在2.6.24内核中链路层接收网络数据包出现了两种方法,第一种是传统方法,利用中断来接收网络数据包,适用于低速设备;第二种是New Api(简称NAPI)方法,利用了中断+轮询的方法来接收网络数据包,是linux为了接收高速的网络数据包而加入的,适用于告诉设备,现在大多数NIC都兼容了这个方法。
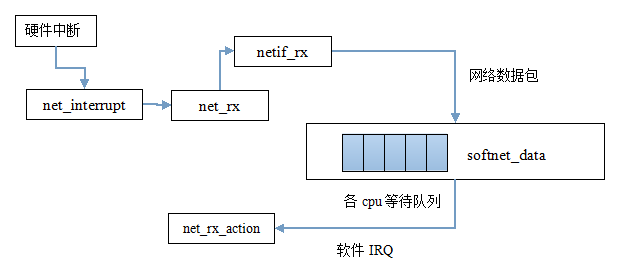
今天我的任务是扒一扒网络数据包在传统方法也就是低速路径中如何传入链路层以及如何将其发送给上层网络层的。下面先来看看这条低速路径的简略示意图:
1 //当产生硬件中断时,此中断处理例程被调用.例程确定该中断是否是由接收到的分组引发的,如果是则调用net_rx 2 static irqreturn_t net_interrupt(int irq, void *dev_id) 3 { 4 struct net_device *dev = dev_id; 5 struct net_local *np; 6 int ioaddr, status; 7 int handled = 0; 8 9 ioaddr = dev->base_addr; 10 11 np = netdev_priv(dev); 12 status = inw(ioaddr + 0); 13 14 if (status == 0) 15 goto out; 16 handled = 1; 17 18 if (status & RX_INTR) { 19 /* 调用此函数来获取数据包!!!!!! */ 20 net_rx(dev); 21 } 22 #if TX_RING 23 if (status & TX_INTR) { 24 /* 此出代码为发送数据包的过程,我以后会扒它 */ 25 net_tx(dev); 26 np->stats.tx_packets++; 27 netif_wake_queue(dev); 28 } 29 #endif 30 if (status & COUNTERS_INTR) { 31 32 np->stats.tx_window_errors++; 33 } 34 out: 35 return IRQ_RETVAL(handled); 36 }
1 static void 2 net_rx(struct net_device *dev) 3 { 4 struct net_local *lp = netdev_priv(dev); 5 int ioaddr = dev->base_addr; 6 int boguscount = 10; 7 8 do { 9 int status = inw(ioaddr); 10 int pkt_len = inw(ioaddr); 11 12 if (pkt_len == 0) 13 break; 14 15 if (status & 0x40) { 16 lp->stats.rx_errors++; 17 if (status & 0x20) lp->stats.rx_frame_errors++; 18 if (status & 0x10) lp->stats.rx_over_errors++; 19 if (status & 0x08) lp->stats.rx_crc_errors++; 20 if (status & 0x04) lp->stats.rx_fifo_errors++; 21 } else { 22 23 struct sk_buff *skb; 24 25 lp->stats.rx_bytes+=pkt_len; 26 //调用dev_alloc_skb来分配一个sk_buff实例 27 //还记得我上一篇文章扒的这个结构体吗? 28 skb = dev_alloc_skb(pkt_len); 29 if (skb == NULL) { 30 printk(KERN_NOTICE "%s: Memory squeeze, dropping packet. ", 31 dev->name); 32 lp->stats.rx_dropped++; 33 break; 34 } 35 //设置skb关联的网络设备 36 skb->dev = dev; 37 38 /*将得到的数据拷贝到sk_buff的data处 */ 39 memcpy(skb_put(skb,pkt_len), (void*)dev->rmem_start, 40 pkt_len); 41 42 insw(ioaddr, skb->data, (pkt_len + 1) >> 1); 43 //接着调用netif_rx!!!!! 44 netif_rx(skb); 45 dev->last_rx = jiffies; 46 lp->stats.rx_packets++; 47 lp->stats.rx_bytes += pkt_len; 48 } 49 } while (--boguscount); 50 51 return; 52 }
1 int netif_rx(struct sk_buff *skb) 2 { 3 struct softnet_data *queue; 4 unsigned long flags; 5 6 7 if (netpoll_rx(skb)) 8 return NET_RX_DROP; 9 10 if (!skb->tstamp.tv64) 11 net_timestamp(skb);//设置分组到达时间 12 13 /* 14 * The code is rearranged so that the path is the most 15 * short when CPU is congested, but is still operating. 16 */ 17 local_irq_save(flags); 18 //得到cpu的等待队列!!!! 19 queue = &__get_cpu_var(softnet_data); 20 21 __get_cpu_var(netdev_rx_stat).total++; 22 if (queue->input_pkt_queue.qlen <= netdev_max_backlog) { 23 if (queue->input_pkt_queue.qlen) { 24 enqueue: 25 dev_hold(skb->dev); 26 //将skb加到等待队列的输入队列队尾!!!!! 27 __skb_queue_tail(&queue->input_pkt_queue, skb); 28 local_irq_restore(flags); 29 return NET_RX_SUCCESS; 30 } 31 //NAPI调度函数,我以后将扒! 32 napi_schedule(&queue->backlog); 33 goto enqueue; 34 } 35 36 __get_cpu_var(netdev_rx_stat).dropped++; 37 local_irq_restore(flags); 38 39 kfree_skb(skb); 40 return NET_RX_DROP; 41 }
接下来就到了net_rx_action了

1 static void net_rx_action(struct softirq_action *h) 2 { 3 struct list_head *list = &__get_cpu_var(softnet_data).poll_list; 4 unsigned long start_time = jiffies; 5 int budget = netdev_budget; 6 void *have; 7 8 local_irq_disable(); 9 10 while (!list_empty(list)) { 11 struct napi_struct *n; 12 int work, weight; 13 14 if (unlikely(budget <= 0 || jiffies != start_time)) 15 goto softnet_break; 16 17 local_irq_enable(); 18 19 n = list_entry(list->next, struct napi_struct, poll_list); 20 21 have = netpoll_poll_lock(n); 22 23 weight = n->weight; 24 25 work = 0; 26 if (test_bit(NAPI_STATE_SCHED, &n->state)) 27 //此时poll函数指针指向默认的process_backlog!!!!重要!!!!!!!!!!!!!!!
