集合继承结构图
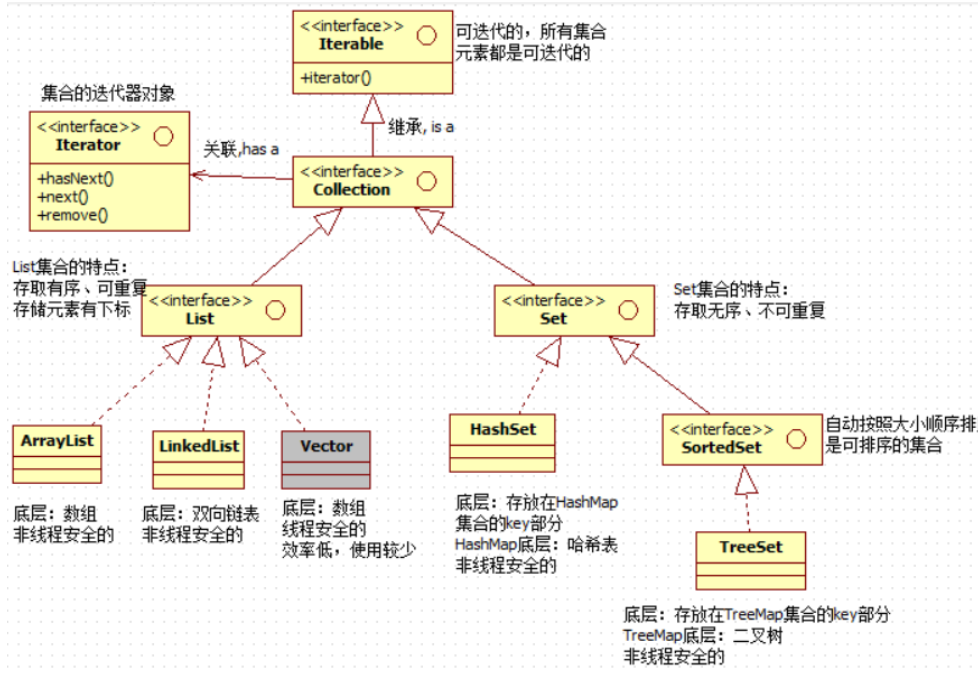
Collection接口
1.Collection中能存放什么元素?
没有使用"泛型"之前,Collection中可以存储Object的所有子类型
使用之后,只能存储某个具体类型
2.常用方法
- boolean add(E e) :可以添加任意引用类型
- void clear() :清除集合中所有元素
- int size()
- boolean isEmpty()
- boolean contains(Object o) :使用equals方法判断
- boolean remove(Object o) :先使用equals方法判断相等,在删除
- Object[] toArray() :转换成Object数组
测试程序:
public class CollectionTest01 {
public static void main(String[] args) {
//Conllection类通用的遍历方法
Collection c = new HashSet();
c.add("aaa");
c.add("dd");
c.add(new Object());
//contains的底层使用equals方法,准确的说是每一个元素的引用.equals(参数);
//所以尽量每一个自定义类都需要重写equals方法
System.out.println(c.contains("aaa"));
//复习:Integer类的equals方法:拆箱之后再使用==
//如果直接对Integer使用==,判断的是内存地址
c.add(new Integer(10000));
Integer y = 10000;
System.out.println(c.contains(y));
}
}
Iterator迭代器
Collection中重要方法:
- Iterator
iterator() :获取集合的迭代器
迭代器的三个常用方法:
- boolean hasNext() :如果仍有元素可以迭代,则返回 true。
- E next() :返回迭代的下一个元素。
- void remove() :从迭代器指向的 collection 中移除迭代器返回的最后一个元素(可选操作)。
示例程序:
public class CollectionTest02 {
public static void main(String[] args) {
Collection c = new ArrayList();
//此时获取的迭代器,指向的是集合中没有元素状态下的迭代器。
//一定要注意:集合结构只要发生改变,迭代器必须重新获取
//如果还是使用老的,就会出现异常java.util.ConcurrentModificationException
Iterator it = c.iterator();
c.add(1);
c.add("ADFDF");
c.add("33");
//重新获取
it = c.iterator();
while(it.hasNext()){
Object obj = it.next();
System.out.println(obj);
}
//通俗的说
//迭代器相当于获得了集合的一个快照,迭代器在迭代过程中会不断对比快照和原集合,如果有不同就会报异常
//而使用集合的remove方法,会使得原集合的结构发生改变,从而使快照和集合不同,报异常(迭代器没有更新)
//使用迭代器的remove方法,会将快照和原集合的对应元素同时删掉(自动更新迭代器,并更新集合)
it = c.iterator(); //重新获取迭代器
while(it.hasNext()){
Object o = it.next();
//使用迭代器来删除迭代器指向的当前元素
it.remove();
}
System.out.println(c.size());
}
}
List接口
常用方法:
- void add(int index,Object element)
- Object get(int index)
- int indexOf(Object o) 获取指定对象第一次出现处的索引
- int lastIndexOf(Object o) 获取指定对象最后一次出现处的索引
- Object remove(int index)
- Object set(int index, Object element) 修改指定位置的元素
示例程序:
public class ListTest01 {
public static void main(String[] args) {
List myList = new ArrayList();
//添加元素
myList.add("A");
myList.add("B");
myList.add("C");
myList.add("D");
//在指定位置添加元素(第一个参数是下标)
myList.add(1,"b"); //效率低,所以使用少
//List接口下的集合都有下标,可使用此方式遍历集合
for (int i = 0; i < myList.size(); i++) {
System.out.println(myList.get(i));
}
//获取指定对象第一次出现处的索引
System.out.println(myList.indexOf("D"));
//获取指定对象最后一次出现处的索引
System.out.println(myList.lastIndexOf("D"));
//删除指定下标的元素
myList.remove(0);
System.out.println(myList.size());
//修改指定位置的元素
myList.set(0,"Hello");
}
}
List接口下的三个类
ArrayList-(最常用)
1.基本知识
- ArrayList采用数组的数据结构,底层是Object[]
- 是非线程安全的
- ArrayList集合初始化容量是10,扩容到原容量的1.5倍,建议给合适的初始化容量
- 查找效率最高,动态修改效率低
2.构造方法:
- new ArrayList()
- new ArrayList(int initialCapacity) :参数是初始化容量
- new ArrayList(Collection c) :HashSet集合没有排序方法,如果想要对HashSet集合排序,必须通过此构造方法转换成List集合
LinkedList
- ArrayList采用链表的数据结构,是非线程安全的
- 动态修改效率高,查找效率低
Vector
- 底层也是一个数组,是线程安全的
