索引
索引的出现其实就是为了提高数据查询的效率,就像书的目录一样
InnoDB的索引模型
N叉树
以InnoDB的一个整数字段索引为例子,这个N差不多是1200。如果这棵树高4的化,就可以存储1200的3次方的值17亿了。考虑到根节点总是在内存中的,那么查一个数据最多只需要访问3次磁盘,而且其中第二层也很有可能在内存中,那么访问磁盘的平均次数就更少了。
B+树
每一个索引都有一颗B+树
假如有这么一张表,有一个id为主键和一个普通索引k的表
create table zx(
id int primary key,
k int not null,
name varchar(16),
index(k)
)engine=InnoDB;
如果有R1-R5(ID,k)值分别为(100,1)、(200,2)、(300,3)、(500,5)和(600,6),那么两颗树的样子就如下图
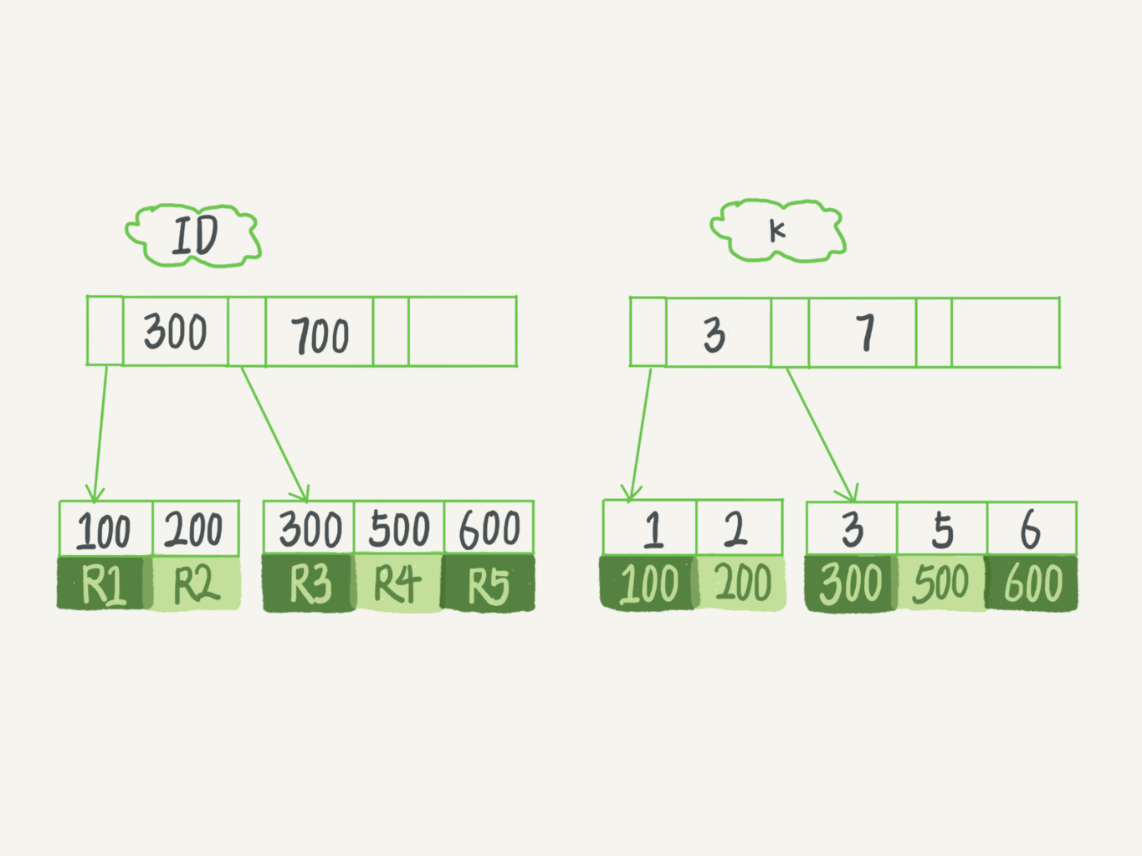
主键索引B+树结构
主键索引的叶子节点存的是表的数据。在InnoDB里,主键索引也叫聚簇索引(clustered index)
分主键索引B+树结构
非主键索引的叶子节点内容是主键的值。在InnoDB里,非主键索引也被称为二级索引(secondary index)
区别
根据上面的内容,我们知道了数据是放在主键的索引结构中的,那么我们查询数据肯定最后会查询主键的索引树才会有数据。
案例
select * from zx where id=500
主键查询,那么只要搜索主键的B+树
select * from zx where k =5
非主键查询,先搜索k的索引B+树,找到主键的值,在去查询,主键的B+树。这个过程被称为回表
结论:尽量使用主键查询,非主键查询会多查询一张表
索引的维护
B+树是有序的
插入数据-自增主键
如果我们要插入一个ID为700的数据,那么只需要在R5的记录后面插入一个新记录就好了。
但是要插入一个ID为400那么就麻烦了,需要拆分子节点,重新划分上层结点,这样的话就会很麻烦,耗时,消耗空间。同样删除操作也可能会触发这个情况。
这就是为什么推荐使用自增主键的原因了
主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间越小
B+树的优点
1.减少磁盘的IO操作
2.加快数据查询速度
常见索引优化
覆盖索引
引入
执行 select * from zx where k between 3 and 5会发生什么?
