ZooKeeper
一、分布式概述
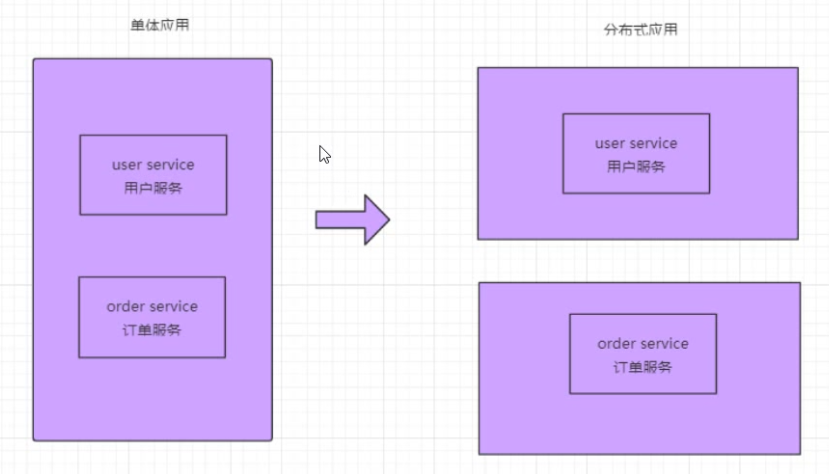
早期我们使用单体架构,即所有服务器部署在一台服务器的一个进程中,随着互联网的发展,逐步演进为分布式架构,多个服务器分别部署在不同机器的不同进程中。
二、ZooKeeper概述
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
三、CAP原则
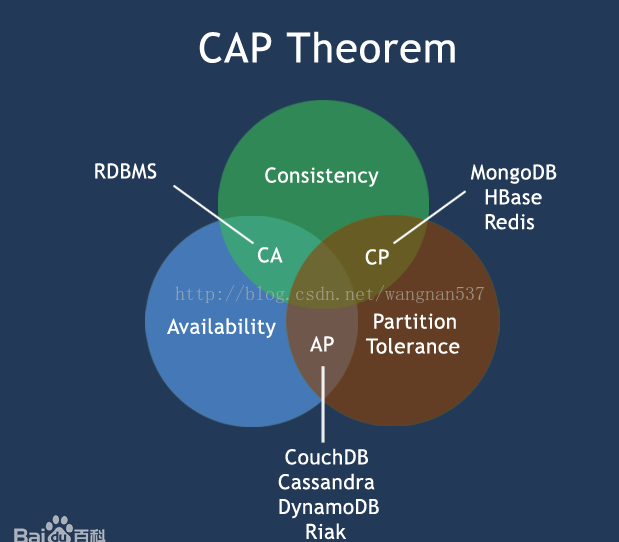
CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
-
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
-
分区容忍性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
CAP原则的精髓就是要么AP,要么CP,要么AC,但是不存在CAP。如果在某个分布式系统中数据无副本, 那么系统必然满足强一致性条件, 因为只有独一数据,不会出现数据不一致的情况,此时C和P两要素具备,但是如果系统发生了网络分区状况或者宕机,必然导致某些数据不可以访问,此时可用性条件就不能被满足,即在此情况下获得了CP系统,但是CAP不可同时满足 [1] 。
四、一致性协议
事务需要跨多个分布式节点时,为了保证事务的ACID特性,需要选举出一个协调者来协调分布式各个节点的调度,基于这个思想衍生出多种一致性协议。
4.1、2PC 二阶段提交
2PC即Two-Phase Commit,二阶段提交。广泛应用在数据库领域,为了使得基于分布式架构的所有节点可以在进行事务处理时能够保持原子性和一致性。绝大部分关系型数据库,都是基于2PC完成分布式的事务处理。
顾名思义,2PC分为两个阶段处理,
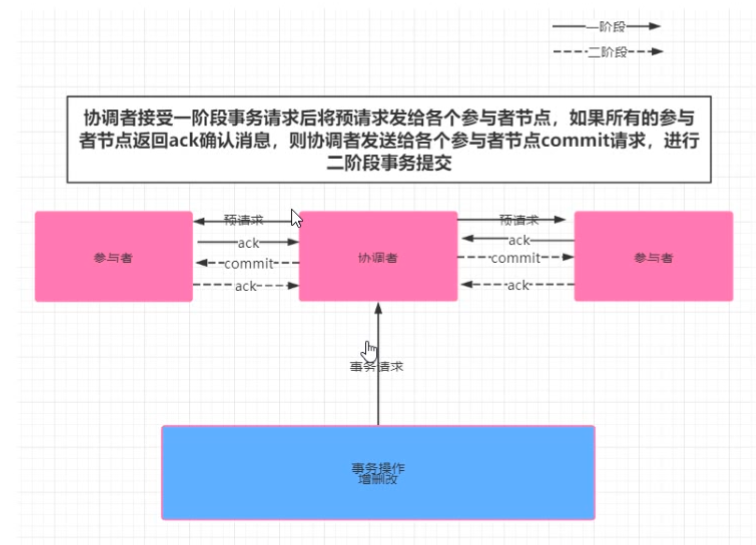
阶段一:提交事务请求
- 事务询问。协调者向所有参与者发送事务内容,询问是否可以执行提交操作,并开始等待各参与者进行响应;
- 执行事务。各参与者节点,执行事务操作,并将Undo和Redo操作计入本机事务日志;
- 各参与者向协调者反馈事务问询的响应。成功执行返回Yes,否则返回No。
阶段二:执行事务提交
协调者在阶段二决定是否最终执行事务提交操作。这一阶段包含两种情形:
执行事务提交
所有参与者reply Yes,那么执行事务提交。
- 发送提交请求。协调者向所有参与者发送Commit请求;
- 事务提交。参与者收到Commit请求后,会正式执行事务提交操作,并在完成提交操作之后,释放在整个事务执行期间占用的资源;
- 反馈事务提交结果。参与者在完成事务提交后,写协调者发送Ack消息确认;
- 完成事务。协调者在收到所有参与者的Ack后,完成事务。
中断事务
事情总会出现意外,当存在某一参与者向协调者发送No响应,或者等待超时。协调者只要无法收到所有参与者的Yes响应,就会中断事务。
- 发送回滚请求。协调者向所有参与者发送Rollback请求;
- 回滚。参与者收到请求后,利用本机Undo信息,执行Rollback操作。并在回滚结束后释放该事务所占用的系统资源;
- 反馈回滚结果。参与者在完成回滚操作后,向协调者发送Ack消息;
- 中断事务。协调者收到所有参与者的回滚Ack消息后,完成事务中断。
2PC具有明显的优缺点:
优点主要体现在实现原理简单;
缺点比较多:
-
2PC的提交在执行过程中,所有参与事务操作的逻辑都处于阻塞状态,也就是说,各个参与者都在等待其他参与者响应,无法进行其他操作;
-
协调者是个单点,一旦出现问题,其他参与者将无法释放事务资源,也无法完成事务操作;
-
数据不一致。当执行事务提交过程中,如果协调者向所有参与者发送Commit请求后,发生局部网络异常或者协调者在尚未发送完Commit请求,即出现崩溃,最终导致只有部分参与者收到、执行请求。于是整个系统将会出现数据不一致的情形;
-
保守。2PC没有完善的容错机制,当参与者出现故障时,协调者无法快速得知这一失败,只能严格依赖超时设置来决定是否进一步的执行提交还是中断事务。
4.1、3PC 三阶段提交
针对2PC的缺点,研究者提出了3PC,即Three-Phase Commit。作为2PC的改进版,3PC将原有的两阶段过程,重新划分为CanCommit、PreCommit和do Commit三个阶段。
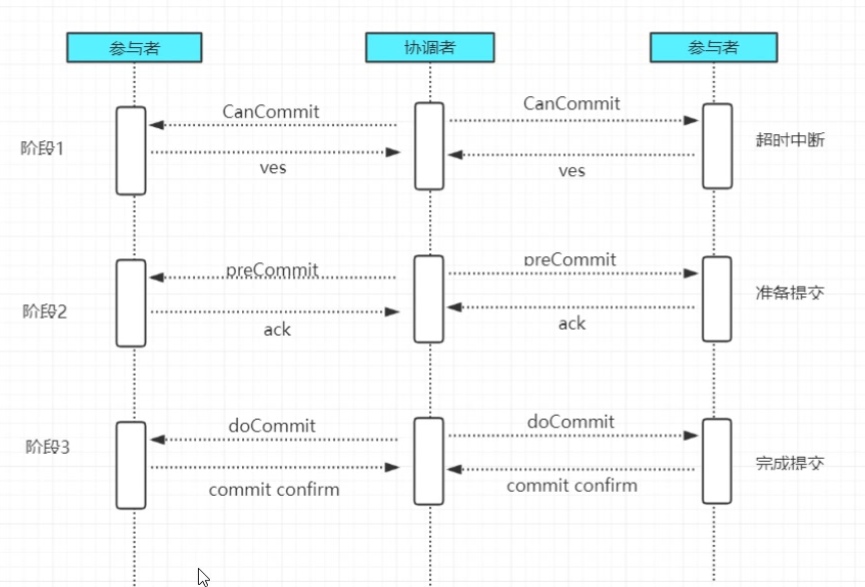
阶段一:CanCommit
- 事务询问。协调者向所有参与者发送包含事务内容的canCommit的请求,询问是否可以执行事务提交,并等待应答;
- 各参与者反馈事务询问。正常情况下,如果参与者认为可以顺利执行事务,则返回Yes,否则返回No。
阶段二:
