缓存雪崩和缓存穿透并不是一个概念
缓存雪崩
当缓存失效或缓存数据还没有准备就绪时,高并发请求接入时无法阻挡,从而接入数据库导致数据库宕机或者延迟,而数据库又被大量其他服务所依赖导致大面积服务崩溃,最终导致整个系统或网站的崩溃。
解决方案:
1、分布式锁:只有一个线程能获得锁,获得后判断缓存数据是否存在,不存在获取缓存数据并更新缓存,存在获得数据,其他线程阻塞,更新缓存完成后或获得数据后释放锁
2、数据预热:提前将数据缓存好,不等用户请求再缓存数据,如果数据量大,启动后运维手动触发,数据量不大,启动自动加载
3、缓存双层降级策略:当缓存C1失效时,请求缓存备份C2,C1失效时间短,C2失效时间长
4、错峰更新缓存:更新缓存和用户请求高峰期错峰,定制更新策略
5、设置不同的过期时间,让缓存失效时间尽量均匀,这样不会大量用户同时缓存失效
缓存雪崩只对非常高并发的场景才会发生,一般流量的场景不会很严重,然后缓存穿透对一般流量的场景的影响也非常严重
缓存穿透
没有命中一个数据(没查到),导致再查还是没查到直接将大量请求放到数据库上
解决方案:
1、缓存空数据,并设置合适的过期时间以更新缓存
2、布隆过滤器排除不可能有缓存值的请求
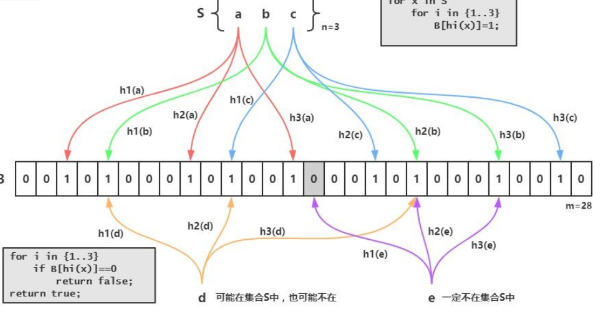
布隆过滤器:将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力
一条很长的信息通过多个hash函数将其转化为一个bit向量,根据向量的结果判断这条信息是否存在。
优点:
省空间:位很省空间,一个很长的东西就变成了几位
省时间:判断、操作位很快,hash算法转化成位向量也很快
缺点:
牺牲了一定的准确度以下是guava实现的布隆过滤器的使用方法:
private BloomFilter<String> bf; //创建布隆过滤器(默认3%误差) bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), allUsers.size()); bf.put(userDto.getUserName()); if(!bf.mightContain(randomUser)){ System.out.println("bloom filter don't has this user"); return; }
综合解决方案
说明:部分思路参考京东到家最佳实践

这个图中主要是分布式锁和缓存空值的方式来方式雪崩、穿透
这里主要说明一下分布式锁的细节:获得锁的线程才有机会更新缓存,而没有获得锁的线程在没有出现“死锁问题”的情况下只能等待第一个获得锁的线程将缓存数据准备好,直接享受缓存数据了那么有两种情况对锁的获取是不同的:
情况1:并发请求(多个请求)对应DB的查询对象是同一个
这种情况,并发请求可以竞争同一把锁,比如一个省的用户查询的配置信息都是一致的,那么这个key就可以以省为单位比如110config,一省用户的并发请求都去抢这个110config的锁
情况2:并发请求(多个请求)对应DB查询对象是多个(极端情况1对1)
这种情况,不可以所有并发请求都争抢一把锁,这样逻辑不正确,比如每个用户都有自己的订单数据,每个用户查询数据库的结果也都是不一样的,那么这个key就不能以省为单位,否则缓存的结果就肯定不正确
同样也不可以每个用户(并发请求时,每个用户一次请求,而不是每个用户多次请求)各自都有一把锁,假如1W人同时请求,有1W个请求,如果再设置1W把锁,缓存同时失效的话还是会同时有1W次请求放入DB,DB无法承受,那么这种情况可以让这1W人,争抢128个锁,抢到锁的请求,才有可能去更新缓存
//锁的数量 锁的数量越少 每个用户对锁的竞争就越激烈,直接打到数据库的流量就越少,对数据库的保护就越好,如果太小,又会影响系统吞吐量,可根据实际情况调整锁的个数
public static final String[] LOCKS = new String[128]; //在静态块中将128个锁先初始化出来 static { for (int i = 0; i < 128; i++) { LOCKS[i] = "lock_" + i; } }
try{
if(exists(cacheKey)){
return cacheData;
}
String[] locks = OrderRedisKey.LOCKS;
//hash分组//缓存中没有,就先上锁,锁的粒度是根据用户Id的hashcode和127取模,这里是个hash的算法,相当于把userID均匀的分布于0-127之间
//a % (2^n) 等价于 a & (2^n - 1) 与运算的前提是2的n次方-1才与%等价,与运算比算术运算更快
int index = userId.hashCode() & (locks.length - 1);
lock(locks[index]);//竞争锁
if(exists(cacheKey)){
return cacheData;
}
data=getFromDB();
if(data == null){
//缓存空数据,并设定缓存过期时间
addcahce(cacheKey,null,ttl_null);
}else{
//缓存数据,并设定缓存过期时间
addcahce(cacheKey,data,ttl_notnull);
}
return data;
}finally{
unlock(locks[index])
}