表结构
create table zx(
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT '',
index k(k)
)engine=InnoDB;
表数据
执行流程
1.首先在k索引树上找到k=3的记录,取出ID=300
2.再到ID索引树查到ID=300对应的R3
3.在k索引树上找到k=4的记录,取出ID=500
4.在回到ID索引树查到ID=500的R4
5.在k索引树查询下一个值为6,不满足条件退出,返回结果
回到主键索引树的搜索过程叫做回表,这个过程查询了K树的3条记录,回表了两次
解决
使用覆盖索引的方式:
select ID from zx where k between 3 and 5
这样查询的ID直接可以在k索引表查询出来,所以就可以减少回表的操作,提高了数据查询的效率
k索引表已经覆盖了我们的查询需求,所以叫覆盖索引
联合索引-索引结构
原理
联合索引(col1, col2,col3)也是一棵B+Tree,其非叶子节点存储的是第一个关键字的索引,而叶节点存储的则是三个关键字col1、col2、col3三个关键字的数据,且按照col1、col2、col3的顺序进行排序。

col1表示的是年龄,col2表示的是姓氏,col3表示的是名字

缺点
我们从图中可以看出,起作用的索引其实就是联合索引的第一个索引,如果我们要查询联合索引的第二个索引,第三个索引其实是没有效果的,相当于全表查询。查询第一个和第三个索引的话,只有第一个起效果,要继续进行回表操作。所以联合索引的第一个索引设置是非常重要的。