在本阶段,协调者会根据上一阶段的反馈情况来决定是否可以执行事务的PreCommit操作。有以下两种可能:
执行事务预提交
- 发送预提交请求。协调者向所有节点发出PreCommit请求,并进入prepared阶段;
- 事务预提交。参与者收到PreCommit请求后,会执行事务操作,并将Undo和Redo日志写入本机事务日志;
- 各参与者成功执行事务操作,同时将反馈以Ack响应形式发送给协调者,同事等待最终的Commit或Abort指令。
中断事务
加入任意一个参与者向协调者发送No响应,或者等待超时,协调者在没有得到所有参与者响应时,即可以中断事务:
- 发送中断请求。 协调者向所有参与者发送Abort请求;
- 中断事务。无论是收到协调者的Abort请求,还是等待协调者请求过程中出现超时,参与者都会中断事务;
阶段三:doCommit
在这个阶段,会真正的进行事务提交,同样存在两种可能。
执行提交
- 发送提交请求。假如协调者收到了所有参与者的Ack响应,那么将从预提交转换到提交状态,并向所有参与者,发送doCommit请求;
- 事务提交。参与者收到doCommit请求后,会正式执行事务提交操作,并在完成提交操作后释放占用资源;
- 反馈事务提交结果。参与者将在完成事务提交后,向协调者发送Ack消息;
- 完成事务。协调者接收到所有参与者的Ack消息后,完成事务。
中断事务
在该阶段,假设正常状态的协调者接收到任一个参与者发送的No响应,或在超时时间内,仍旧没收到反馈消息,就会中断事务:
- 发送中断请求。协调者向所有的参与者发送abort请求;
- 事务回滚。参与者收到abort请求后,会利用阶段二中的Undo消息执行事务回滚,并在完成回滚后释放占用资源;
- 反馈事务回滚结果。参与者在完成回滚后向协调者发送Ack消息;
- 中端事务。协调者接收到所有参与者反馈的Ack消息后,完成事务中断。
3PC的优缺点:
3PC有效降低了2PC带来的参与者阻塞范围,并且能够在出现单点故障后继续达成一致;
但3PC带来了新的问题,在参与者收到preCommit消息后,如果网络出现分区,协调者和参与者无法进行后续的通信,这种情况下,参与者在等待超时后,依旧会执行事务提交,这样会导致数据的不一致。
4.3、Paxos算法
paxos算法是基于消息传递且具有高度容错特性的一致性算法。是目前公认的解决分布式一致性问题最有效的算法之一。
在常见的分布式系统中,总会发生诸如机器宕机或网络异常(包括消息的延迟、丢失、重复、乱序,还有网络分区)等情况。Paxos算法需要解决的问题就是如何在一个可能发生上述异常的分布式系统中,快速且正确地在集群内部对某个数据的值达成一致,并且保证不论发生以上任何异常,都不会破坏整个系统的一致性。
角色
- Proposer:议案发起者。
- Acceptor:决策者,可以批准议案。
- Learner:最终决策的学习者。不参与决策。
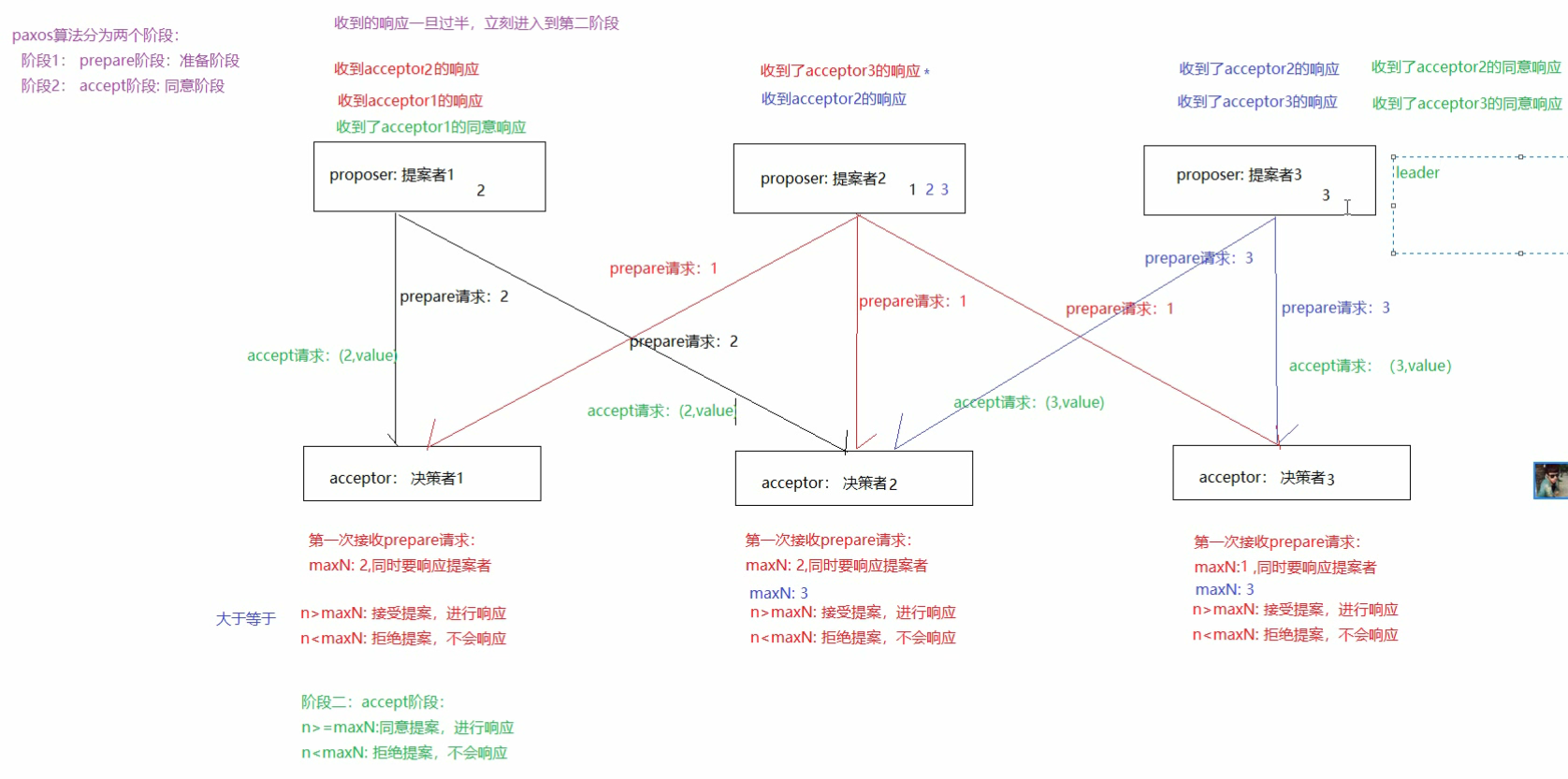
正常流程:
单点故障,部分节点失败
Proposer失败

4.4、ZAB协议(Fast Paxos)
Zab协议 的全称是 Zookeeper Atomic Broadcast (Zookeeper原子广播)。
Zookeeper 是通过 Zab 协议来保证分布式事务的最终一致性。
(1)Zab协议是为分布式协调服务Zookeeper专门设计的一种 支持崩溃恢复 的 原子广播协议 ,是Zookeeper保证数据一致性的核心算法。Zab借鉴了Paxos算法,但又不像Paxos那样,是一种通用的分布式一致性算法。它是特别为Zookeeper设计的支持崩溃恢复的原子广播协议。
(2)在Zookeeper中主要依赖Zab协议来实现数据一致性,基于该协议,zk实现了一种主备模型(即Leader和Follower模型)的系统架构来保证集群中各个副本之间数据的一致性。
这里的主备系统架构模型,就是指只有一台客户端(Leader)负责处理外部的写事务请求,然后Leader客户端将数据同步到其他Follower节点。
ZooKeeper使用单一主进程Leader用于处理客户端所有事务请求,即写请求。当服务器数据发生变更时,集群采用ZAB原子广播协议,以事务提交proposal的形式广播到所有的副本进程,每一个事务分配一个全局的递增的事务编号xid。
若客户端提交的是读请求时,则接受请求的节点直接根据自己保存的数据响应,若是写请求,并且当前节点不是leader,那么该节点就会将请求转发给leader,leader会以提案的方式广播此写请求,如果超过半数的节点同意写请求,则该写请求就会提交,leader会通知所有的订阅者同步数据。
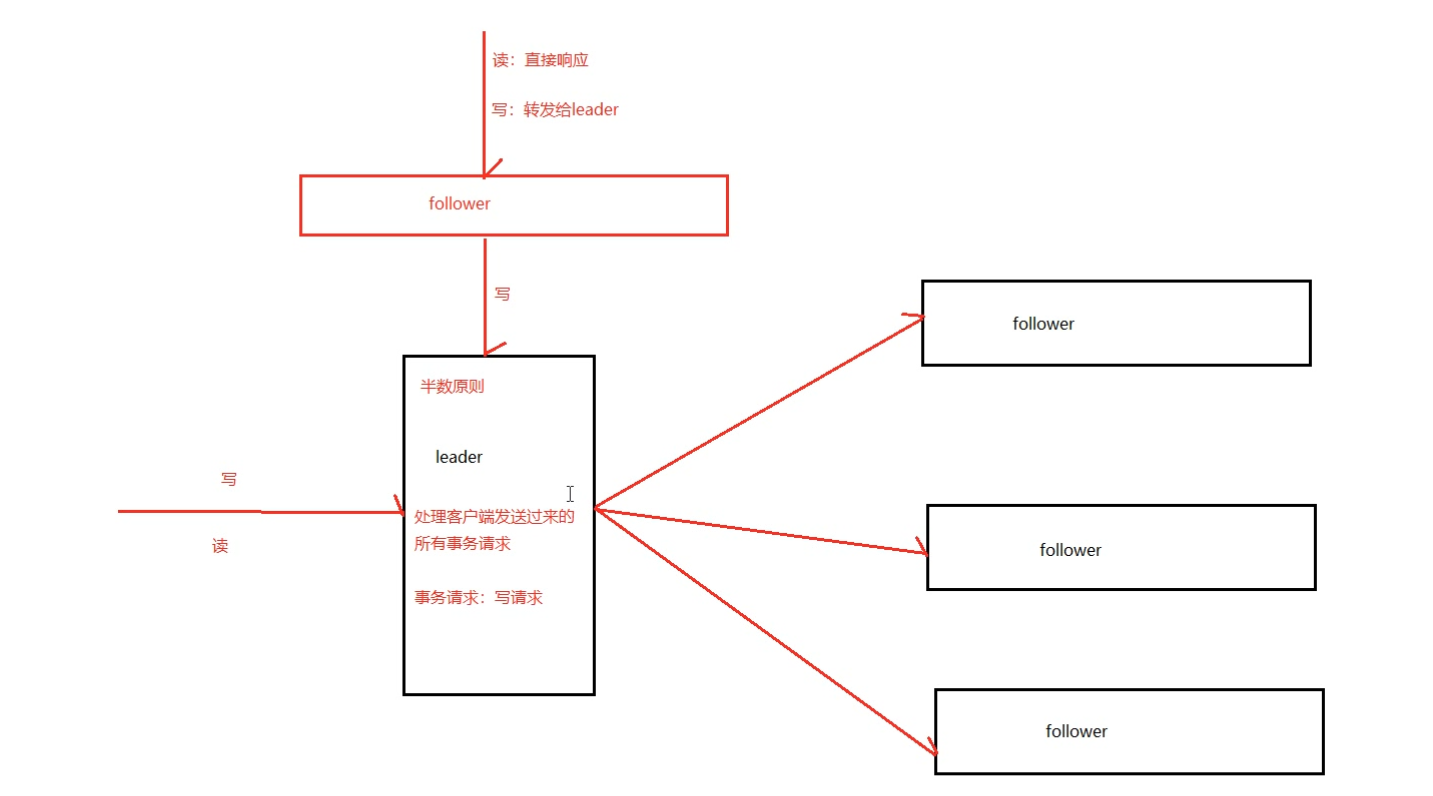
zookeeper的三种角色:
- 群首(leader)
leader负责处理集群的写请求,并发起投票,只有超过半数的节点同意后才会提交该写请求。