- 初始化容量:10;扩容:2倍扩容
示例程序
public class ArrayListTest01 {
public static void main(String[] args) {
//面向接口编程
Collection c = new HashSet();
c.add(100);
c.add(200);
//通过这个构造方法将Hashset集合转换成ArrayList集合
List myList = new ArrayList(c);
for (int i = 0; i < myList.size(); i++) {
System.out.println(myList.get(i));
}
//=======================================================
List list1 = new LinkedList();
list1.add(130);
list1.add(450);
for (int i = 0; i < list1.size(); i++) {
System.out.println(list1.get(i));
}
//=======================================================
List list2 = new Vector();
list2.add(1);
list2.add(2);
for (int i = 0; i < list2.size(); i++) {
System.out.println(list2.get(i));
}
}
}
泛型
1.概述:
- JDK5.0之后的推出的新特性:泛型
- 泛型只在编译阶段起作用,只是给编译器参考的
- JDK8之后引入了:自动类型推断机制,(又称钻石表达式),只需要在声明类型的时候指定类型就可以了
2.泛型的优点:
- 集合中存储的元素类型统一了
- 从集合中取出的元素类型是泛型指定的类型,不需要进行大量的“向下转型”
3.泛型的缺点:
- 导致集合中存储的元素缺乏多样性
- 但是实际使用中,大部分集合中元素的类型还是统一的
4.泛型的意义:
很多时候为了兼容,参数类型都是Object,
在需要调用子类型特有的方法时,需要向下转型
而使用泛型一定程度上减少了向下的类型转换
示例程序:
public class GenericTest01 {
public static void main(String[] args) {
//使用泛型的语法机制
List<Animal> list = new ArrayList<>();
//只允许添加Animal类型的数据
list.add(new Cat());
list.add(new Bird());
//使用迭代器遍历
Iterator<Animal> it = list.iterator();
while(it.hasNext()){
//使用泛型后,在这里不需要进行Object-->Animal的向下类型转换了
Animal a = it.next();
a.move();
}
//使用增强for遍历
for(Animal animal : list){
animal.move();
}
}
}
class Animal{
public void move(){
System.out.println("动物在行走");
}
}
class Cat extends Animal{
public void move(){
System.out.println("猫在走猫步");
}
public String toString(){
return "我是一只猫,我有九条命";
}
}
class Bird extends Animal{
public void move(){
System.out.println("小鸟在飞翔");
}
public String toString(){
return "我是一只鸟";
}
}
自定义泛型
- 自定义类型的时候,<>尖括号中出现的是一个标识符,随便写
- java源代码中经常出现的是:
:Element、 :Type - 用处:减小数据类型的范围,专门处理指定类型的数据,避免过多的向下转型
示例程序:
public class GenericTest03 <标识符>{
public void doSome(标识符 o){
System.out.println(o);
}
public static void main(String[] args) {
//专门处理指定类型的数据
GenericTest03<Cat> gt = new GenericTest03<>();
gt.doSome(new Cat());
GenericTest03<Bird> gt1 = new GenericTest03<>();
gt1.doSome(new Bird());
}
}
Collections工具类
两个常用静态方法:
- List
synchronizedList(List list):将非线程安全集合变成线程安全的 - void sort(List
list) - void sort(List
list, Comparator<? super T> c)
示例程序:
public class CollectionsTest01 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
//变成线程安全的
Collections.synchronizedList(list);
//排序
list.add("zd");
list.add("dd");
Collections.sort(list);
//对HashSet集合排序
Set<String> set = new HashSet<>();
set.add("as");
set.add("afs");
//通过如下构造方法
//public ArrayList(Collection<? extends E> c)
//将Set转换成List,然后再进行排序
List<String> list2 = new ArrayList<>(set);
Collections.sort(list2);
for(String s: list2){
System.out.println(s);
}
}
}
总结 -排序
- 自定义类想要排序首先必须实现Comparable接口或者编写比较器类
- List接口下的类通过Collections工具类中的sort()排序
- HashSet、HashMap想要排序,需要先转换成List集合,再通过Collections工具类中的sort()排序
- TreeSet、TreeMap可以自动排序