联合索引的覆盖索引优化
我们从联合索引的结构可以看出,索引树是以第一个索引构建的,但是在叶子节点存储这索引2和索引3的数据,我们可以使用这种方式进行覆盖索引的优化,减少回表操作。
案例
以上图为例有一个id主键,原来打算通过年龄范围去查询姓和名,那就要先通过年龄查出id,在通过id去查询姓和名
但是直接以年龄和姓和名,这样的话查询年龄就可以直接得到姓和名的数据,省去了回表的操作
最左前缀原则
问题
如果每一种查询都要设计一个索引,索引是不是太多了。单独为一个不频繁的请求创建一个索引也很浪费。
原则
1.这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
2.如果可以通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的。(比方说原来有(a,b)和b索引,我把顺序调整成(b,a)那么b索引就不需要了
有一个复合索引:INDEX(a, b, c)
使用方式 能否用上索引
select * from users where a = 1 and b = 2 能用上a、b
select * from users where b = 2 and a = 1 能用上a、b(有MySQL查询优化器)
select * from users where a = 2 and c = 1 能用上a
select * from users where b = 2 and c = 1 不能
说一下1和3的区别,1通过搜索a和b直接可以获得表的主键值,按照主键值查询的数据全都是需要的数据
3的话,根据a查询出来的主键值,并不是最终的结果,更具查询出来的表数据在根据c字段的要求筛选数据,效率会低一点
总结
在设计联合索引的时候,联合索引的个数和顺序都需要精心的设计过,不可以随便创建
索引下推
注意
索引下推是MySQL5.6推出来的
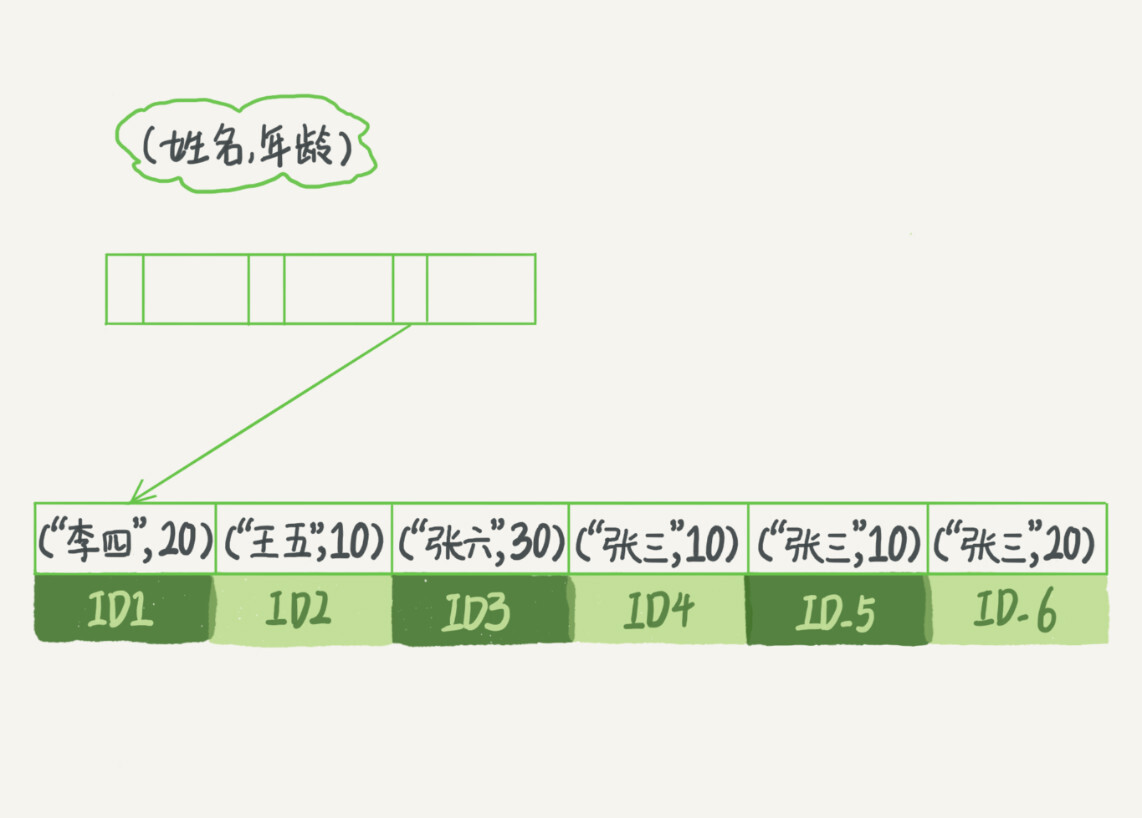
查询语句
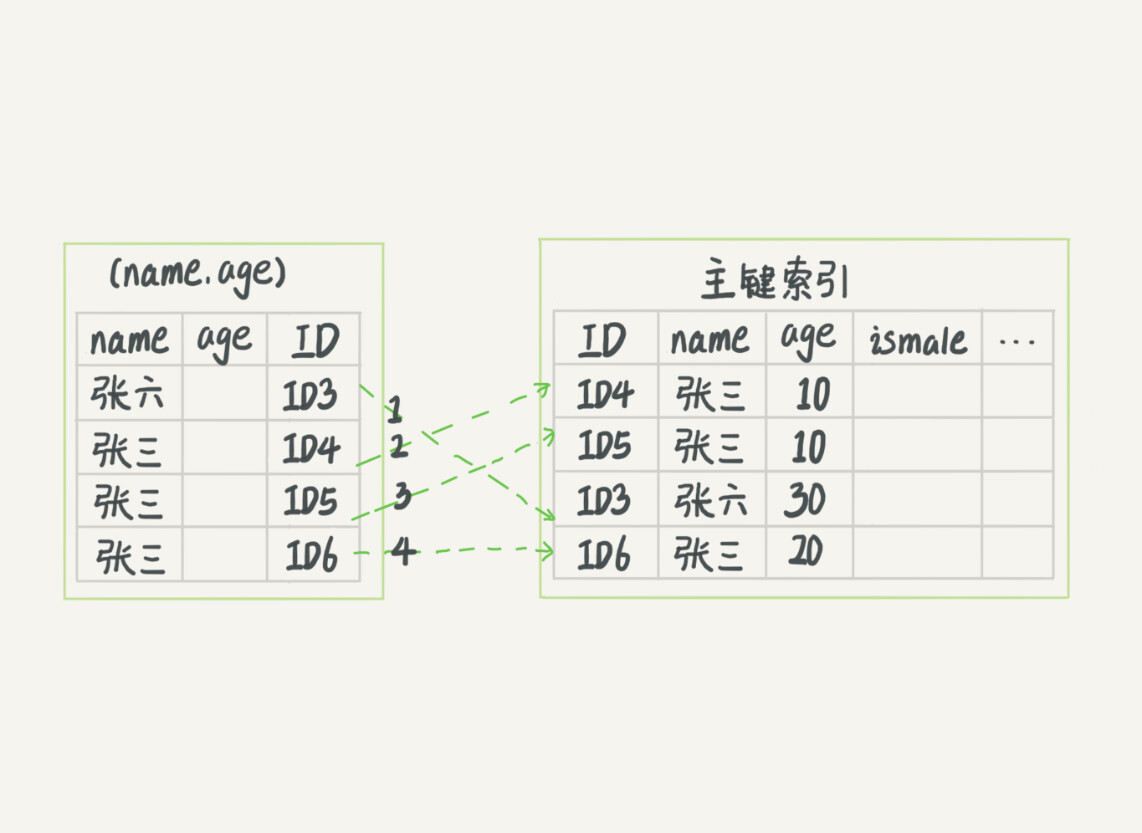
select * from user where name like '张%' and age=10
如果是这样查询的话是不满足最左前缀原则的条件的,所以查询效果如下
5.5MySQL
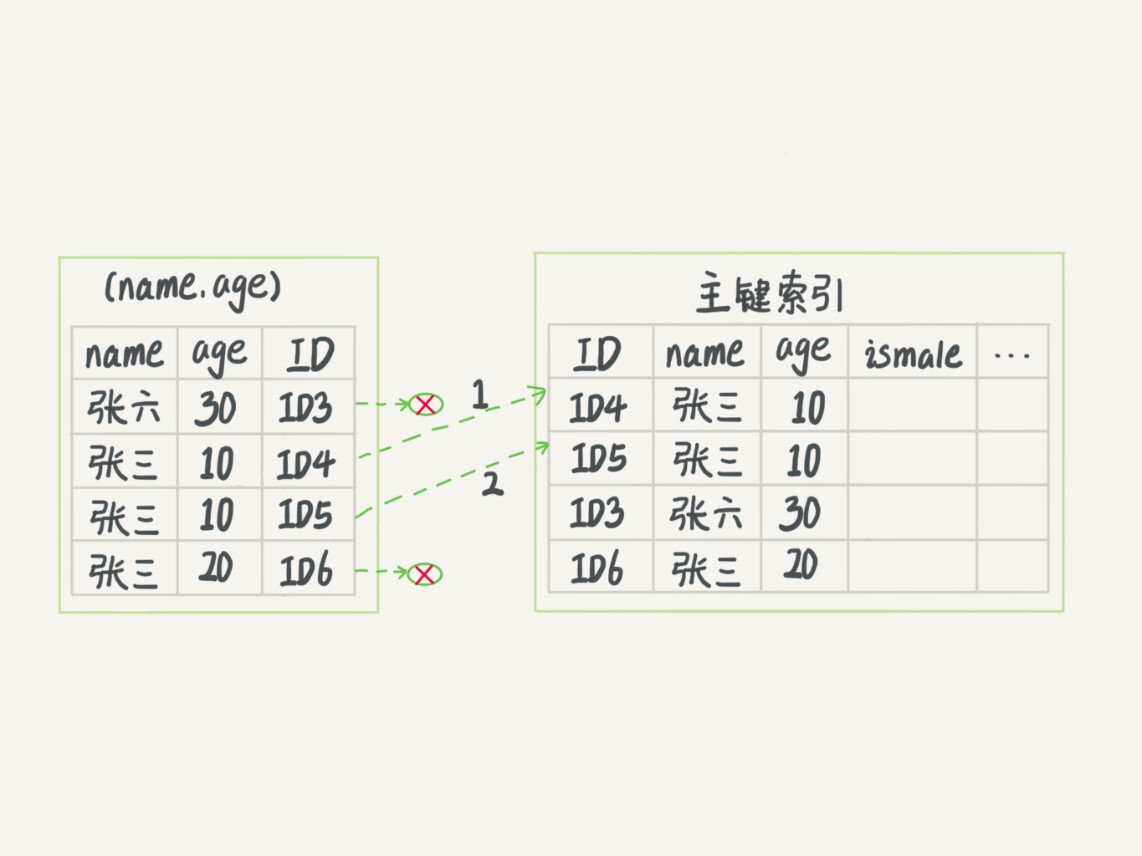
5.6MySQL做了优化,在索引内部就判断了age是否等于10,提高了性能
最左前缀原则http://www.meow7.cn/index.php/archives/23/
B+树https://www.cnblogs.com/wade-luffy/p/6292784.html
联合索引https://blog.csdn.net/zgjdzwhy/article/details/84062105