- 追随者(follower)
处理读请求,响应结果。转发写请求到leader,在选举leader过程中参与投票。
- 观察者(observer)
observer可以理解为没有投票权的follower,主要职责是协助follower处理读请求。
zookeeper的两种模式:
- 恢复模式
当服务启动或者奔溃后,ZK进入恢复模式。
- 广播模式
一旦leader已经和多数Follower进行了状态同步后,zk进入广播模式。
ZK的leader的选举算法:

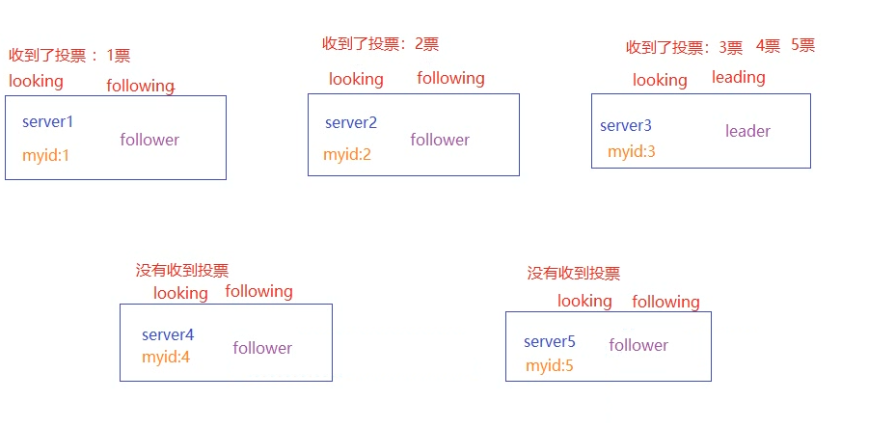

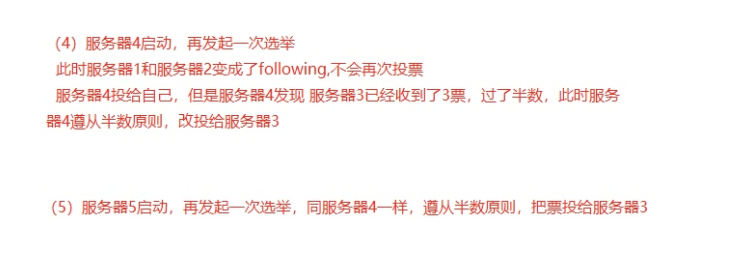
消息广播算法
一旦进入广播模式,集群中肥leader节点接受到事务的请求,首先会将事务请求转发给服务器,leader服务器为其生成对应的事务提案peoposal,并发送给集群中其他节点,如果过半则失误提交。
-
leader接受到消息后,消息通过全局唯一的64位自增事务id,zxid标识。
-
leader发送给follower的提案是有序的,leader会创建一个FIFO队列,将提案顺序写入队列中发送给follower。
-
follower接受到提案后,会比较提案zxid和本地事务日志最大的zxid,若提案zxid比本地事务id大,将提案记录到本地日志中,反馈ack给leader,否则拒绝。
-
leader接收到过半ack后,leader向所有的follower发送commit,通知每个follower·执行本地事务。
五、zookeeper环境搭建
5.1、单机
下载、解压zk
可以去这个网址下载最新的zookeeper:https://downloads.apache.org/zookeeper/,不过要下载带bin的,不带bin是源码。
tar -zxvf apache-zookeeper-3.6.2-bin.tar.gz #解压
cd apache-zookeeper-3.6.2-bin
mkdir data #在apache-zookeeper-3.6.2-bin目录下新建data文件夹。
配置zk
cd conf #进入配置文件夹
mv zoo_sample.cfg zoo.cfg #修改配置文件名称
vim zoo.cfg #修改配置文件
dataDir=/home/apache-zookeeper-3.6.1-bin/data #将zoo.cfg 文件中的dataDir改成新建data的目录
启动、停止命令zk
#进入apache-zookeeper-3.6.1下的bin目录
./zkServer.sh start #启动zk
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /home/apache-zookeeper-3.6.1-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
#启动成功之后查看状态
./zkServer.sh status #查看状态
ZooKeeper JMX enabled by default
Using config: /home/apache-zookeeper-3.6.1-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: standalone #说明单机启动成功
#还可以输入jps查看,QuorumPeerMain就是zookeeper的主程序。
jps
10451 QuorumPeerMain
10741 Jps
#也可以使用
./zkServer.sh start-foreground #带日志启动
./zkServer.sh stop #停止zk
ZooKeeper JMX enabled by default
Using config: /home/apache-zookeeper-3.6.1-bin/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
5.2、集群
解压zk
新建一个zkcluster文件夹,在其下将zk解压成三个,并且名称zookeeper01、zookeeper02、zookeeper03。在三个zk下都创建data文件夹,修改zoo.cfg配置文件。
需要保证配置文件中出现的端口没有被占用,然后服务器之间的通信端口和投票端口需要被放开,不然无法连接。
[root@zxone zkcluster]# pwd
/home/zkcluster
[root@zxone zkcluster]# ls #zkcluster目录下新建三个目录,将zk分别解压到这个三个目录下
zookeeper-1 zookeeper-2 zookeeper-3
#每个ZK分配不同的端口
