集群成员关系:
Kafka使用zookeeper维护集群成员信息,每个broker拥有唯一标识符,这个标识符可以在配置文件里指定也可以自动生成,会注册到Zookeeper的/brokers/ids路径下
控制器:
本质就是一个broker,但是还负责分区首领选举
Kafka使用zookeeper的临时节点来选举控制器,并在节点加入集群或退出集群时通知控制器,控制器负责在节点加入或离开集群时进行分区首领的选举。控制器使用epoch来避免脑裂
复制:
复制功能时Kafka架构核心
Kafka使用主题来组织数据,每个主题分为若干分区,每个分区有多个副本,保存在broker上,每个broker可以保存成千上百属于不同主题和分区的副本
副本有以下2个类型:
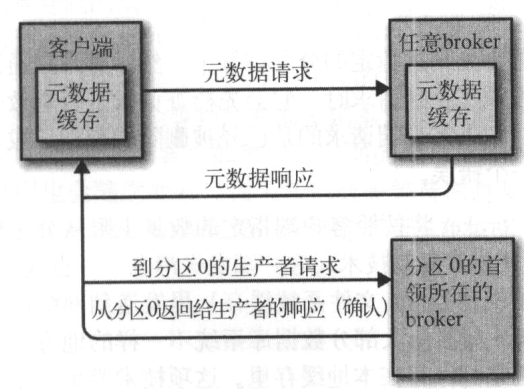
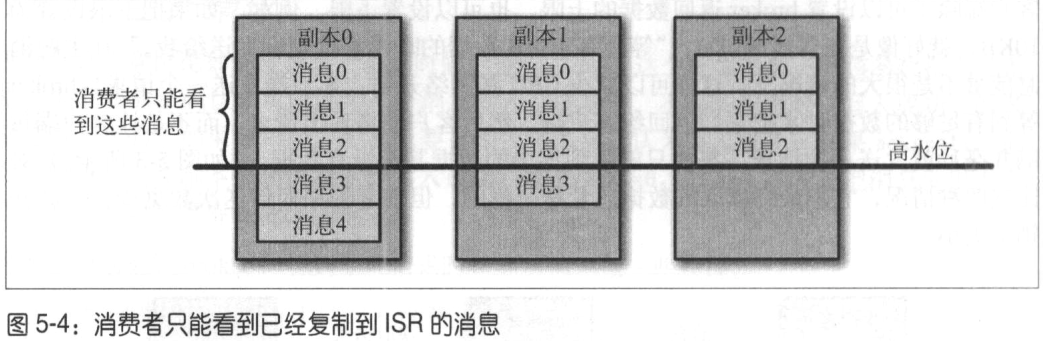
首领副本: 每个分区都有一个首领副本,所有的生产者请求和消费者请求都会经过这个副本
跟随者副本:首领以外的副本都是跟随者副本,跟随者副本唯一任务是从首领那里复制消息,保持与首领一致的状态
只有持续请求得到消息的副本被称为同步的副本,首领失效时才有机会成为首领
除了当前首领之外,每个分区还有一个首选首领-------创建主题时选定的首领就是分区的首选首领
auto.leader.rebalance.enable=true 会检查首选首领是不是当前首领,如果不是,并且该副本是同步的,就会触发首领选举,让首选首领成为首领
分区的副本清单里第一个副本一般就是首选首领
处理请求:
broker大部分工作就是处理客户端/分区副本/控制器发送给分区首领的请求。Kafka提供了一个基于TCP的二进制协议,指定请求消息的格式以及broker如何对请求做出响应
客户端发起连接并发送请求,broker处理请求并做出响应,broker按照请求到达顺序处理他们----这种顺序保证让Kafka具有消息队列的特性,同时保证保存的消息也是有序的
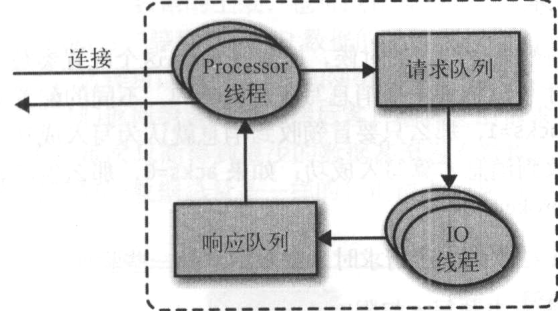
broker会在监听的每一个端口上运行一个Acceptor线程,这个线程会创建一个连接,并交给Processor线程处理,processor线程也称为网络线程,负责从客户端获取请求消息,放进请求队列,然后从响应队列获取响应消息,发送给客户端
索引:
索引把偏移量映射到片段文件和偏移量在文件里的位置
索引若出现损坏,Kafka会自动重新生成索引
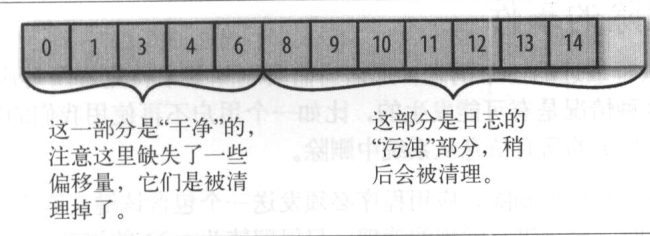
每个日志片段可以分为2个部分:
干净的部分 未清理过,每个键只有一个对应的值
污浊的部分 这些消息是上一次清理之后写入的
log.clear.enabled=true kafka启用清理功能