一 增量式爬虫
什么时候使用增量式爬虫:
增量式爬虫:需求 当我们浏览一些网站会发现,某些网站定时的会在原有的基础上更新一些新的数据。如一些电影网站会实时更新最近热门的电影。那么,当我们在爬虫的过程中遇到这些情况时,我们是不是应该定期的更新程序以爬取到更新的新数据?那么,增量式爬虫就可以帮助我们来实现
二 增量式爬虫
概念
通过爬虫程序检测某网站数据更新的情况,这样就能爬取到该网站更新出来的数据
如何进行增量式爬取工作:
- 在发送请求之前判断这个URL之前是不是爬取过
- 在解析内容之后判断该内容之前是否爬取过
- 在写入存储介质时判断内容是不是在该介质中
增量式的核心是 去重
去重的方法
- 将爬取过程中产生的URL进行存储,存入到redis中的set中,当下次再爬取的时候,对在存储的URL中的set中进行判断,如果URL存在则不发起请求,否则 就发起请求
- 对爬取到的网站内容进行唯一的标识,然后将该唯一标识存储到redis的set中,当下次再爬取数据的时候,在进行持久化存储之前,要判断该数据的唯一标识在不在redis中的set中,如果在,则不在进行存储,否则就存储该内容
进行增量爬虫,需要使用scrapy-redis模块,一些基本的安装可以搜索一下,我们说一下部署和运行时遇到的问题(仅作为个人记录查看使用)
1、在setting中设置redis
#去重组件,在redis数据库里做去重操作 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # # #使用scrapy_redis的调度器,在redis里分配请求 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # # # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空 SCHEDULER_FLUSH_ON_START = True # # # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。 SCHEDULER_IDLE_BEFORE_CLOSE = 10 # # # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空 SCHEDULER_PERSIST = True # # #服务器地址 REDIS_HOST = '127.0.0.1' # # #端口 REDIS_PORT = 6379
此段代码可复用,每句也都标有注释
2、对自己编写的爬虫进行更改
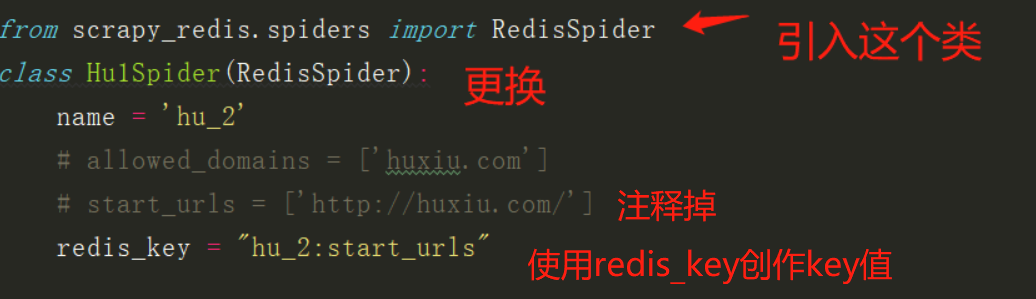
下图是判断是否有新数据

3、pipeline 正常设置存入MySQL、mongodb
import pymysql
class HuVPipeline(object):
def process_item(self, item, spider):
print('mysql--')
#连接数据库,
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='mysql')
#获取游标
cusor = conn.cursor()
#获取数据
title=item['title']
username=item['username']
yijuhua=item['yijuhua']
otherStyleTime=item['otherStyleTime']
#sql语句
sql = """INSERT INTO hux VALUES (%s, %s, %s, %s)"""
#这里是元组数据,(str,str,str,str)
cusor.execute(sql, (title, username, yijuhua, otherStyleTime))
cusor.close()
conn.commit()
# 关闭数据库连接
conn.close()
return item
连接redis数据库:
cmd打开命令窗口-进入redis目录-输入redis-server.exe开启服务端

不关闭刚才打开的命令窗口,再打开一个命令窗口,进入redis目录,输入redis-cli.exe -h 127.0.0.1 -p 6379 主机ip和端口号-然后输入lpush key value

mac 链接redis
打开终端,启动redis
cd /usr/local/bin ./redis-servers
使用lpush
cd /usr/local/bin ./redis-cli -h 127.0.0.1 -p 6379 #lpush key value lpush hu_v2:start_urls http://www.***.com
最后scrapy crawl (name)运行程序