#zookeeper01 zoo.cfg sudo netstat -nltp | grep 2181 查看端口占用情况
dataDir=/home/zkcluster/zookeeper-1/data
clientPort=2181
quorumListenOnAllIPs=true
admin.serverPort=8080 #zk启动的端口
#server.服务器ID=服务器IP地址:服务器之间的通信端口:服务器之间的投票端口
server.1=192.168.42.128:2181:3881
server.2=192.168.42.128:2182:3882
server.3=192.168.42.128:2183:3883
#zookeeper02 zoo.cfg
dataDir=/home/zkcluster/zookeeper-2/data
clientPort=2182
quorumListenOnAllIPs=true
admin.serverPort=8081
server.1=192.168.42.128:2181:3881
server.2=192.168.42.128:2182:3882
server.3=192.168.42.128:2183:3883
#zookeeper03 zoo.cfg
dataDir=/home/zkcluster/zookeeper-3/data
clientPort=2183
quorumListenOnAllIPs=true
admin.serverPort=8083
server.1=192.168.42.128:2181:3881
server.2=192.168.42.128:2182:3882
server.3=192.168.42.128:2183:3883
配置集群
(1)在每个zk的data目录下创建一个myid文件,内容分别是1、2、3。这个文件就是记录每个服务器的ID。
(2)在每个zk的zoo.cfg配置客户端(clientPort)和集群服务器IP列表。
#clientPort 上面已经配置好
server.1=192.168.42.128:2181:3881
server.2=192.168.42.128:2182:3881
server.3=192.168.42.128:2183:3881
启动集群
在/home/zkcluster目录下新建start-all.sh集群启动文件,然后对该文件进行授权。当然可以在每个zk的bin目录下通过./zkServer.sh start 启动。
[root@zxone zkcluster]# cat start-all.sh #start-all.sh 文件内容
cd /home/zkcluster/zookeeper-1/bin
./zkServer.sh start
cd /home/zkcluster/zookeeper-2/bin
./zkServer.sh start
cd /home/zkcluster/zookeeper-3/bin
./zkServer.sh start
#执行./start-all.sh 文件,这么就启动了zk集群。
[root@zxone zkcluster]# ./start-all.sh
ZooKeeper JMX enabled by default
Using config: /home/zkcluster/zookeeper-1/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
ZooKeeper JMX enabled by default
Using config: /home/zkcluster/zookeeper-2/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
ZooKeeper JMX enabled by default
Using config: /home/zkcluster/zookeeper-3/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
#进入每个zk的bin目录下通过status查看该zk的角色。
[root@zxone bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/zkcluster/zookeeper-1/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
[root@zxone bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/zkcluster/zookeeper-2/bin/../conf/zoo.cfg
Client port found: 2182. Client address: localhost.
