2017-2018-1 20155202 《信息安全系统设计基础》第11周学习总结
课上习题:
习题图片:

在
char ( *(*x())[])()中x和char (*(*x[3])())[5]中x分别代表什么?
char ( (x())[])():
- 首先x紧挨着括号,在结合性上括号优先级大于星号,所以首先判定x为一个函数;
- 那么一个函数有些什么要素呢?
-
- 返回值;
-
- 参数列表.
- 由于紧挨着x的括号的是空的,所以很明显,函数的参数列表为空;
- 那么接下来就要分析函数的返回值类型.由于表达式比较复杂,我采用了我自称为"替代法"(可能贻笑大方,
- 可确实是我分析这类问题的方法)的方法:
- 首先将x()替换为FUNC,得:
- char ( (FUNC)[])()
- 又由于(FUNC),所以判定函数的返回值函数指针(或函数指针数组).将(FUNC)替换为FUNC_P,得:
- char ( *FUNC_P[])()
- 在上面的表达式中,在FUNC_P左边是*,右边是[],由于结合性优先级上[] > *,所以得知FUNC_P是一个数
- 组,将FUNC_P[]替换为FUNC_P_ARR,得:
- char ( *FUNC_P_ARR)()
- 到此知FUNC_P_ARR是指针数组,那么数组元素的指针类型有是什么呢?从上面表达式已经很明显的知道其类
- 型为:
- 指针数组FUNC_P_ARR元素的类型为:返回值为char,参数列表为空的函数指针.
- 总结起来就是:
- x是一个函数,其参数列表为空,返回值为一指针,该指针指向一个函数指针数组,且该指针数组的指针类型为:
- 返回值为char,参数列表为空的函数指针.
char ((x[3])())[5]:
- 这类复杂的声明,解读要根据运算符的优先级及其结合方向。
- [],()的运算符都高于*
- ,结合方向都是自左到右的。
- 所以对于char
- ((x[3])())[5],分析步骤如下:
- step1:
- (*x[3]) x是一个大小为3的数组,数组元素是指针
- step2:
- (*x[3])() x是一个大小为3的数组,数组元素是指针,指针指向一个函数
- step3:((x[3])())
- x是一个大小为3的数组,数组元素是指针,指针指向一个函数,该函数返回一个指针
- step4:char((x[3])())[5]
- x是一个大小为3的数组,数组元素是指针,指针指向一个函数,
- 该函数返回一个指针,这个指针指向一个大小为5的char数组
习题图片:

数组指针(也称行指针)
-
定义 int (*p)[n];
-
()优先级高,首先说明p是一个指针,指向一个整型的一维数组,这个一维数组的长度是n,也可以说是p的步长。也就是说执行p+1时,p要跨过n个整型数据的长度。
-
如要将二维数组赋给一指针,应这样赋值:
int a[3][4];
int (*p)[4]; //该语句是定义一个数组指针,指向含4个元素的一维数组。
p=a; //将该二维数组的首地址赋给p,也就是a[0]或&a[0][0]
p++; //该语句执行过后,也就是p=p+1;p跨过行a[0][]指向了行a[1][]
- 所以数组指针也称指向一维数组的指针,亦称行指针。
指针数组
- 定义 int *p[n];
- []优先级高,先与p结合成为一个数组,再由int*说明这是一个整型指针数组,它有n个指针类型的数组元素。这里执行p+1是错误的,这样赋值也是错误的:p=a;因为p是个不可知的表示,只存在p[0]、p[1]、p[2]...p[n-1],而且它们分别是指针变量可以用来存放变量地址。但可以这样 p=a; 这里p表示指针数组第一个元素的值,a的首地址的值。 如要将二维数组赋给一指针数组:
