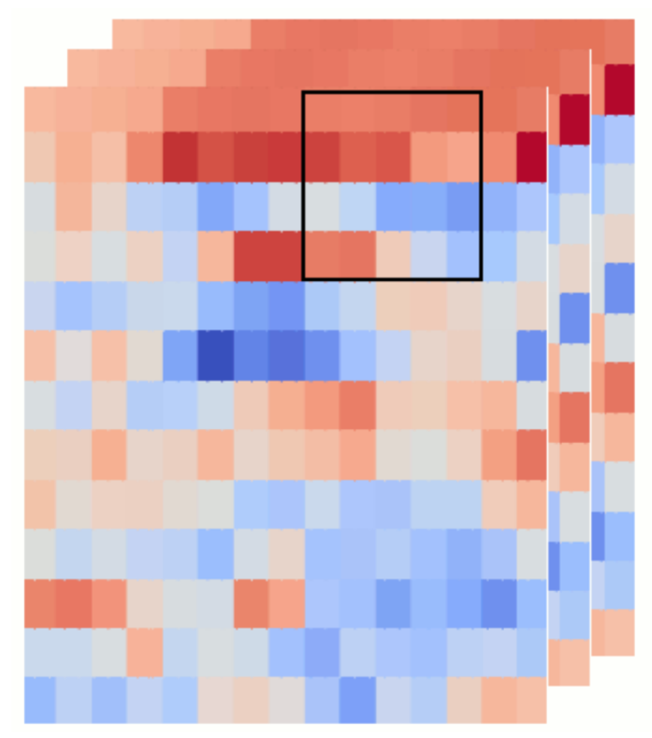
- 3D-conv: 包含三个维度,第一个维度包含说话人的多个样本,第二个维度为时间帧,第三个维度为频域特征
- 池化层:缩减数据尺寸,减少模型参数
- 全连接层:将特征转化到易于分类的空间
训练:
- 数据集:WVU-Multimodal 2013 dataset
- 前置处理:VAD[1]去静音
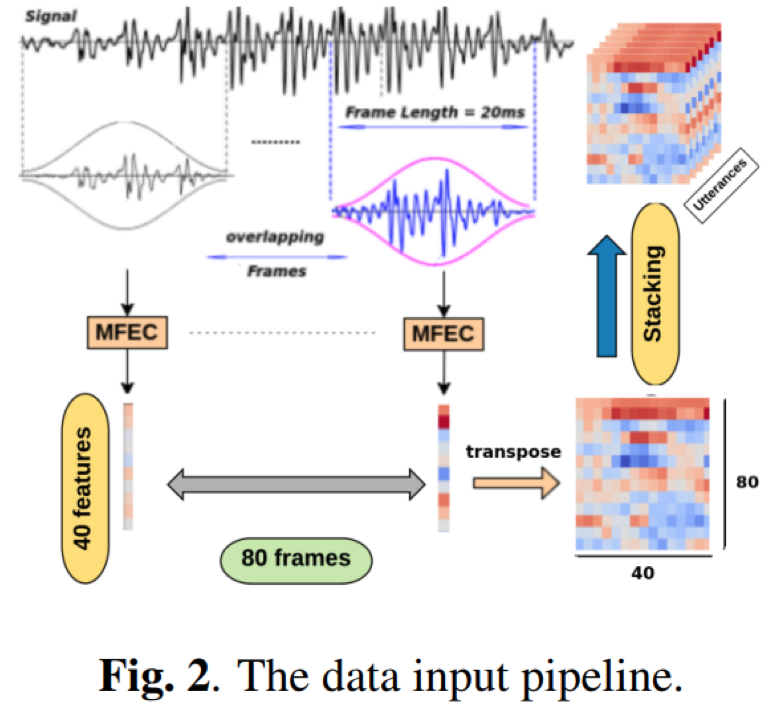
- 输入特征:40维MFEC,等同于fbank,相当于去掉DCT变换的MFCC,作者的解释是MFCC的DCT变换会破坏特征的局部特征,对卷积的局部特征建模建模不理;也就是我们常说的DCT变换的去相关特征
- 输入序列: ζ × 80 × 40 ,其中ζ 表示说话人的句子个数,80为样本的输入帧数(对应800ms),40为MFEC特征维度;ζ 一般取30
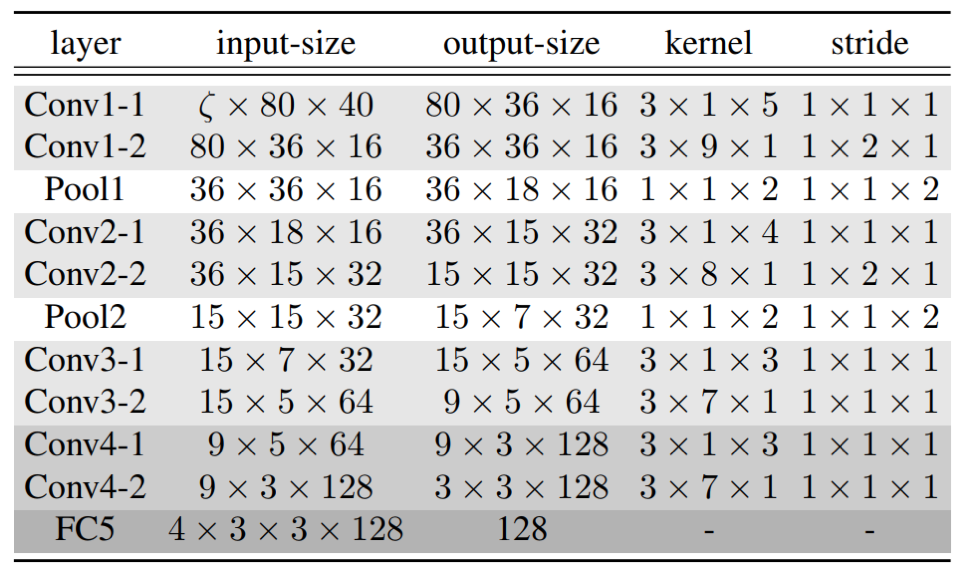
- 网络参数:8*3D-conv+2*maxpooling+1*fc