Mode: leader
[root@zxone bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/zkcluster/zookeeper-3/bin/../conf/zoo.cfg
Client port found: 2183. Client address: localhost.
Mode: follower
#通过查看集群状态,可知有一个leader两个follower。
六、ZK的基本使用
6.1、数据结构
ZK数据模型的结构与Unix文件系统很类似,整体上可以看作是一颗树,每个节点称作一个ZNode,每个ZNode都可以通过其路径唯一标识。
Znode有两种类型:
短暂(ephemeral):客户端和服务器端断开连接后,创建的节点自己删除
持久(persistent):客户端和服务器端断开连接后,创建的节点不删除
2)Znode有四种形式的目录节点(默认是persistent )
(1)持久化目录节点(PERSISTENT)
客户端与zookeeper断开连接后,该节点依旧存在
(2)持久化顺序编号目录节点(PERSISTENT_SEQUENTIAL)
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
(3)临时目录节点(EPHEMERAL)
客户端与zookeeper断开连接后,该节点被删除
(4)临时顺序编号目录节点(EPHEMERAL_SEQUENTIAL)
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
6.2、命令行使用
通过zxCli,sh进入zookeeper客户端命令行。输入help查看zookeeper客户端的指令。
./zkCli.sh #进去客户端命令行
[zk: localhost:2181(CONNECTED) 0] ls / #查看节点
[zookeeper]
[zk: localhost:2181(CONNECTED) 1] help #查看zookeeper客户端的指令
ZooKeeper -server host:port cmd args
connect host:port
get path [watch]
ls path [watch]
set path data [version]
rmr path
delquota [-n|-b] path
quit
printwatches on|off
create [-s] [-e] path data acl
stat path [watch]
close
ls2 path [watch]
history
listquota path
setAcl path acl
getAcl path
sync path
redo cmdno
addauth scheme auth
delete path [version]
setquota -n|-b val path
1、使用ls命令查看当前znode中所包含的内容watch监控的是路径变化(只监听一次)
ls path [watch]
2、查看当前节点数据并能看到更新次数等数据信息
ls2 path [watch]
[zk: localhost:2181(CONNECTED) 6] ls2 /
[test, zookeeper]
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x2
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 2
3、创建节点-s含有序-e临时。需要路径和值一起写才能成功。
create /znode路径 节点的值
[zk: localhost:2181(CONNECTED) 3] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 4] create /test testv
Created /test
[zk: localhost:2181(CONNECTED) 5] ls /
[test, zookeeper]
4、获取节点的值,watch 监控节点值的变化(只监听一次)
get path [watch]
[zk: localhost:2181(CONNECTED) 7] get /test
testv
cZxid = 0x2
ctime = Wed Sep 09 13:27:20 CST 2020
mZxid = 0x2