int *p[3];
int a[3][4];
for(i=0;i<3;i++)
p[i]=a[i];
- 这里int *p[3] 表示一个一维数组内存放着三个指针变量,分别是p[0]、p[1]、p[2]
所以要分别赋值。 - 这样两者的区别就豁然开朗了,数组指针只是一个指针变量,似乎是C语言里专门用来指向二维数组的,它占有内存中一个指针的存储空间。指针数组是多个指针变量,以数组形式存在内存当中,占有多个指针的存储空间。
- 还需要说明的一点就是,同时用来指向二维数组时,其引用和用数组名引用都是一样的。
- 比如要表示数组中i行j列一个元素:
- (p[i]+j)、((p+i)+j)、((p+i))[j]、p[i][j]
- 优先级:()>[]>*
指针函数:顾名思义就是带有指针的函数,即其本质是一个函数,只不过这种函数返回的是一个对应类型的地址。
- type *func (type , type)
- 如:int *max(int x, int y)
函数指针:指向函数的指针变量,本质上是一个指针变量
- type (*func)(type , type )
- 如:int (*max)(int a, int b);
教材学习内容总结
虚拟存储器的三个重要能力:
- 它将主存看成是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据,通过这种方式,高效的使用了主存。
- 它为每个进程提供了一致的地址空间,从而简化了存储器管理。
- 它保护了每个进程的地址空间不被其他进程破坏。
程序员需要理解虚拟存储器的三个原因:
- 虚拟存储器是中心的:它是硬件异常、硬件地址翻译、主存、磁盘文件和内核软件的交互中心;
- 虚拟存储器是强大的:它可以创建和销毁存储器片、可以映射存储器片映射到磁盘某个部分等等;
- 虚拟存储器若操作不当则十分危险。
地址空间
地址空间是一个非负整数地址的有序集合:{0,1,2,……}
-
线性地址空间:地址空间中的整数是连续的。
-
虚拟地址空间:CPU从一个有 N=2^n 个地址的地址空间中生成虚拟地址,这个地址空间成为称为虚拟地址空间。
-
地址空间的大小:由表示最大地址所需要的位数来描述。
-
物理地址空间:与系统中的物理存储器的M个字节相对应。
-
虚拟存储器的基本思想:主存中的每个字节都有一个选自虚拟地址空间的虚拟地址和一个选自物理地址空间的物理地址。
虚拟存储器作为缓存的工具 -
虚拟存储器——虚拟页(VP),每个虚拟页大小为P=2^p字节。
-
物理存储器——物理页(PP),也叫页帧,大小也为P字节。
- 任意时刻,虚拟页面的集合都被分为三个不相交的子集:
- 未分配的:VM系统还没分配(创建)的页,不占用任何磁盘空间。
- 缓存的:当前缓存在物理存储器中的已分配页。
- 未缓存的:没有缓存在物理存储器中的已分配页。
DRAM缓存的组织结构
- 不命中处罚很大
- 是全相联的——任何虚拟页都可以放在任何的物理页中
- 替换算法精密
- 总是使用写回而不是直写
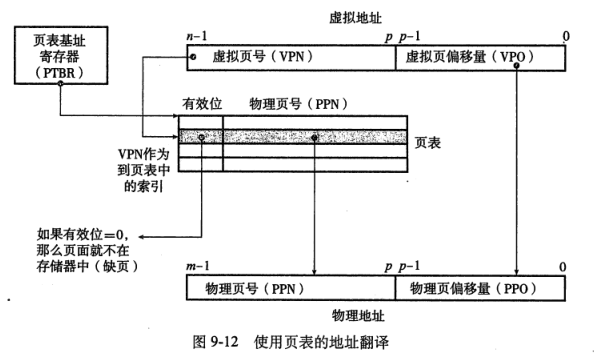
页表
- 页表:是一个数据结构,存放在物理存储器中,将虚拟页映射到物理页,就是一个页表条目的数组。
- 页表就是一个页表条目PTE的数组。
- PTE:由一个有效位和一个n位地址字段组成的,表明了该虚拟页是否被缓存在DRAM中。
