xpath
xpath两种使用方式
和bs类似,一种是调用本地资源,一种是网络资源
etree.parse(filePath)
etree.HTML('page_text')
xpath表达式
层级:/一个层级 //多个层级 (注意如果从html开始取,要在前面加一个/ 写成/html,局部./li)
属性定位:类似//div[@class='zx']
索引取值: 类似p[3](注意xpath中的索引,是从1开始的)
取文本:/text()直系 //text()取所有
取属性:类似/@src
xpath实战
功能:爬取安居客某区域所有的房价信息,最终以条形图的方式显示
import requests
from lxml import etree
import matplotlib.pyplot as plt
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
all_price=[]
def work(count):
page=1
while page<=count:
url=f"https://hangzhou.anjuke.com/sale/yuhang-q-hzpingyao/p{page}/#filtersort"
res=requests.get(url=url,headers=headers).text
tree=etree.HTML(res)
all_house=tree.xpath("//div[@class='sale-left']/ul/li")
for i in all_house:
#截取有效的价格
price=i.xpath("./div[@class='pro-price']/span[2]/text()")[0][:-4]
price=int(price)
#价格添加到list中
all_price.append(price)
print(price)
page+=1
print(all_price)
def show():
#画图
plt.hist(all_price, bins=50)
plt.show()
print(len(all_price))
if __name__ == '__main__':
#爬取25页
work(25)
show()
如图
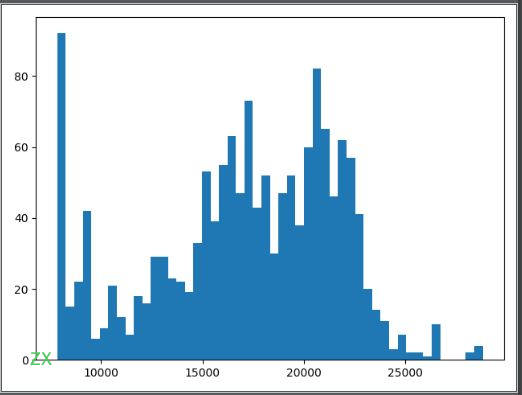
但是安居客有部分数据感觉并不可靠