mtime = Wed Sep 09 13:27:20 CST 2020
pZxid = 0x2
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 0
5、设置节点的值
set /znode路径 节点的值
[zk: localhost:2181(CONNECTED) 2] set /test testv-update
[zk: localhost:2181(CONNECTED) 3] get /test
testv-update
6、stat 查看节点状态 (没有节点的值)
stat /znode路径
[zk: localhost:2181(CONNECTED) 4] stat /test
cZxid = 0x2
ctime = Wed Sep 09 13:27:20 CST 2020
mZxid = 0x5
mtime = Wed Sep 09 13:32:14 CST 2020
pZxid = 0x2
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 12
numChildren = 0
7、删除节点,如果该节点下有子节点,就无法删除。
detele /znode路径
8、rmr 递归删除节点
rmr /znode路径
6.2、ZK的API的使用(本次使用在本机上windows安装的ZK)
POM.XML添加ZK依赖
添加的zk依赖最好和使用的zk服务器版本一致。
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.14</version>
</dependency>
ZookeeperConfig.java
/**
* 连接ZK
*/
@Configuration
public class ZookeeperConfig {
private static final Logger logger = LoggerFactory.getLogger(ZookeeperConfig.class);
private final static String ZK_IP="127.0.0.1:2181";//在本地启动的ZK
private final static int SESSION_TIMEOUT=3000;
@Bean(name = "zkClient")
public ZooKeeper zkClient(){
ZooKeeper zooKeeper=null;
try {
final CountDownLatch countDownLatch = new CountDownLatch(1);
//连接成功后,会回调watcher监听,此连接操作是异步的,执行完new语句后,直接调用后续代码
// 可指定多台服务地址 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
zooKeeper = new ZooKeeper(ZK_IP, SESSION_TIMEOUT, new Watcher() {
@Override
public void process(WatchedEvent event) {
if(Event.KeeperState.SyncConnected==event.getState()){
//如果收到了服务端的响应事件,连接成功
countDownLatch.countDown();
}
}
});
countDownLatch.await();
logger.info("【初始化ZooKeeper连接状态....】={}",zooKeeper.getState());
}catch (Exception e){
logger.error("初始化ZooKeeper连接异常....】={}",e);
}
return zooKeeper;
}
}
ZookeeperContoller.java
@RestController
public class ZookeeperController {
/**
* 创建持久化节点
* @return
*/
@PostMapping("/zk/createLastingNode")
public Object createLastingNode(){
Boolean aBoolean = ZkUtil.createLastingNode("/lastingNode","lasting-v");
if(aBoolean){