- 页表的组成:有效位+n位地址字段
- 如果设置了有效位:地址字段表示DRAM中相应的物理页的起始位置,这个物理页中缓存了该虚拟页。
- 如果没有设置有效位:
- 空地址:表示该虚拟页未被分配
- 不是空地址:这个地址指向该虚拟页在磁盘上的起始位置。
地址翻译
-
(1)地址翻译
-
地址翻译就是一个N元素的虚拟地址空间VAS中的元素和一个M元素的物理地址空间PAS中元素之间的映射。
-
MAP: VAS → PAS ∪ ∅
-
这里
-
MAP = A' ,如果虚拟地址A处的数据在PAS的物理地址A'处
-
MAP = ∅ ,如果虚拟地址A处的数据不在物理存储器中
-
如何用页表实现这种映射
-
当页面命中时,CPU硬件执行步骤
-
处理器生成虚拟地址,传给MMU
-
MMU生成PTE地址,并从高速缓存/主存请求得到他
-
高速缓存/主存向MMU返回PTE
-
MMU构造物理地址,并把它传给高速缓存/主存
-
高速缓存/主存返回所请求的数据给处理器。
-
处理缺页时,CPU硬件执行步骤
-
处理器生成虚拟地址,传给MMU
-
MMU生成PTE地址,并从高速缓存/主存请求得到他
-
高速缓存/主存向MMU返回PTE
-
PTE中有效位为0,触发缺页异常
-
确定牺牲页
-
调入新页面,更新PTE
-
返回原来的进程,再次执行导致缺页的指令
(2)结合高速缓存和虚拟存储器
- 在既使用SRAM高速缓存又使用虚拟存储器的系统中,大多数系统选择物理寻址。
- 两者结合的主要思路是地址翻译发生在高速缓存之前。
- 页表目录可以缓存,就像其他的数据字一样。
(3)利用TLB加速地址翻译
- TLB:翻译后备缓冲器,是一个小的、虚拟存储的缓存,其中每一行都保存着一个由单个PTE组成的块
步骤
-
CPU产生一个虚拟地址
-
MMU从TLB中取出相应的PTE
-
MMU将这个虚拟地址翻译成一个物理地址,并且将它发送到高速缓存/主存
-
高速缓存/主存将所请求的数据字返回给CPU
多级页表
- 多级页表——采用层次结构,用来压缩页表。
- 以两层页表层次结构为例,好处是:
- 如果一级页表中的一个PTE是空的,那么相应的二级页表就根本不会存在
- 只有一级页表才需要总是在主存中,虚拟存储器系统可以在需要时创建、页面调入或调出二级页表,只有最经常使用的二级页表才缓存在主存中。
- 多级页表的地址翻译:
四、存储器
- 1.存储器映射
- 指Linux通过将一个虚拟存储器区域与一个磁盘上的对象关联起来,以初始化这个虚拟存储器区域的内容的过程。
- 映射对象:
- Unix文件系统中的普通文件
- 匿名文件(全都是二进制0)
(1)共享对象和私有对象
共享对象
- 共享对象对于所有把它映射到自己的虚拟存储器进程来说都是可见的。
- 即使映射到多个共享区域,物理存储器中也只需要存放共享对象的一个拷贝。
- 私有对象
- 私有对象运用的技术:写时拷贝
- 在物理存储器中只保存有私有对象的一份拷贝
- (2)fork函数就是应用了写时拷贝技术,execve函数:
- 创建新的虚拟存储器区域
教材学习中的问题和解决过程
(一个模板:我看了这一段文字 (引用文字),有这个问题 (提出问题)。 我查了资料,有这些说法(引用说法),根据我的实践,我得到这些经验(描述自己的经验)。 但是我还是不太懂,我的困惑是(说明困惑)。【或者】我反对作者的观点(提出作者的观点,自己的观点,以及理由)。 )
物理和虚拟寻址