28 work = n->poll(n, weight); 29 30 WARN_ON_ONCE(work > weight); 31 32 budget -= work; 33 34 local_irq_disable(); 35 36 if (unlikely(work == weight)) { 37 if (unlikely(napi_disable_pending(n))) 38 __napi_complete(n); 39 else 40 list_move_tail(&n->poll_list, list); 41 } 42 43 netpoll_poll_unlock(have); 44 } 45 out: 46 local_irq_enable(); 47 48 #ifdef CONFIG_NET_DMA 49 /* 50 * There may not be any more sk_buffs coming right now, so push 51 * any pending DMA copies to hardware 52 */ 53 if (!cpus_empty(net_dma.channel_mask)) { 54 int chan_idx; 55 for_each_cpu_mask(chan_idx, net_dma.channel_mask) { 56 struct dma_chan *chan = net_dma.channels[chan_idx]; 57 if (chan) 58 dma_async_memcpy_issue_pending(chan); 59 } 60 } 61 #endif 62 63 return; 64 65 softnet_break: 66 __get_cpu_var(netdev_rx_stat).time_squeeze++; 67 __raise_softirq_irqoff(NET_RX_SOFTIRQ); 68 goto out; 69 }
如果大家不明白上面的n->poll为什么指向了process_backlog,那我们来看一下n的定义:struct napi_struct *n。关键是搞懂napi_struct结构体

结构体中的poll函数指针指向轮询函数,在传统方法(就是我今天介绍的方法)下内核将poll填写为默认的process_backlog函数而在NAPI方法下内核则会填写相应的轮询函数
1 static int process_backlog(struct napi_struct *napi, int quota) 2 { 3 int work = 0; 4 //得到cpu的等待队列 5 struct softnet_data *queue = &__get_cpu_var(softnet_data); 6 unsigned long start_time = jiffies; 7 8 napi->weight = weight_p; 9 do { 10 struct sk_buff *skb; 11 struct net_device *dev; 12 13 local_irq_disable(); 14 //在等待队列的输入队列中移除一个sk_buff!!!!! 15 skb = __skb_dequeue(&queue->input_pkt_queue); 16 if (!skb) { 17 __napi_complete(napi); 18 local_irq_enable(); 19 break; 20 } 21 22 local_irq_enable(); 23 24 dev = skb->dev; 25 //调用此函数处理分组!!!! 26 netif_receive_skb(skb); 27 28 dev_put(dev); 29 } while (++work < quota && jiffies == start_time); 30 31 return work; 32 }
1 int netif_receive_skb(struct sk_buff *skb) 2 { 3 struct packet_type *ptype, *pt_prev; 4 struct net_device *orig_dev; 5 int ret = NET_RX_DROP; 6 __be16 type; 7 8 …… 9 …… 10 11 type = skb->protocol; 12 list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type)&15], list) { 13 if (ptype->type == type && 14 (!ptype->dev || ptype->dev == skb->dev)) { 15 if (pt_prev) 16 ret = deliver_skb(skb, pt_prev, orig_dev); 17 pt_prev = ptype; 18 } 19 } 20 21 if (pt_prev) { 22 /*调用函数指针func将skb传送至网络层!!!
*pt_prev为packet_type指针,
*在分组传递过程中内核会根据protocol填写func,
*func被填写为向网络层传递skb的函数
*/
23 ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev); 24 } else { 25 kfree_skb(skb); 26 /* Jamal, now you will not able to escape explaining 27 * me how you were going to use this. :-) 28 */ 29 ret = NET_RX_DROP; 30 } 31 32 out: 33 rcu_read_unlock(); 34 return ret; 35 }