return "createLastingNode fail";
}else{
return "createLastingNode succss";
}
}
/**
* 创建临时节点
* @return
*/
@PostMapping("/zk/createTemporaryNode")
public Object createTemporaryNode(){
Boolean aBoolean = ZkUtil.createLastingNode("/TemporaryNode","temporary-v");
if(aBoolean){
return "createLastingNode fail";
}else{
return "createLastingNode succss";
}
}
/**
* 删除节点
* @return
*/
@PostMapping("/zk/deleteNode")
public Object deleteNode(){
Boolean aBoolean = ZkUtil.deleteNode("/lastingNode");
if(aBoolean){
return "deleteNode fail";
}else{
return "deleteNode succss";
}
}
/**
* 获取节点的值
* @return
*/
@PostMapping("/zk/getData")
public Object getData(){
String date = ZkUtil.getData("/TemporaryNode",null);
return date;
}
}
ZkUtil.java
@Component
public class ZkUtil {
private static final Logger logger = LoggerFactory.getLogger(ZkUtil.class);
@Qualifier("zkClient") //使用ZookeeperConfig中的bean
@Autowired
private ZooKeeper zooKeeper;
private static ZooKeeper zkClient;
@PostConstruct //目的:初始化静态zkClient对象
private void init(){
zkClient = this.zooKeeper;
}
/**
* 创建持久化节点
* @param path
*/
public static boolean createLastingNode(String path, String data){
try {
zkClient.create(path,data.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
return true;
} catch (Exception e) {
logger.error("【创建持久化节点异常】{},{},{}",path,data,e);
return false;
}
}
/**
* 创建临时节点
* @param path
*/
public static boolean createTemporaryNode(String path, String data){
try {
zkClient.create(path,data.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
return true;
} catch (Exception e) {
logger.error("【创建临时节点异常】{},{},{}",path,data,e);
return false;
}
}
/**
* 删除节点
* @param path
*/
public static boolean deleteNode(String path){
try {
//version参数指定要更新的数据的版本, 如果version和真实的版本不同, 更新操作将失败. 指定version为-1则忽略版本检查
zkClient.delete(path,-1);
return true;
} catch (Exception e) {
logger.error("【删除节点异常】{},{}",path,e);
return false;
}
}
/**
* 获取指定节点的值
* @param path
* @return
*/
public static String getData(String path,Watcher watcher){
try {
Stat stat=new Stat();
byte[] bytes=zkClient.getData(path,watcher,stat);
return new String(bytes);
}catch (Exception e){
e.printStackTrace();
return null;
}
}
}
七、Zookeeper的应用场景
7.1、配置中心
将配置信息存放在zk中的一个节点中,同事给该节点注册一个数据节点变更的watcher监听,一旦节点数据反生变更,所有的订阅该节点的客户端都可以获取数据变更通知。
7.2、负载均衡
建立servers节点,并建立监听器见识servers子节点状态(用于在服务器增添时及时同步当前集群中服务器列表),在每个服务器启动时,在servers节点下简历具体服务器地址的子节点并在对应的子节点下存入服务器的相关信息,这样,我们在zookeeper服务器上就可以获取当前集群中服务器列表及相关信息,可以自定义一个负载均衡算法,在每个请求过来时从zookeeper服务器中获取当前集群服务器列表,根据算法选出其中一个服务器来处理请求。
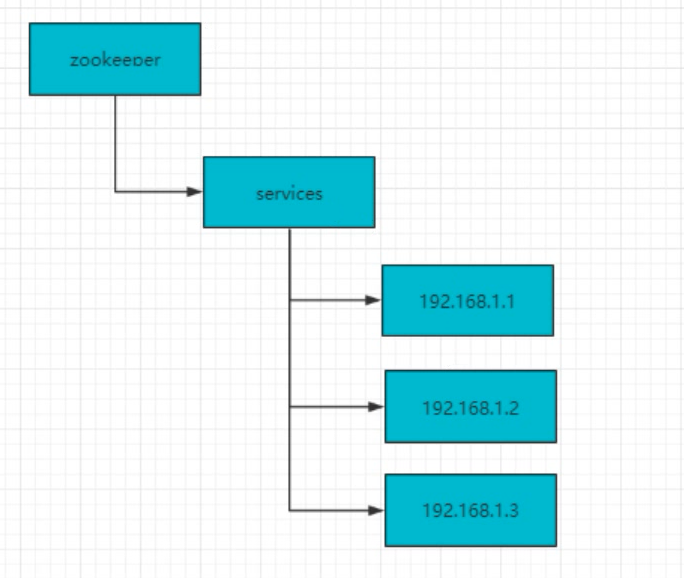
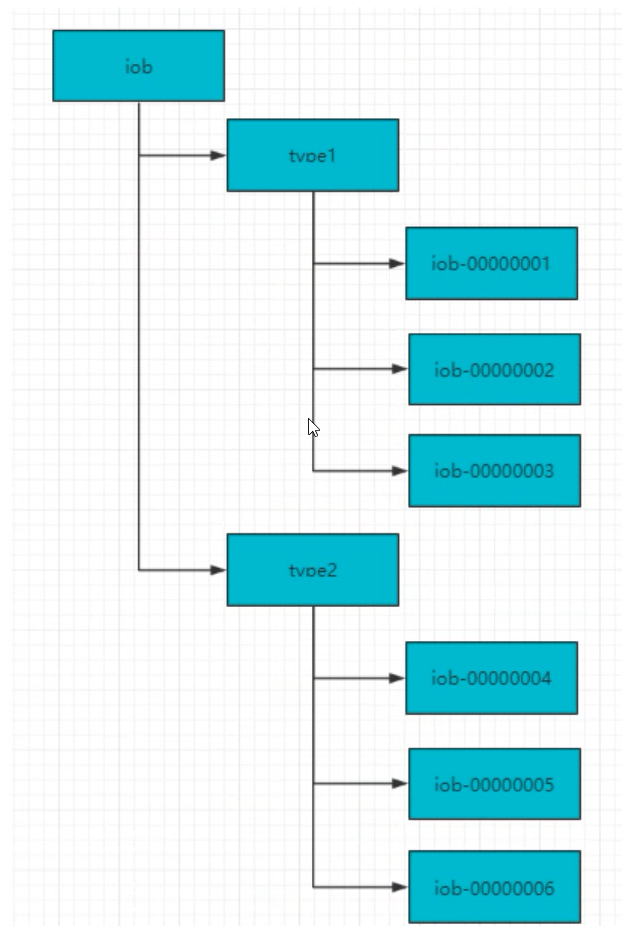
7.3、命名服务
-
在Zookeeper中通过创建顺序节点就可以实现,所以客户端都会根据自己的任务类型来创建一个顺序节点,例如:Job-00000001
-
节点创建完毕后,create()接口会返回一个完整的节点名,例如:Job-00000002
拼接type类型和完整节点名作为全局唯一ID
7.4、DNS服务
- 域名配置
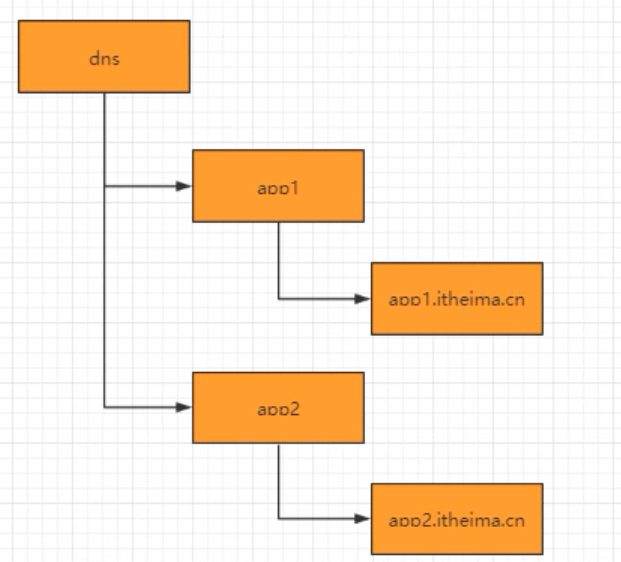
- 域名解析
应用解析时,首先从ZK域名节点中获取域名映射的IP和端口。
- 域名变更
每个应用都会在对应的域名节点注册一个数据变更的watcher监听,一旦监听的域名节点数据变更,zk会向所有订阅的客户端发送域名变更通知。
7.5、集群管理
-
集群控制:对集群中节点进行操作与控制
-
集群监控:对集群节点运行状态的收集
zookeeper集群管理主要利用了watcher机制和创建临时节点来实现。
7.6、分布式锁
7.6.1、数据库实现分布式锁
7.6.2、Redis实现分布式锁
redis分布式锁的实现基于setnx(set if not exists),设置成功,返回1,设置失败返回0,释放锁的操作通过del指令来完成。
redis实现分布式锁存在问题,为了解决redis单点问题,我们会部署redis集群,在Sentinel集群中,主节点突然挂掉了。同时主节点中有把锁还没来得及同步到从节点。这样就会导致系统中同样一把锁被两个客户端同时持有,不安全性由此产生。redis官方为了解决这个问题,推出Redlock算法解决这个问题,但是带来的网络消耗较大。
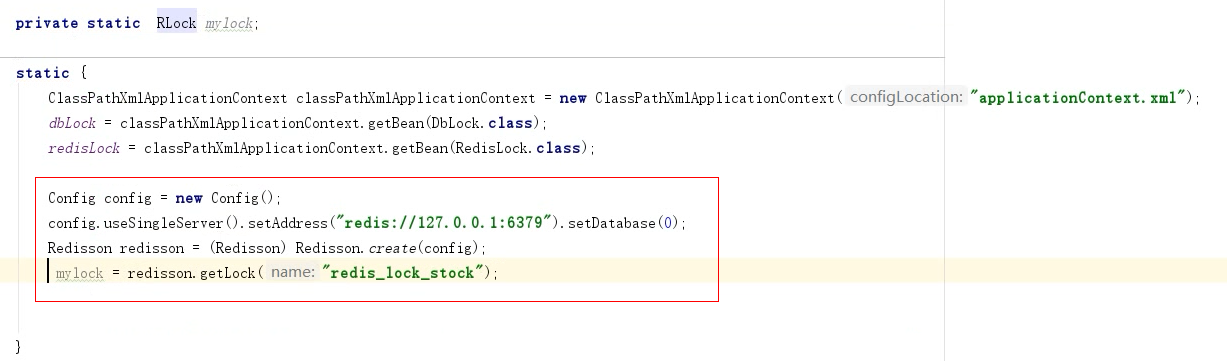
分布式锁的redisson实现:
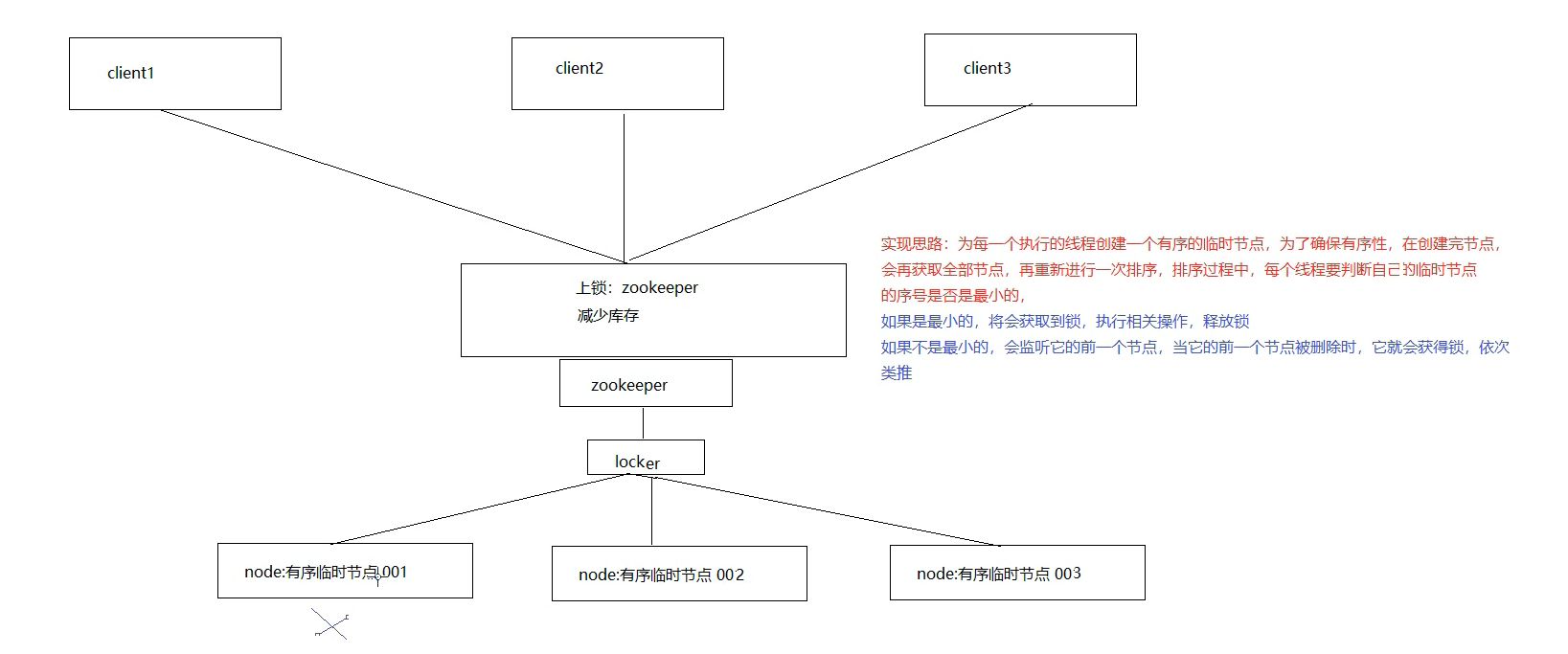
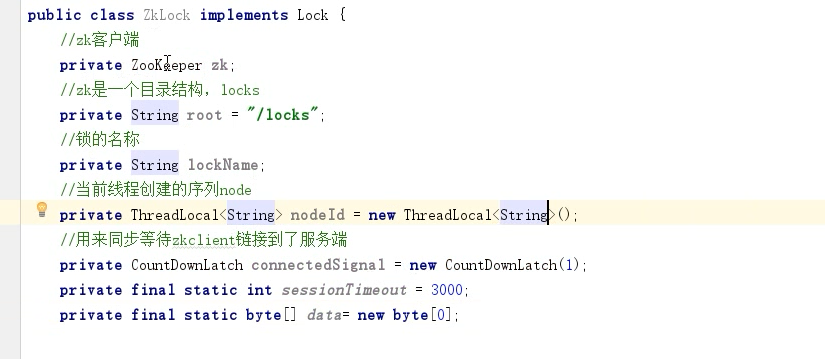
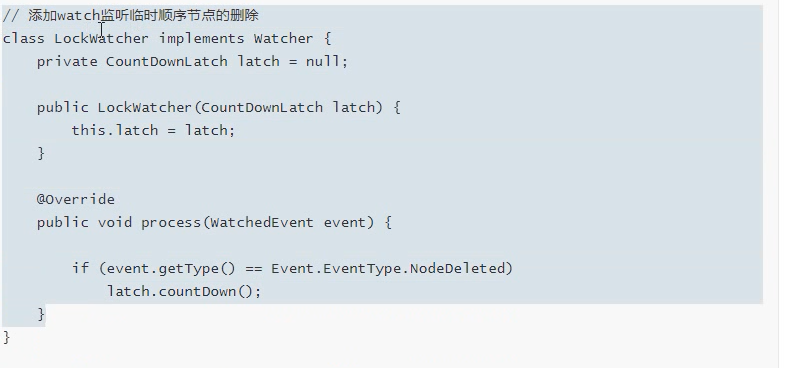
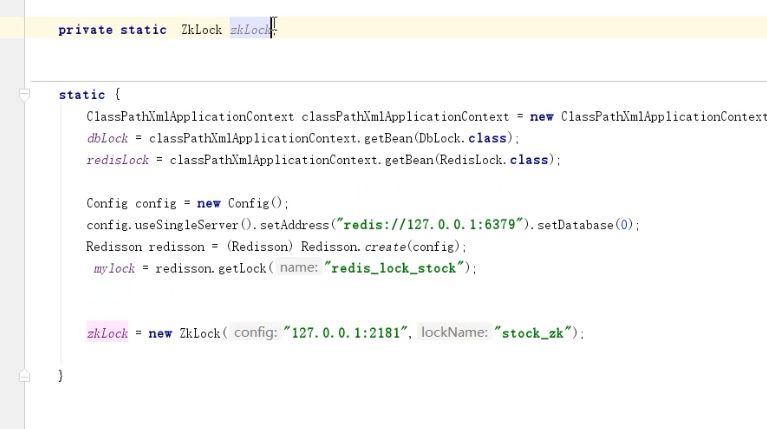
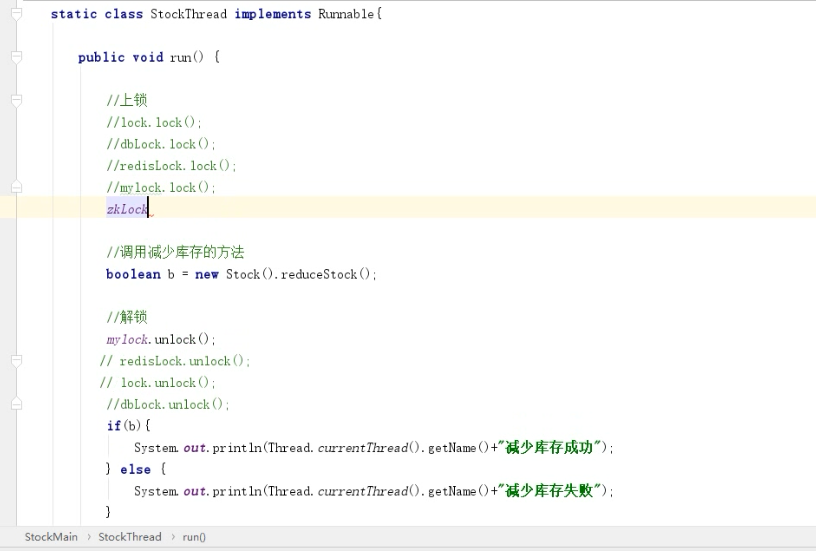
7.6.3、Zookeeper实现分布式锁
原理:zookeeper通过创建临时序列节点来实现分布式锁,适用于顺序执行的程序。
代码实现:



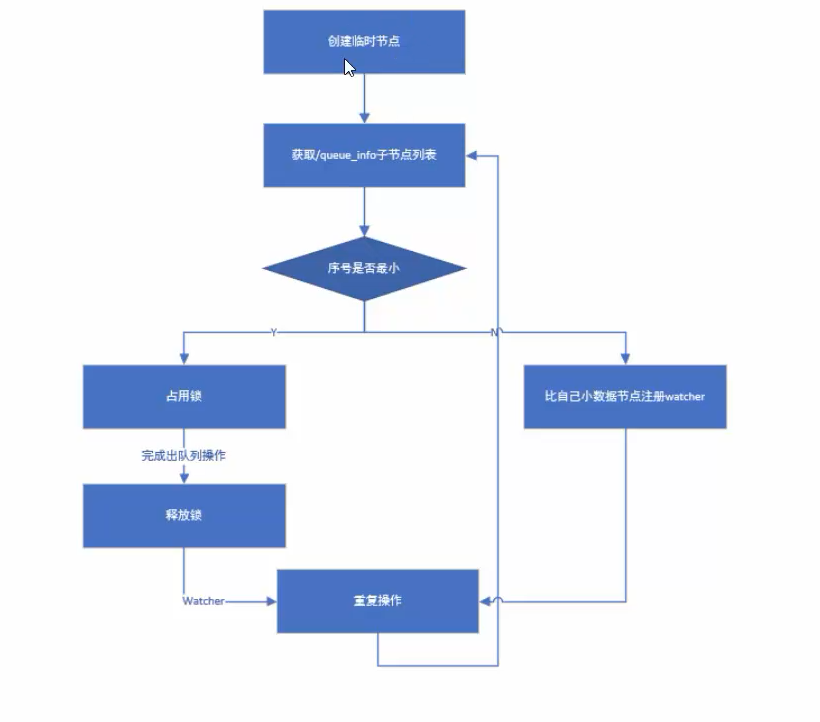
7.7、分布式队列
队列特性:FIFO(先进先出),zookeeper实现分布式队列步骤:
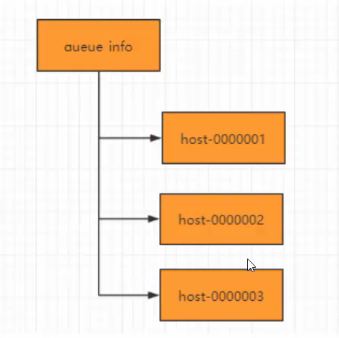
-
在队列节点下创建临时顺序节点,例如/queue_info/192.168.0.1-0000001
-
调用getChildren()接口获取/queue_info节点下所有子节点,获取队列中所有元素。
-
比较自己节点是否是序号最小的节点,如果不是,则等待其他节点出队列,在序号最小的节点注册watcher
-
获取watcher通知后,重复步骤。