- 计算机系统的主存被组织成一个由M个连续的字节大小的单元组成的数组,每字节都有一个唯一的物理地址(PA)。CPU根据物理地址访问存储器的方式是物理寻址。
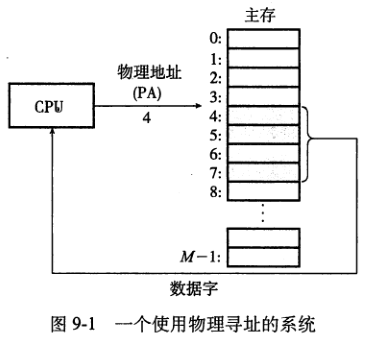
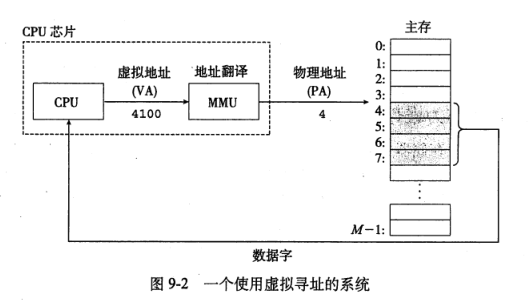
- 使用虚拟寻址时,CPU通过生成一个虚拟地址VA来访问主存,这个虚拟地址在被送到存储器之前先转换成适当的物理地址,地址翻译通过CPU芯片上的存储器管理单元完成。
地址翻译
-
-
地址翻译:一个N元素的虚拟地址空间(VAS)中的元素和一个M元素的物理地址空间(PAS)之间的映射。
-
MAP: VAS → PAS ∪ ∅
-
MAP = A' ,如果虚拟地址A处的数据在PAS的物理地址A'处
-
MAP = ∅ ,如果虚拟地址A处的数据不在物理存储器中
-
CPU中的一个控制寄存器页表基址寄存器指向当前页表,n位的虚拟地址包含两个部分:一个p位的虚拟页面偏移(VPO) 和一个(n-p)位的虚拟页号,页表条目中的物理页页号和虚拟地址中的VPO串联起来,就得到了相应的物理地址。
-
案例研究:Intel Core i7/Linux存储器系统
core i7地址翻译
PTE的三个权限位:
- R/W位:确定内容是读写还是只读
- U/S位:确定是否能在用户模式访问该页
- XD位:禁止执行位,64位系统中引入,可以用来禁止从某些存储器页取指令
缺页处理程序涉及到的位:
-
A位:引用位,实现页替换算法
-
D位:脏位,告诉是否必须写回牺牲页
-
Linux虚拟存储器系统
-
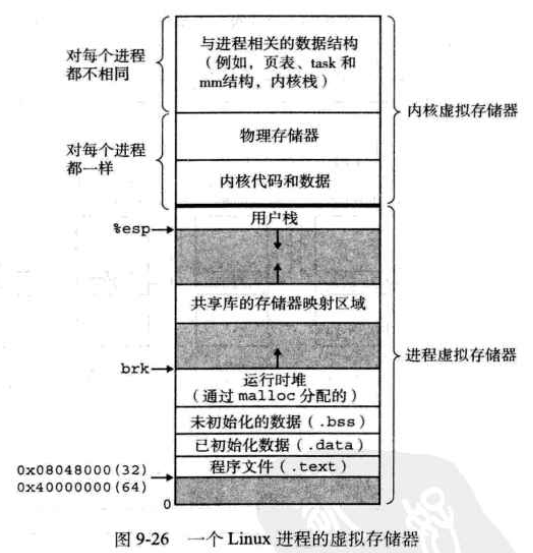
-
linux为每个进程维持了一个单独的虚拟地址空间,其中,内核虚拟存储器位于用户栈之上;
-
内核虚拟存储器包含内核中的代码和数据结构,还有一些被映射到一组连续的物理页面(主要是便捷地访问特定位置,比如执行I/O操作的时候需要的位置)
-
linux将虚拟存储器组织成一些区域(也叫做段)的集合。一个区域就是已经存在的(已分配的)虚拟存储器的连续片;
-
允许虚拟地址空间有间隙;内核不用记录那些不存在的页,这样的页也不用占用存储器;
-
一个具体区域的区域结构:
-
vm _start:指向这个区域的起始处;
-
vm _end:指向这个区域的结束处;
-
vm _prot:描述这个区域内所包含的所有页的读写许可权限;
-
vm _fags:描述这个区域内的页面是与其他进程共享的,还是这个进程私有的,等等;
-
vm _next:指向链表的下一个结构。
-
linux为每个进程维持了一个单独的虚拟地址空间,其中,内核虚拟存储器位于用户栈之上;
-
内核虚拟存储器包含内核中的代码和数据结构,还有一些被映射到一组连续的物理页面(主要是便捷地访问特定位置,比如执行I/O操作的时候需要的位置)
-
linux将虚拟存储器组织成一些区域(也叫做段)的集合。一个区域就是已经存在的(已分配的)虚拟存储器的连续片;
其他(感悟、思考等,可选)
- 本周的学习加深了我对虚拟存储器的理解,让我明白了其区域结构。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第11周 | 2500/2700 | 17/18 | 30/20 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:40小时
-
实际学习时间:40小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)