- test:测试时,以ζ=20为例,注册阶段可以将说话人注册句子一次性输入,直接得到说话人特征表达,无须像d-vector那样逐一输入后取平均;测试句子一般为1,由于ζ=20,所以将测试句子复制20次,一起输入到3D-CNN中提取特征
实验:
- 增加输入序列的句子个数有助于提升识别效果,但是当达到一定数目后继续增加个数,无益于结果的提升
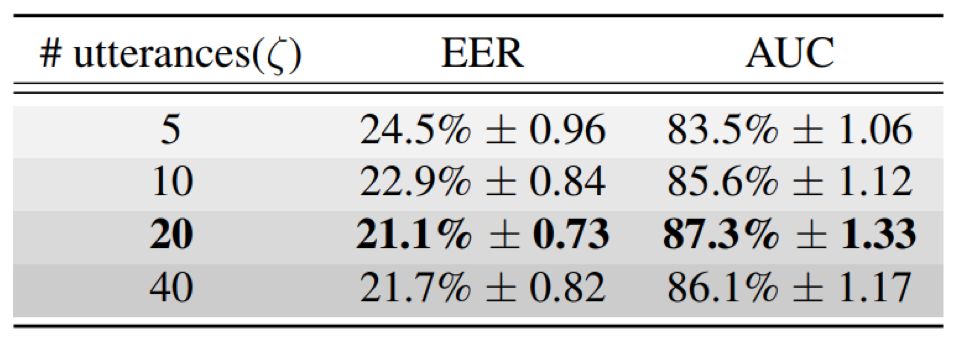
- 3D-CNN结构相比于d-vector、LSTM等结构能够取得更好的实验结果,得益于其3D-conv的使用,可以一次性输入说话人的多个句子,使得网络能够提取到说话人更多、更丰富的特征,以便更好的对说话人内部变化进行建模,提升模型鲁棒性
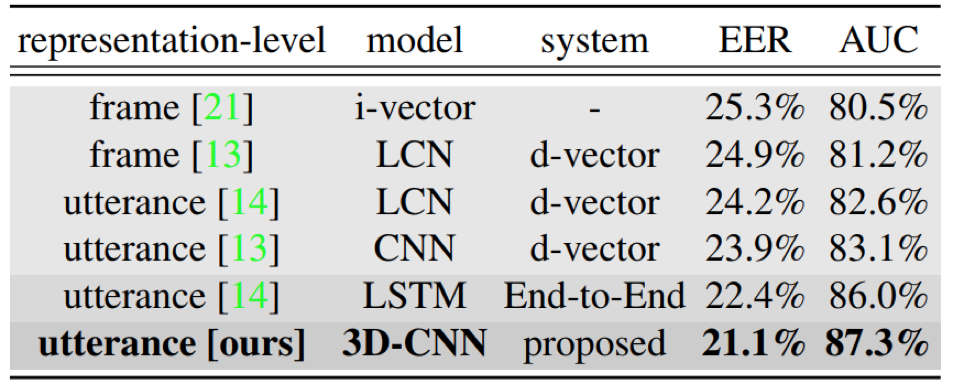
结论:
本文提出了使用3D-CNN处理文本无关说话人验证的任务,3D-CNN的好处是可以一次性输入说话人的多个句子,使得网络能够提取到说话人更多、更丰富的特征,从而更好的对说话人内部变化进行建模,提升模型鲁棒性;此外,相比于d-vector,不需要再逐一输入注册句子,然后取平均,可以一次性输入到网络中,直接得到代表该说话人的特征表达
关于3D-CNN的实践,可参考


Reference: