前言
正文
自我介绍一下
答案
个人资料:一句话,占比5%左右
学习技能:半分钟~一分钟,占比20%左右
项目和经历:一分钟左右,占比45%左右
工作体会:半分钟,占比15%左右
一句话左右:职业规划,占比10%左右
一句话:兴趣占比,占比5%左右
我叫xxx ,目前就职于xxxxxxxx公司,岗位是嵌入式软件开发工程师(C++开发工程师)一职。我从事嵌入式行业已经有接近2年了,主要负责公司核心视觉软件与底层硬件,比如相机,IO,Sensor,核心板的交互。
一、专业技能
1. 请你介绍一下STL有哪些容器,并且他们的底层结构是怎么样的,有哪些应用场景?
答案
1. vector
底层结构:为数组,为线性连续空间。
应用场景:在一些有大量查询,更改操作,而增删操作较少的地方使用。
2. list
底层结构:为双向链表
应用场景:支持快速增删,最查询效率较低。
3. map
底层结构:红黑树
应用场景:其查找,删除,增加等一系列操作的时间复杂度都是稳定的。都为O(LOGN).
4. unordered_map
底层结构:哈希表
应用场景:查找,删除,添加的速度快,时间复杂度为O(c).
5. deque
底层结构:一个中央控制器和多个缓冲区。是一种双向开口的连续线性空间。
应用场景:可以高效的在头尾两端插入和删除元素。
2. OSI七层模型有哪些?简述一下
- 应用层
答案
1)应用层的协议:HTTP、FTP、SMTP、DNS.
2)在应用层交互的数据单元:称为报文。
3)应用层的作用: 应用层提供各种各样的协议,这些协议嵌入到我们使用的应用程序中,为用户与网络之间提供一个打交道的接口。
- 表示层
答案
1) 表示层提供的服务: 数据压缩,数据加密以及数据描述,使应用程序不必担心在各台计算机表示和存储的差异。
- 会话层
答案
1) 会话层的功能: 负责建立,管理和终止表示层实体之间的通信会话。该层提供了数据交换的定界和同步功能,包括了建立检查点和恢复方案的方法。
- 传输层
答案
1)传输层的协议:TCP、UDP
2)TCP的协议结构是怎么样的?
序列号,它是TCP报文段的一数字编号,为保证TCP可靠连接,每一个发送的数据段都要加上序列号。建立连接时,两端都会随机生成一个初始序列号。
而确认号是和序列号配合使用的,应答某次请求时,则返回一个确认号,它的值等于对方请求序列号加1.
6个标志位分别是,URG:这是条紧急信息,ACK:应答消息,PSH:缓冲区尚未填满,RST:重置连接,SYN:建立连接消息标志,FIN:连接关闭通知信息.
3) 传输层的功能: 为两台主机进程之间的通信提供服务,处理数据包错误,数据包次序以及其他一些关键传输问题。

- 网络层
答案
1)网络层的协议:IP
2)网络层的功能: 由于两台计算机之间传送数据时其通信链路往往不止一条,所传输的数据必须要经过很多子网。 所以网络层的主要任务就是选择合适的网间路由和交换节点,确保数据按时成功传送。
3)在发送数据时,网络层把传输层产生的报文或用户数据报封装成 分组 和 包, 向下传输。
- 数据链路层
答案
1) 数据链路层的功能: 在两个相邻节点之间传送数据时,数据链路层将网络层交下来的IP数据报组装成帧,在两个相邻节点间的链路上传送帧。
2) 帧的格式: 报头head 和数据data两部分。
head: 标明数据发送者,接收者,数据类型,如MAC地址
data: 存储了计算机之间交互的数据。
- 物理层
答案
1) 作用: 实现计算机节点之间比特流的透明传送。
3. UDP与TCP的区别是什么?
答案
1). 连接方面:TCP是基于连接的,UDP是无连接的,发送前不需要建立连接。
A. TCP的连接是如何实现的?
基于连接的三次握手和断开的四次挥手。
2). 消耗的资源:UDP消耗的资源比TCP消耗的资源少。
3). UDP是数据报,TCP是基于流传输的。
4). 安全方面: TCP是可靠传输,保证传送的数据无差错,不丢失,不重复,且按序到达。UDP是尽力交付,不保证可靠交付。
5) . 传输效率: TCP传输效率相对较低,UDP传输效率高。
6). 面向的服务对象: TCP是一对一的两点服务,即一条连接只有两个端点。
UDP则支持一对多,多对多的交互通信。
4. TCP如何实现其可靠性?
答案
1. 序列号和确认应答信号。
2. 重传机制
1) 超时重传
A. 重传的情况
数据包丢失
确认应答丢失
B. RTO(Retransmission timeout 超时重传时间) 应略大于 RTT(Round Time Trip)
C. 每当遇到一次超时重传的时候,都会将下一次超时时间间隔设为先前值的两倍。两次超时,就说明网络环境差,不宜频繁反复发送。
2) 快速重传
A. 快速重传的工作方式:
当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段.
3) SACK(Select Acknowledge 选择性确认)
A. 工作方式:
在TCP头部字段里加了一个SACK的东西,可以将缓存的地图发送给发送方,这样发送方就可以知道哪些数据收到了,哪些数据没有收到。这样就可以只重传丢失了的信息了。
4) D-ACK(Duplicate SACK)
A. 工作方式:
使用SACK来告诉发送方自己重复接收到了哪些数据。SACK选项的第一个块(这个块也叫做DSACK块)可以用来传递触发这个ACK确认包的系列号,这个就是DSACK(duplicate-SACK)功能。这样允许TCP发送端根据SACK选项来推测不必要的重传。
B.DACK的好处
a. 可以让发送方知道,是发出去的包丢了,还是接收方回应的ACK丢了。
b. 可以知道是不是发送方的数据包被 网络延迟了。
c. 可以知道是不是网络中是不是把发送包的数据复制了。
3. 流量控制
A. 原理
TCP使用窗口机制来实现流量控制的。原理是:在通信过程中,接收方根据自己接收缓存的大小,动态调整发送方的发送窗口大小,即TCP报文段首部中的“窗口”字段rwnd,来限制发送方向网络注入报文的速率。同时,发送方根据其对当前网络拥塞程序的估计确定一个拥塞窗口cwnd,最终A发送的窗口的实际大小是min(rwnd,cwnd)值。
4. 拥塞控制
1) 慢启动
2) 拥塞避免
3) 快重传
4)快恢复
5 滑动窗口管理(未收到确认信号,可持续发送的数据长度)
A. 引入滑动窗口的原因:
如果为每个数据包都进行确认应答的话,那么就会导致RTT越长,通信的效率就越低。
B. 滑动窗口的概念
窗口大小就是指无需等待确认应答,而可以继续发送数据的最大值。
C. 滑动窗口是如何通知发送方的?
TCP中有个字段叫Window,也就是窗口大小。这个字段是接收方告诉发送方自己还有多少缓冲区可以接收数据,于是发送端就可以根据这个接收端的处理能力来处理数据,而不会导致接收端接收不过来。
通常窗口的大小是由接收方决定的。


4.1 TCP解决粘包和拆包的方法有哪些?
答案
1) 在数据尾部增加特殊字符进行分割。
2) 将数据定位固定大小。
3) 将数据分为两部分,一部分是头部,一部分是内容体。
4.2 TCP三次握手的具体报文是怎么样的?
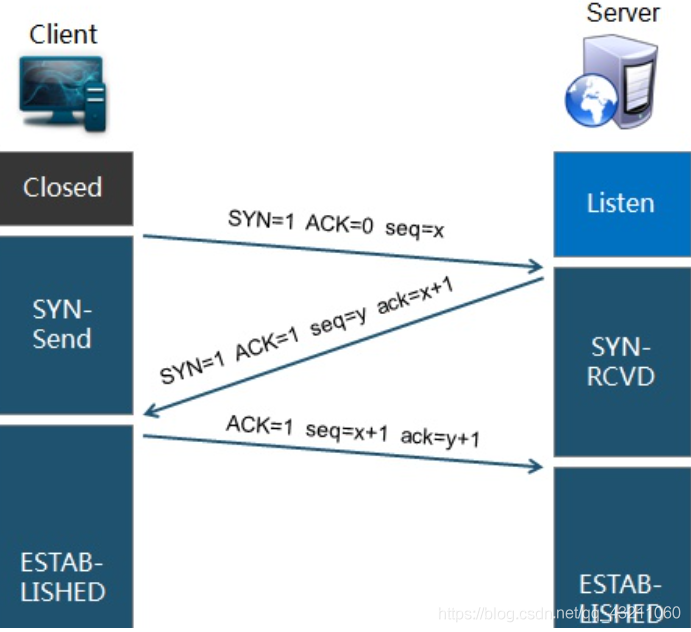
SYN:连接请求/接收 报文段
seq:发送的第一个字节的序号
ACK:确认报文段
ack:确认号。希望收到的下一个数据的第一个字节的序号
4.3 TCP四次挥手的具体过程是怎么样的?
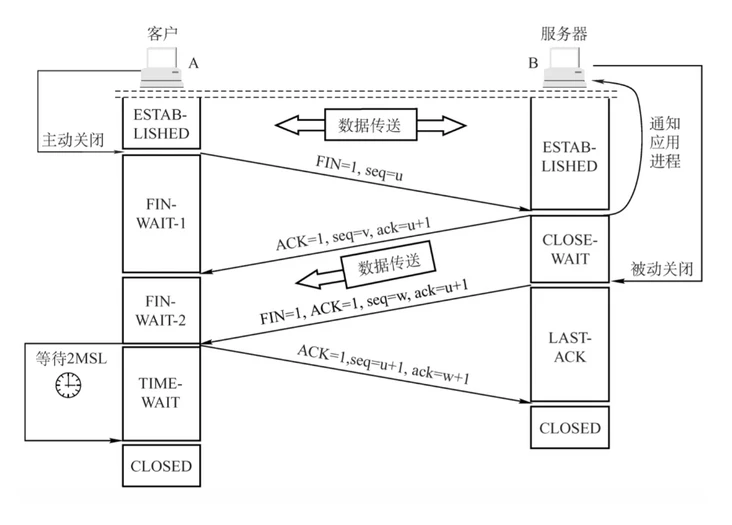
FIN :连接终止位
seq:发送的第一个字节的序号
ACK:确认报文段
ack:确认号。希望收到的下一个数据的第一个字节的序号
4.4 TCP和UDP的报文长什么样?稍微解释一下?
TCP:
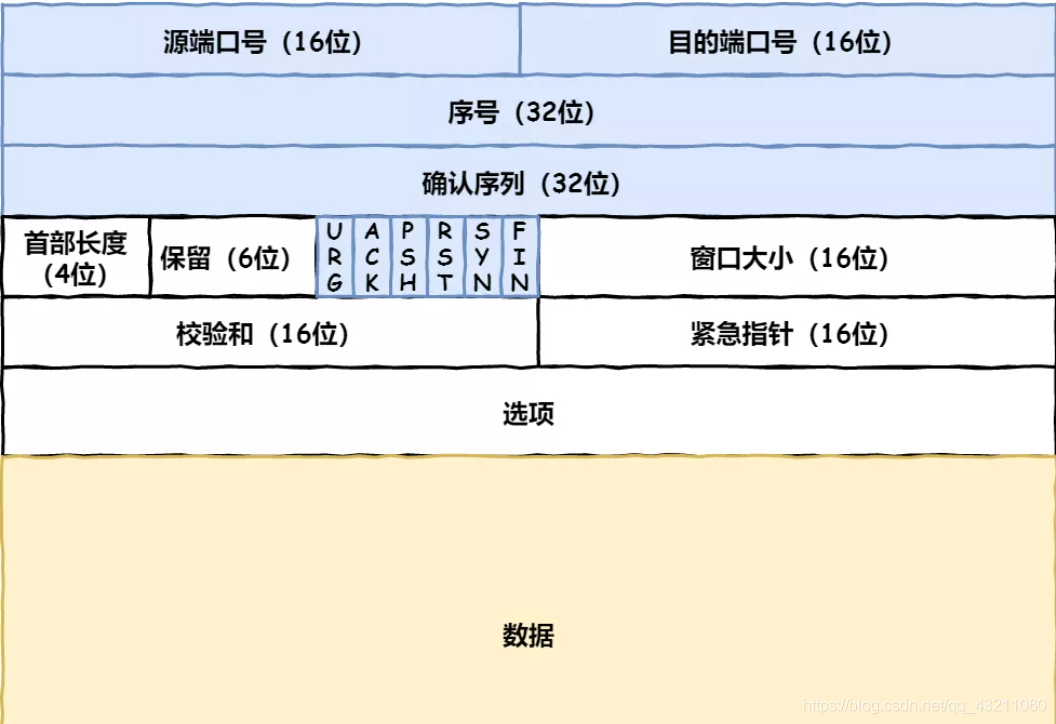
UDP:

位码即tcp标志位,有6种标示:SYN(synchronous建立联机) ACK(acknowledgement 确认) PSH(push传送) FIN(finish结束) RST(reset重置) URG(urgent紧急)Sequence number(顺序号码) Acknowledge number(确认号码)
4.5 TCP的四次挥手,最后一次能不能不要?
答案
不能不要。
最后一次握手是客户端发送ACK给服务端,确认客户端已接收到服务端请求断开连接的请求。若只有三次握手,那么 服务端,再发送完自己要断开连接的请求后,无法知道,是否客户端已接收到该信息,四次挥手的目的是在链接断开时保证传输数据的完整性。
关闭连接时,当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了
所以你可以未必会马上会关闭SOCKET,也即你可能还需要发送一些数据给对方之后,再发送FIN报文给对方来表示你同意现在可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的。
5. UDP如何也能做到可靠性?(RUDP:Reliable UDP)
- 首先,不同场景对可靠的需求是不一样的,有这么三个点:
答案
1) 尽力可靠:通信的接收方要求发送方的数据尽量完整到达,但业务本身的数据是可以允许缺失的。例如:音视频数据。
2) 无序可靠:通信的接收方要求发送方的数据必须完整到达,但可以不管到达的先后顺序.例如:文件传输、白板书写、图形实时绘制数据、日志型追加数据。
3) 有序可靠:通信接收方要求发送方的数据必须按顺序完整到达。
- 为什么要用UDP做可靠保证?
答案
在保证通信的时延和质量的条件下尽量降低成本。
- RUDP主要解决的问题?
答案
1) 端到端连通性问题:一般终端直接和终端通信都会涉及到 NAT 穿越,TCP 在 NAT 穿越实现非常困难,相对来说 UDP 穿越 NAT 却简单很多.
2) 弱网环境传输问题。
3) 带宽竞争问题:客户端数据上传需要突破本身 TCP 公平性的限制来达到高速低延时和稳定,也就是说要用特殊的流控算法来压榨客户端上传带宽。
4) 传输路径优化问题: 在一些对延时要求很高的场景下,会用应用层 relay 的方式来做传输路由优化,也就是动态智能选路,这时双方采用 RUDP 方式来传输,中间的延迟进行 relay 选路优化延时。
5) 资源优化问题:某些场景为了避免 TCP 的三次握手和四次挥手的过程,会采用 RUDP 来优化资源的占用率和响应时间,提高系统的并发能力,例如 QU
- RUDP如何保证可靠性?
答案
1) 重传模式:RUDP 的重传是发送端通过接收端 ACK 的丢包信息反馈来进行数据重传,发送端会根据场景来设计自己的重传方式,重传方式分为三类:定时重传、请求重传和 FEC 选择重传。
A. 定时重传:发送端如果在发出数据包(T1)时刻,在一个RTO(Retransmission TimeOut即重传超时时间)之后,还未收到这个数据包的ACK消息,那么发送端就重传这个数据包。
B. 请求重传: 接收端在发送ACK的时候携带自己丢失报文的信息反馈,发送端在接收到ACK信息时根据丢包反馈进行报文重传。
C. FEC 选择重传:FEC(Forward Error Correction)是一种前向纠错技术,一般通过 XOR 类似的算法来实现,也有多层的 EC 算法和 raptor 涌泉码技术,其实是一个解方程的过程。
在发送方发送报文的时候,会根据 FEC 方式把几个报文进行 FEC 分组,通过 XOR 的方式得到若干个冗余包,然后一起发往接收端,如果接收端发现丢包但能通过 FEC 分组算法还原,就不向发送端请求重传,如果分组内包是不能进行 FEC 恢复的,就向发送端请求原始的数据包。
FEC 分组方式适合解决要求延时敏感且随机丢包的传输场景,在一个带宽不是很充裕的传输条件下,FEC 会增加多余的包,可能会使得网络更加不好。FEC 方式不仅可以配合请求重传模式,也可以配合定时重传模式。
2)窗口与拥塞控制
RUDP使用一个收发的滑动窗口来配合对应的拥塞算法做流量控制,若涉及到可靠有序的RUDP,接收端就要做窗口排序和缓冲,如果是无序可靠或尽力可靠的场景,接收端就不做窗口缓冲。
3) 经典拥塞算法
A. 慢启动
B. 拥塞避免
C. 拥塞处理
D. 快速恢复。
6. 手写一个单例模式?
- 什么是单例模式?
答案
单例模式指在整个系统生命周期里,保证一个类只能产生一个实例,确保该类的唯一性,该实例被所有程序模块共享。单例模式分为懒汉式和饿汉式。
- 单例类的特点
答案
1) 构造函数和析构函数为private类型,目的禁止外部构造和析构
2) 拷贝构造和赋值构造函数为private类型,目的是禁止外部拷贝和赋值,确保实例的唯一性
3) 类里有个获取实例的静态函数,可以全局访问
答案
懒汉式是在指系统运行中,实例并不存在,只有当需要该实例时,才创建该实例。但注意,懒汉式并不是线程安全的,若要达到线程安全,则一个进行加锁。
懒汉式代码
#include <iostream>
#include <mutex>
#include <pthread.h>
using namespace std;
classs SignleInstance
{
public:
//获取单例对象
static SingleInstance *GetInstance();
//释放单例,进程退出时调用
static void deleteInstance();
//打印单例地址
void Print();
private:
//将其构造和析构函数都变成私有的,精致外部构造和析构
SingleInstance();
~SingleInstance();
//将拷贝构造和赋值构造成为私有函数,禁止外部拷贝和赋值
SingleInstance(const SingleInstance &signal);//拷贝构造
const SingleInstance &operator=(const SingleInstance &signal);//const 防止对实参的意外修改
//使用引用的原因
// 因为实参是通过按值传递机制传递的。在可以传递对象cigar之前,编译器需要安排创建该对象的副本。因此,编译器为了处理复制构造函数的这条调用语句,需要调用复制构造函数来创建实参的副本。但是,由于是按值传递,第二次调用同样需要创建实参的副本,因此还得调用复制构造函数,就这样持续不休。最终得到的是对复制构造函数的无穷调用。(其实就是创建副本也是需要调用复制构造函数的)
//所以解决办法先是要将形参改为引用形参:
private:
//唯一实例对象指针
static SingleInstance *m_SingleInstance;
static mutex m_Mutex;
};
//初始化静态成员变量
SingleInstance* SingleInstance::m_SingleInstance = NULL;
mutex SingeInstance::m_Mutex;
SingleInstance* SingleInstance::GetInstance()
{
//使用双检锁的方式 ,判断对象为空再进行加锁
if(m_SingleInstance ==NULLL)
{
unique_lock<mutex> lock<m_Mutex>;
if(m_SingleInstance ==NULLL)
m_SingleInstance = new (std::nothrow) SingleInstance;//线程并发的话有可能创建多个实例,非线程安全
}
return m_SingleInstance;
}
void SingleInstance::deleteInstance()
{
unique_lock<mutex> lock<m_Mutex>
if(m_SingleInstance)
{
delete m_SingleInstance;
m_SingleInsance = NULL;//若没有置空,容易出现野指针。
}
}
void SingleInstance::Print()
{
std::cout<<"我的实例内存地址是"<<this<<std::endl;
}
SingleInstance::SingleInstance()
{
std::cout << "构造函数" << std::endl;
}
SingleInstance::~SingleInstance()
{
std::cout << "析构函数" << std::endl;
}
//普通懒汉式实现---线程不安全
void *PrintHello(void *threadid)
{
}
int main(void)
{
pthread_t threads[NUM_THREADS] = {0};
int indexes[NUM_THREADS] = {0}; // 用数组来保存i的值
int ret = 0;
int i = 0;
std::cout << "main() : 开始 ... " << std::endl;
for (i = 0; i < NUM_THREADS; i++)
{
std::cout << "main() : 创建线程:[" << i << "]" << std::endl;
indexes[i] = i; //先保存i的值
// 传入的时候必须强制转换为void* 类型,即无类型指针
ret = pthread_create(&threads[i], NULL, PrintHello, (void *)&(indexes[i]));
if (ret)
{
std::cout << "Error:无法创建线程," << ret << std::endl;
exit(-1);
}
}
// 手动释放单实例的资源
SingleInstance::deleteInstance();
std::cout << "main() : 结束! " << std::endl;
return 0;
}
饿汉式是指系统一运行,就初始化创建实例,当需要时,直接调用即可。
饿汉式
//初始化静态成员变量
#if 0 懒汉模式
SingleInstance *SingleInstance::m_SingleInstance = NULL;
#endif
#if 1 饿汉模式
SingleInstance *SingleInstance::m_SingleInstance = new(nothrow) SingleInstance;
#endif
mutex SingeInstance::m_Mutex;
SingleInstance* SingleInstance::GetInstance()
{
#if 0 懒汉模式
//使用双检锁的方式 ,判断对象为空再进行加锁
if(m_SingleInstance ==NULLL)
{
unique_lock<mutex> lock<m_Mutex>;
if(m_SingleInstance ==NULLL)
m_SingleInstance = new (std::nothrow) SingleInstance;//线程并发的话有可能创建多个实例,非线程安全
}
#endif
#if 1 饿汉模式
return m_SingleInstance;//get方法,就直接返回即可。
#endif
}
- 单例模式中的懒汉式与饿汉式的区别
答案
1. 加锁与否的区别:懒汉式需要加锁,执行效率会较低。饿汉式不需要加锁,执行效率相对较高。
2. 初始化:饿汉式在初始化时就创建对象,容易产生不用的对象,浪费内存。懒汉式则没有这个问题。
总结:
懒汉式是以时间换空间(懒汉式需要加锁,饿汉式不需要加锁,加锁会降低程序的运行效率。但初始化时就创建对象容易产生无用的对象,浪费空间) 。所以懒汉式适用于访问量较小的场所,代码量相对较少。
饿汉式是以空间换时间(与上面的原因是相同的),适用于访问量较大的情况下,或者线程比较多的情况下。
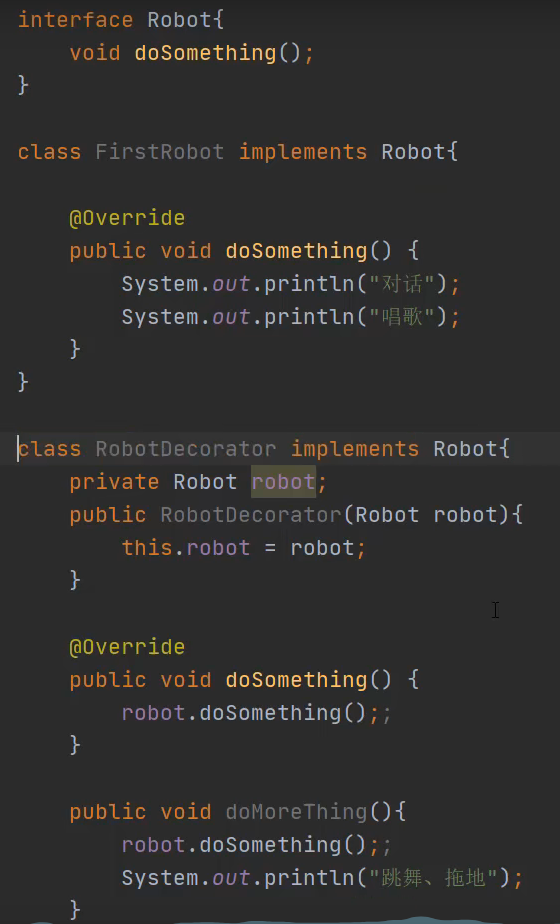
7. 手写一个装饰器模式(简单介绍一下装饰器模式)?
答案
1. 核心
在原有类的基础上动态添加新的功能。这种添加功能的方式不同于继承,它是在对象层级上实现功能的扩展,而不是在类层级上实现的。 装饰器模式属于结构型设计模式 。创建型设计模式可以理解为生成新的对象,结构型可以理解为构建更大的类或类对象。
2. 装饰器模式的优点:
1) 可以轻松对已存在的对象进行修改和包装,在被装饰者的前面或者后面添加自己的行为,而无需修改自己的行为。
2) 可以动态地,不限量的进行装饰,可以更灵活的扩展功能。
3. 装饰器模式的缺点:
1) 会加入大量的小类,即使只添加一个功能,也要额外创建一个类。
2) 增加代码复杂度。
8. 介绍一下I/O复用技术?并阐述一下他们的底层原理?
8.1 什么是IO多路复用?
答案
IO多路复用是一种同步文件描述符,实现在一个线程中监控多个文件描述符,一旦某个文件句柄就绪就能够去通知相应的应用程序进行读写操作,没有文件句柄就绪时就会阻塞应用程序,交出CPU。
8.2 说出你所知道的IO多路复用模型,并解释为什么IO多路复用效率高?
答案
select,poll,epoll都是IO多路复用的一种机制,就是通过一种机制可以监控多个文件描述符,一旦某个文件描述符就绪,就能够通知进程进行相应的读写操作。
效率高的原因:
也就是使用了IO多路复用之后,一个线程可以监控多个文件描述符,减少了线程的切换消耗以及CPU轮询损耗。
8.3 请你详细聊聊select?
答案
1. select的本质:
通过设置或者检查存放fd标志位的数据结构来进行下一步操作。
2. select的缺点有哪些?
1)单个进程可监视的fd数量被限制,即能监听端口的数量有限。(32位一般是1024,64位一般为2048)
2)对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低.所以,每次都得轮询一遍,很耗时间,要是能给套接字注册个回调函数,当他们活跃时,就自动完成相关操作。而这正是epoll与kquque所做的。
3) 需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递数据结构时复制开销大。
3. select 的优点?
1) select的可移植性更好,在某些Unix系统上不可以使用poll。
2) select的超时精度做的更精确,精确到us,poll只是精确到ms.
4. select的底层原理:
select会循环遍历它所监测的fd_set内的所有文件描述符对应的驱动程序的poll函数。
驱动程序提供的poll函数首先会将调用select的用户进程插入到该设备驱动对应资源的等待队列(如读/写等待队列),然后返回一个bitmask告诉select当前资源哪些可用。
8.4 请你详细聊聊poll?
答案
poll的本质:
将用户传入的数组拷贝到内核空间,然后查询每个fd的状态,若设备就绪,则在设备等待队列中加入一项并继续遍历。若遍历完所有的fd都没有就绪设备,则挂起当前进程,直到设备就绪或主动超时,被唤醒后,它又要再次遍历fd。
poll相比select的优点:
1)poll是基于链表的,基本没有最大连接数的限制。
poll的缺点:
1)大量的fd会被整体复制于用户态和内核地址空间之间,存在大量的性能损耗。
2)poll还有一个特点是 水平触发 。若报告了之后,该fd没有被处理。那么下次再次报告的时候,会再通知这个fd。(水平触发的含义是只要处于水平状态就会一直触发)
8.4 请你详细聊聊epoll?
答案
1. epoll的本质:
使用 事件 的 就绪通知机制。通过epoll_ctl 注册fd,一旦该fd就绪,内核就会采用类似于回调的机制通知应用程序进行处理。
2. epoll的优点:
1) epoll支持 水平触发 和 边缘触发 。它只会告诉进程一次,哪些fd刚刚变成了就绪态。
2) epoll使用事件通知的机制,就不用再像select与poll一样进行轮询了。
3) epoll的最大连接数被大大扩大了,上限远大于1024.
4) epoll通过mmap文件映射内存,加速了用户态与内核态之间的信息传递。
3. epoll的底层原理:
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
函数功能: create会生成一个红黑树和一个就绪链表。红黑树主要存储所监控的fd。就绪链表主要存储就绪的fd。当有fd的数据到来时,就会触发ctl.此时ctl会将该节点放入就绪链表中。wait也会收到信息,并将数据拷贝到用户空间,并清空链表。
工作过程:
执行epoll_ create时,创建了红黑树和就绪链表,执行epoll_ ctl时,如果增加socket句柄,则检查在红黑树中是否存在,存在立即返回,不存在则添加到树干上,然后向内核注册回调函数,用于当中断事件来临时向准备就绪链表中插入数据。执行epoll_wait时立刻返回准备就绪链表里的数据即可。
4. epoll的水平触发(LT)和边缘触发(ET)的含义:
1)水平触发模式:一个事件只要有,就会一直触发;类比于Socket的数据,只要数据没有读取结束,那么就会一直触发,只有读取结束,才会结束触发。
2)边缘触发模式:只有一个事件从无到有才会触发。而这个的类比是,只有新的数据到来时,才会有触发。
5. epoll的底层为什么使用红黑树而不使用哈希表?
1). 如果只是单纯的查找功能而已,当然用哈希表会比较好,但事实上不是,epoll的底层还需要对文件描述符进行添加,删除,那么就要选择时间复杂度最优的方式,所以,选择了红黑树,。
2). 红黑树占用的内存更少(仅需要为其存在的节点分配内存),而哈希函数事先就需要分配足够的内存存储散列表。
3). 哈希表在元素较多的时候,很容易冲突,有可能会导致查找速度下降。
6. epoll为什么不使用AVL树而使用红黑树?
1). 整体的旋转次数用红黑树较少:
a. 首先,AVL树与红黑树一样,在插入一个节点时,也是需要两次旋转。
b. 区别在于,在删除某个节点的时候,最坏情况下,AVL树需要维护从被删节点到根节点这条路径上所有node的平衡,因此需要旋转的量级O(logN),而红黑树只需要三次旋转。
2). AVL相比RB-Tree较为平衡,在插入删除的时候,更容易引起rebalance.
3). map的实现只在查找,插入,删除方面做了折中。
8.5 select和epoll区别?它们算同步还是异步io,同步异步区别在哪里?
答案
1) 通知机制
select 基于轮训机制
epoll基于操作系统支持的I/O通知机制 epoll支持水平触发和边沿触发两种模式
2) 都是同步io。
3) 同步io需要在读写事件就绪后,自己负责读写,而异步IO无需进行读写,它只负责发起事件具体的实现由别的完成。
4) select和poll需要自己不断的轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。 而epoll 其实也是需要不断的调用epoll_wait 不断轮询就绪链表。期间也可能多次睡眠和唤醒。 虽然都是睡眠和唤醒交替,但是select和poll醒着的时候就要遍历所有fd集合。而epoll只需要在“醒着” 的时候,判断一下就绪链表是否为空就行了。 这节省了大量的CPU时间。
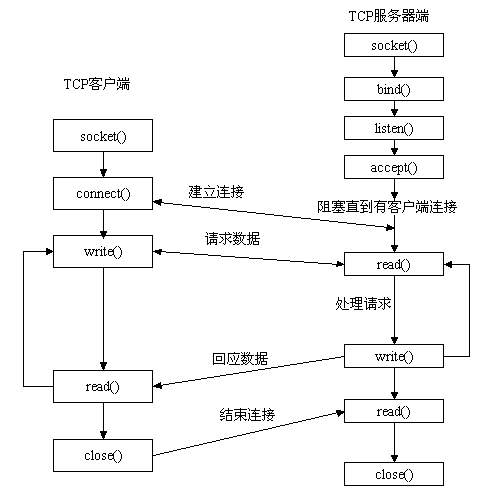
9. socket套接字进行通讯的整个流程?

答案
1. 每个进程在PCB(Process Control Block)中保存着一份文件描述符表,文件描述符就是这个表的索引,每个表项都有一个指向已打开文件的指针。
2. socket函数:
A. int socket (int protofamily,int type,int protocol);
1)protofamily:协议族,常见的协议族有AF_INET,AF_INET6,AF_LOCAL,AF_ROUTE.
2)type: socket类型,SOCK_STREAM,SOCK_DFRAM,SOCK_RAW,SOCK_PACKET,SOCK_SEQPACKET
3) protocol:指定协议,IPPROTO_TCP.IPPTOTO_UDP,IPPROTO_SCTP.
B. int bind(int sockfd,const struct *addr,socklen_t addlen);
1)sockfd,即socket描述字
2)addr:指向要绑定给sockfd的协议地址,
a. ipv4对应的是:
struct sockaddr_in{
sa_family_t sin_familt;/* address family: AF_INET */
int_port_t sin_port;/* port in network byte order */
struct in_addr sin_addr;/* internet address */
};
/* Internet address. */
struct in_addr {
uint32_t s_addr; /* address in network byte order */
};
b. ipv6对应的是:
struct sockaddr_in6 {
sa_family_t sin6_family; /* AF_INET6 */
in_port_t sin6_port; /* port number */
uint32_t sin6_flowinfo; /* IPv6 flow information */
struct in6_addr sin6_addr; /* IPv6 address */
uint32_t sin6_scope_id; /* Scope ID (new in 2.4) */
};
struct in6_addr {
unsigned char s6_addr[16]; /* IPv6 address */
};
c. Unix域对应的是:
#define UNIX_PATH_MAX 108
struct sockaddr_un {
sa_family_t sun_family; /* AF_UNIX */
char sun_path[UNIX_PATH_MAX]; /* pathname */
};
C. int listen(int sockfd, int backlog);
listen函数的第一个参数即为要监听的socket描述字,第二个参数为相应socket可以排队的最大连接个数。socket()函数创建的socket默认是一个主动类型的,listen函数将socket变为被动类型的,等待客户的连接请求。
D. int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
connect函数的第一个参数即为客户端的socket描述字,第二参数为服务器的socket地址,第三个参数为socket地址的长度。客户端通过调用connect函数来建立与TCP服务器的连接。
E. int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen); //返回连接connect_fd
参数sockfd
参数sockfd就是上面解释中的监听套接字,这个套接字用来监听一个端口,当有一个客户与服务器连接时,它使用这个一个端口号,而此时这个端口号正与这个套接字关联。当然客户不知道套接字这些细节,它只知道一个地址和一个端口号。
参数addr
这是一个结果参数,它用来接受一个返回值,这返回值指定客户端的地址,当然这个地址是通过某个地址结构来描述的,用户应该知道这一个什么样的地址结构。如果对客户的地址不感兴趣,那么可以把这个值设置为NULL。
参数len
如同大家所认为的,它也是结果的参数,用来接受上述addr的结构的大小的,它指明addr结构所占有的字节个数。同样的,它也可以被设置为NULL。
如果accept成功返回,则服务器与客户已经正确建立连接了,此时服务器通过accept返回的套接字来完成与客户的通信。
F.int close(int fd);
close一个TCP socket的缺省行为时把该socket标记为以关闭,然后立即返回到调用进程。该描述字不能再由调用进程使用,也就是说不能再作为read或write的第一个参数。
注意:close操作只是使相应socket描述字的引用计数-1,只有当引用计数为0的时候,才会触发TCP客户端向服务器发送终止连接请求。
socket编程实例:
服务端:
/* File Name: server.c */
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<errno.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#define DEFAULT_PORT 8000
#define MAXLINE 4096
int main(int argc, char** argv)
{
int socket_fd, connect_fd;
struct sockaddr_in servaddr;
char buff[4096];
int n;
//初始化Socket
if( (socket_fd = socket(AF_INET, SOCK_STREAM, 0)) == -1 ){
printf("create socket error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
//初始化
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);//IP地址设置成INADDR_ANY,让系统自动获取本机的IP地址。
servaddr.sin_port = htons(DEFAULT_PORT);//设置的端口为DEFAULT_PORT
//将本地地址绑定到所创建的套接字上
if( bind(socket_fd, (struct sockaddr*)&servaddr, sizeof(servaddr)) == -1){
printf("bind socket error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
//开始监听是否有客户端连接
if( listen(socket_fd, 10) == -1){
printf("listen socket error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
printf("======waiting for client's request======\n");
while(1){
//阻塞直到有客户端连接,不然多浪费CPU资源。
if( (connect_fd = accept(socket_fd, (struct sockaddr*)NULL, NULL)) == -1){
printf("accept socket error: %s(errno: %d)",strerror(errno),errno);
continue;
}
//接受客户端传过来的数据
n = recv(connect_fd, buff, MAXLINE, 0);
//向客户端发送回应数据
if(!fork()){ /*紫禁城*/
if(send(connect_fd, "Hello,you are connected!\n", 26,0) == -1)
perror("send error");
close(connect_fd);
exit(0);
}
buff[n] = '\0';
printf("recv msg from client: %s\n", buff);
close(connect_fd);
}
close(socket_fd);
}
客户端:
/* File Name: client.c */
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<errno.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#define MAXLINE 4096
int main(int argc, char** argv)
{
int sockfd, n,rec_len;
char recvline[4096], sendline[4096];
char buf[MAXLINE];
struct sockaddr_in servaddr;
if( argc != 2){
printf("usage: ./client <ipaddress>\n");
exit(0);
}
if( (sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0){
printf("create socket error: %s(errno: %d)\n", strerror(errno),errno);
exit(0);
}
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(8000);
if( inet_pton(AF_INET, argv[1], &servaddr.sin_addr) <= 0){
printf("inet_pton error for %s\n",argv[1]);
exit(0);
}
if( connect(sockfd, (struct sockaddr*)&servaddr, sizeof(servaddr)) < 0){
printf("connect error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
printf("send msg to server: \n");
fgets(sendline, 4096, stdin);
if( send(sockfd, sendline, strlen(sendline), 0) < 0)
{
printf("send msg error: %s(errno: %d)\n", strerror(errno), errno);
exit(0);
}
if((rec_len = recv(sockfd, buf, MAXLINE,0)) == -1) {
perror("recv error");
exit(1);
}
buf[rec_len] = '\0';
printf("Received : %s ",buf);
close(sockfd);
exit(0);
}
10. 介绍一下Qt的一些容器?
答案
1. QVector<T>
2. QList<T>
3. QStack<T>
4. QQueue<T>
5. QMap<Key,T>
6. QHash<Key, T>
11. 介绍一下Qt的信号和槽?
答案
1) Qt信号槽的底层原理:
Qt信号槽是需要Q_OBJECT宏支持的,程序在编译之前moc预处理器会对Q_OBJECT宏的类进行预处理,生成moc_xxxx.cpp来扩展当前类。内部由meta object来维护我们需要的信息和接口。moc工具会将SIGNAL和SLOT宏转换的信息编译转化在生成的moc_xxx.cpp文件中对应起来。
2) 通过 connect函数的第五个参数connectType来控制。
>1. Qt::AutoConnection:默认值,使用这个值则连接类型会在信号发送时自动确定。
>2. Qt::DirectConnection:若接受者和发送者在同一个线程,则自动使用。槽函数会在信号发送的时候直接被调用,槽函数运行于信号发送者所在线程。效果看上去就像是直接在信号发送位置调用了槽函数。这个在多线程环境下比较危险,可能会造成奔溃。
>3. Qt::QueuedConnection:如果接收者和发送者不在一个线程,则自动使用Qt::QueuedConnection类型。
>4. Qt::BlockingQueuedConnection:槽函数的调用时机与Qt::QueuedConnection一致,不过发送完信号后发送者所在线程会阻塞,直到槽函数运行完。接收者和发送者绝对不能在一个线程,否则程序会死锁。在多线程间需要同步的场合可能需要这个。
>5. Qt::UniqueConnection:这个flag可以通过按位或(|)与以上四个结合在一起使用。当这个flag设置时,当某个信号和槽已经连接时,再进行重复的连接就会失败。也就是避免了重复连接。
3) 信号槽的基本走法?
a. 通过元对象系统查询QConnection连接,并逐一分发至对应的槽函数。
b. 若是跨线程的队列连接,则需要通过Q_ARG将参数打包,通过Q_INVOKABLE的反射机制将调用请求和打包好的参数发送至目标线程的事件队列,由目标线程的事件循环负责调用。
12. 请你简要介绍一下STL?
答案
1) STL的各种容器,比如vector,map,hash-map,list,deque。以及各个容器的底层实现原理。
2) 还有其他部分也稍微了解了一下:
Container(容器) : 各种数据结构,如Vector,List,Deque,Set,Map,用来存放数据,STL容器是一种Class Template,就体积而言,这一部分很像冰山载海面的比率。
Adapter(适配器) : 一种用来修饰容器(Containers)或仿函数(Functors)或迭代器(Iterators)接口的东西,例如:STL提供的Queue和Stack,虽然看似容器,其实只能算是一种容器配接器,因为 它们的底部完全借助Deque,所有操作有底层的Deque供应。改变Functor接口者,称为Function Adapter;改变Container接口者,称为Container Adapter;改变Iterator接口者,称为Iterator Adapter。
Algorithm(算法) : 各种常用算法如Sort,Search,Copy,Erase,从实现的角度来看,STL算法是一种Function Templates。
Iterator(迭代器) : 扮演容器与算法之间的胶合剂,是所谓的“泛型指针”,共有五种类型,以及其它衍生变化,从实现的角度来看,迭代器是一种将:Operators*,Operator->,Operator++,Operator--等相关操作予以重载的Class Template。所有STL容器都附带有自己专属的迭代器——是的,只有容器设计者才知道如何遍历自己的元素,原生指针(Native pointer)也是一种迭代器。
Function object(函数对象) :行为类似函数,可作为算法的某种策略(Policy),从实现的角度来看,仿函数是一种重载了Operator()的Class 或 Class Template。一般函数指针可视为狭义的仿函数。
Allocator(分配器): 负责空间配置与管理,从实现的角度来看,配置器是一个实现了动态空间配置、空间管理、空间释放的Class Template。
3) 类模板与函数模板的一些特点
函数模板与类模板的区别:
a. 第一行是template开头,后面跟着函数,则为函数模板,若为类,则为类模板。
b. 类模板不支持参数自动推导。
c. 类模板在模板参数列表中可以有默认参数。
13. 请你简要介绍一下C++11的相关内容?
答案
1). lambda表达式[]()->{}.
2). 移动语义
3) 完美转发
4) 右值引用
5) 自动类型推导auto 和表达式推导decltype
6) 空指针常量 nullptr 代表void(*)
7) 列表初始化
14. 请你简要介绍一下C++17的内容?
答案
1. 内联变量: 之前C++ 类的静态成员变量在头文件中是不能初始化的,但是有了内联变量,就可以达到此目的。
inline int const A::value = 10;
15. 请你讲一下你了解哪些MySQL的性能优化技术?
在这里插入图片描述
答案
一、基本写法优化
1、少使用select * ,尽量使用具体字段;
2、对于条件来说等号之类两边的字段类型要一致,字符串不加单引号索引会失效;
3、尽量少使用Order By 排序,对于需要多个字段进行排序的可以使用组合索引;
4、对于group by 语句要先过滤后分组;
5、在查询时减少使用null,对字段有多个null的可以加默认值;
6、少使用like,对于需要使用的, 如需要使用尽量用 like abc%这种,不要把%放字段前面;
7、在where后面少使用函数或者算数运算;
8、去除的distinct 过滤字段要少,避免 distinct * ;
9、不要超过5个以上的表连接。
二、 建立使用合适索引
1、对于高频筛选字段可以适当的建立索引;
2、一个表的索引最好不要超过5个,多了会影响插入修改;
3、不要对值是有限重复的字段建立索引,如性别等;
4、使用组合索引一定要遵守最左原则;
三、替代优化
1、不要使用not in 和<>,这个会破坏索引,not in 可以用not exists 来代替,<>可以分成两个条件 >或者<等;
2、使用连接(join)来代替子查询;
二、工作经历
1. 你说你做过一些简易版的SDK,写过什么SDK呢?
答案
1. 仿照海康MVS做的采图及参数显示软件。该软件具有的功能有实时采图,触发采图,采用树形结构显示相机参数。
2. 做的一个服务端采集图片,由客户端进行显示的一个C/S架构的demo。做这个的主要原因是:服务端采集图片的相机是没有VGA口或是任何可以输出界面的接口,只有一个网口。所以,采用这样的方式,就可以操作相机做一些操作了。
2. 公司主要的产品有哪些,介绍一下?
答案
智能相机、视觉系统主机、OCR字符识别检测设备、视觉一体机
三、项目经历
第一个项目
1. 简单介绍一下回调函数以及描述一下如何使用回调函数?
1)概念
答案
一个通过函数指针调用的函数称为回调函数。
2)如何使用?
答案
将函数指针作为形参传给另一个函数,在函数中,去使用这个函数指针,就可以调用上层的某些代码,这样就可以实现在特定的事件或条件发生时由另一方调用,用于对该事件或条件进行响应。
2. 为什么使用select函数,而不使用epoll函数?
答案
因为每时每刻这些连接的socket都有事件发生(比如:服务期间的心跳信息,还有大型网络游戏的同步信息(一般每秒在20-30次)),最重要的是,这种场景下,并发量(并发量是指规定时间内的请求数量。)也不会很大。如果此时用epoll,为此所建立的文件系统,红黑书和链表对于此来说就是杀鸡用牛刀,效率反而不高。
第二个项目
1. 介绍一下共享内存(共享内存你是怎么实现的?)
共享内存是进程通信中最简单的方式之一。共享内存允许两个或多个进程访问同一个内存,当一个进程修改了其中的内容时,其他进程都会察觉到。
1)QSharedMemory: 可以访问共享内存区域,以及多线程和进程的共享内存区域。
答案
QSharedMemory m_sharedmemory;//声明该共享内存
m_sharedmemory.setKey(m_cSharedMemoryName); //设置该共享内存的名字作为标识符ifif(m_sharedmemory.create(size,QSharedMemory::ReadWrite))
{
m_sharedmemory.lock(); //对该共享内存进行加锁
char *dest = (char*)m_sharedmemory.data(); //将该共享内存的数据指针该dest
const char *src = byteArray.constData(); //将要同步到该共享内存的数据同步给指针
memcpy(dest,src,size); //数据从该进程中拷贝到共享数据内存中
m_sharedmemory.unlock(); //共享内存解锁
}
m_sharedmemory.attach(); //尝试将该共享内存段连接到该进程。
if(m_sharedmemory.isAttached()) //判断该共享内存是否连接在该进程
m_sharedmemory.detach(); //该共享内存与该进程解连接
2)QSystemSemaphore:用于访问系统共享资源,以实现独立进程间的通信。主要用于进程间的协调。
3)QSemaphore:线程间的通讯可以用QSemaphore调控,以保证各个线程对同一资源的访问不冲突。
答案
#include <QtCore/QCoreApplication>
#include <QSemaphore>
#include <QThread>
#include <iostream>
#include <QTime>
/*
*Qt中的信号量是由QSemaphore类提供的,信号量可以理解为对互斥量功能的扩展,互斥量只能锁定一次而信号
* 量可以获取多次,它可以用来保护一定数量的同种资源。
* acquire()函数用于获取n个资源,当没有足够的资源时调用者将被阻塞直到有足够的可用资源。release(n)函数用于释放n个资源。
*/
const int DataSize = 100;
const int BufferSize = 10;
char buffer[BufferSize];
QSemaphore freeSpace(BufferSize);//信号量保护bufferSize个资源
QSemaphore usedSpace(0);//usedSpace保护0个资源
//当DataSize = 100, BufferSize = 1时,程序运行的界面如下,结果是可以预期的。生产者每次生产一个,消费者就消费一个。
//当DataSize = 100, BufferSize = 10时,程序运行的界面如下,结果是不可预期的
class Producer : public QThread
{
protected:
void run()
{
qsrand(QTime(0, 0, 0).secsTo(QTime::currentTime()));
qsrand(NULL);
for (int i = 0; i < DataSize; ++i)
{
freeSpace.acquire();//尝试获取n个资源由信号量进行守护,这个调用将会阻塞直到足够的资源可用。
std::cerr<<"P";
usedSpace.release();//创建新资源
}
}
};
class Consumer : public QThread
{
protected:
void run()
{
for (int i = 0; i < DataSize; ++i)
{
usedSpace.acquire();//尝试获取资源进行守护
std::cerr<<"C";
freeSpace.release();//创建新资源
}
std::cerr<<std::endl;
}
};
int main(int argc, char *argv[])
{
Producer producer;
Consumer consumer;
producer.start();
consumer.start();
producer.wait();
consumer.wait();
return 0;
}
2. 介绍一下Qt的反射调用
答案
1. 前提准备
Qt的反射机制是基于moc(meta object compile)实现的。必须要继承于Q_OBJECT类,且在头文件的结构声明上写上Q_OBJECT即可。
2. 在moc的过程中会做的事情?
1) 识别一些特殊的宏Q_OBJECT,Q_PROPERTY,Q_INVOKER.会自动生成对应的moc文件。
2)识别slot,signals
1) 什么是反射机制?
所谓反射机制,是指在运行时,能获取任意一个类对象的所有类型信息,属性,成员函数等信息的一种机制。
2)Qt 反射前的准备?
a. 需要继承于Q_Object,同时需要在class中加入Q_OBJECT.
b. 注册类成员变量需要使用Q_PROPERTY
Q_PEROPERTY(type member READ get WRITE set).其调用方式是使用property和setproperty.
c. 注册类成员函数
如果希望某个函数能够被反射,那么只需要再类的函数声明前加入Q_INVOKABLE关键字,使用Q_INVOKABLE 来修饰成员函数,目的在于被修饰的成员函数能够被元对象系统所唤起。
3. 你学到了哪些提升程序性能的方法?
答案
1. 零拷贝技术。
2. I/O多路复用技术。
3. 线程池技术
4. 无锁编程技术
5. 共享内存(高频次的大量数据交互)
6. 缓存技术 && 布隆过滤器
4. 所以高速状况下,你是如何保持好IO的稳定性与有序性的?
答案
使用队列与共享内存保持IO的有序性。
5. 阐述一下TCP在应用层是否会丢包?
答案
不会的,TCP只会在传输层丢包,不会在应用层丢包,传输层一旦丢包,就会不断重传,如果网络环境很糟糕的话,那就会断开连接,所以在应用层不会出现丢包的情况。
6. 多线程是如何控制同步的?
答案
1) 同步的概念: 同步就是协同步调,按预定的先后次序进行运行。不要理解成同时进行,而是指协同,协助,互相配合。
2) 线程同步的概念: 线程同步是指多线程通过特定的设置(如信号量,事件对象,临界区)来控制线程之间的执行顺序,也就是在多线程之间通过同步建立起执行顺序的关系。
3) 线程互斥的概念: 线程互斥是指对于共享的进程系统资源,在各单个线程访问时的排它性。当有若干个线程都要使用某一共享资源时,任何时刻最多只允许一个线程去使用,其它要使用该资源的线程必须等待,直到占用资源者释放该资源。线程互斥可以看成是一种特殊的线程同步.
4) 线程同步的方式和机制:
A. 临界区(critical Section)、互斥对象(mutex):主要是互斥控制,都具有拥有权的控制方法,只有拥有该对象的线程才能执行任务。
a.临界区: 通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问。在任意时刻只允许一个线程对共享资源进行访问. 可以解决线程互斥问题,但无法解决线程同步问题。
b.互斥对象: 采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。互斥量是内核对象,它也是拥有“线程所有权”,但不能用于线程的同步。
B. 信号量(Semaphore),事件对象(Event):事件对象是以通知的方式进行控制,主要是用于同步控制。
a. 信号量: 信号量也是内核对象,它允许多个线程在同一时刻访问同一资源,但是需要限制在同一时刻访问此资源的线程最大数目。
b. 事件对象: 通过通知操作的方式来保持线程的同步,方便实现对多个线程的优先级比较。
6.1 信号量与互斥锁之间的区别
答案
1)根本区别: 互斥量用于线程的互斥,信号量用于线程的同步。
互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。互斥量只能锁定一次而信号量可以获取多次,它可以用来保护一定数量的同种资源。
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源.
2) 互斥量值只能为0/1,信号量值可以为非负整数。
一个互斥量只能用于一个资源的互斥访问,不能实现多个资源的多线程互斥问题。信号量可以实现多个同类资源的多线程互斥和同步。
3) 互斥量的加锁和解锁必须由同一线程分别对应使用,信号量可以由一个线程释放,另一个线程得到。
6.2 信号量的分类
答案
1) 二进制信号量,只允许信号量取0或是1,其同时只能被一个线程获取。
2) 整型信号量: 信号量取值是整数,它可以被多个线程同时获得,直到信号量的值变为0.
3) 记录型信号量: 每个信号量s除一个整数值value(计数)外,还有一个等待队列List,其中是阻塞在该信号量的各个线程的标识。当信号量被释放一个,值被加一后,系统自动从等待队列中唤醒一个等待中的线程,让其获得信号量,同时信号量再减一。
7. 讲一下几个比较重要的排序?
- 快速排序
算法思路
1)从待排序的n个记录中任意选取一个记录(通常选取第一个记录)为分区标准;
2)把所有小于该排序列的记录移动到左边,把所有大于该排序码的记录移动到右边,中间放所选记录,称之为第一趟排序;
3)然后对前后两个子序列分别重复上述过程,直到所有记录都排好序。
稳定性:不稳定
平均时间复杂度:O(nlogn)
答案
int once_quick_sort(vector<int>& data, int left, int right)
{
int key = data[left];
while (left < right)
{
while (left < right && key <= data[right])
{
right--;
}
if (left < right)
{
data[left] = data[right];
left++;
}
while (left < right && key > data[left])
{
left++;
}
if (left < right)
{
data[right] = data[left];
right--;
}
}
data[left] = key;
return left;
}
int quick_sort(vector<int>& data, int left, int right)
{
if (left >= right)
{
return 1;
}
int middle = 0;
middle = once_quick_sort(data, left, right);
quick_sort(data, left, middle - 1);
quick_sort(data, middle + 1, right);
}
- 归并排序:
算法思路
采用分治思想,现将序列分为一个个子序列,对子序列进行排序合并,直至整个序列有序。 总结为:递归分块,回溯合并。
稳定性:稳定
平均时间复杂度:O(nlogn)
代码
class Solution {
public:
vector<int> sortArray(vector<int>& nums) {//归并排序
int left=0;
int right=nums.size()-1;
MergeSort(nums,left,right);
return nums;
}
void MergeSort(vector<int>&nums,int left,int right)
{
if(left<right)//只要left<right,最终情况是left=right,即数组长度为1,单独一个数,肯定是有序的
{
int mid=(left+right)/2;//取中点
MergeSort(nums,left,mid);//左边块递归排序
MergeSort(nums,mid+1,right);
Merge(nums,left,mid,mid+1,right);//左右块合并
}
}
void Merge(vector<int>&nums,int L1,int R1,int L2,int R2)//L1,R1是第一块的左右索引,L2R2同理,将两个块合并
{
int temp[R2-L1+1];//存放合并后的有序数组(这里没用vector,用了会提示内存不足)
int i=L1;
int j=L2;
int k=0;
while(i<=R1 && j<=R2){
if(nums[i]<nums[j])
{
temp[k++]=nums[i++];
}
else
{
temp[k++]=nums[j++];
}
}//while结束之后若有某块没遍历完(另一块肯定已经遍历完),剩下的数直接赋值
while(i<=R1) temp[k++]=nums[i++];
while(j<=R2) temp[k++]=nums[j++];
for(int i=0;i<k;i++)//合并后的数赋值回原来的数组
nums[L1+i]=temp[i];
}
};
- 堆排
算法思想
**堆排的思想**:利用堆进行排序的思想,将待排序的序列构成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点,再将它移走(其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值),然后将剩余的n-1个序列重新构建成一个大顶堆,这样就是得到这n个元素序列的次小值,如此反复进行,便能得到一个有序序列。
堆排序的时间复杂度为O(n*log(n)), 非稳定排序,原地排序(空间复杂度O(1))。
代码
#include <cstdio>
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
void adjust(int arr[],int len,int index)
{
int left = 2*index+1;
int right = 2*index+2;
int maxIdx = index;
if(left<len&&arr[left]>arr[maxIdx])
maxIdx = left;
if(right<len&&arr[right]>arr[maxIdx])
maxIdx = right;
if(maxIdx!=index)
{
swap(arr[maxIdx],arr[index]);
adjust(arr,len,maxIdx);//这个是递归调整这个节点下面的所有节点进行排序
}
}
void heapSort(int arr[],int size)
{
for(int i = size/2;i>=0;i++)
adjust(arr,size,i);
for()
}
int main()
{
int array[8] = {8,1,14,3,21,5,7,10};
heapSort(array,8);
for(auto it:array)
{
cout<<it<<endl;
}
return 0;
}
8. Qt的智能指针是如何用的?
项目总体问题
1. 看你简历里写了那些设计模式,你在重构的过程中用过哪些设计模式?
答案
1) 其实最简单的就是模板方法模式,这个基于继承的设计模式,基本是我在重构过程中使用的主要模式。将上层依赖于抽象层,也就是模板结构,然后,在继承的子类去具体实现不同的行为。
2) 单例模式也有用到,基本在IO模块那边这种方法是很常见的,因为有时候,设备的句柄基本就是只有一个,所以使用单例模式去获取,就保证获取句柄的正确性。
3) 观察者模式,这个模式的特点是其一对多的通知特性。那么在Qt中体现最多的就是信号槽了。
2. 你做过的最难的项目是什么?
答案
最难的项目应该就是简历中写的这两部分的重构了,说实话,当时基本对设计模式没有什么概念,所以,基本是在自己慢慢模式以及主管的指导下逐渐完成重构的,主要还是抽象层的设计花费了我很多的功夫。因为要尽可能的考虑不同相机,不同IO的各种方法,所以,抽象层一定要尽可能全面,并且,还有一些成员变量可能也得做一些方法去底层获取,所以,其实也是在不断完善的一个过程吧。
3. 你在做项目过程中遇到最难的问题是什么?
答案
其实只要最后能够解决的问题也都不算很难的问题啦。所以,我就讲几个我影响比较深刻的bug吧。
第一个: 在有次需要使用句柄获取相机数据的时候,发现总是采一会图,就程序自动崩溃了,后面找了很久,发现是select的特性之一,其在32位系统上一般支持1024个句柄设备的监控,64位支持2048个,所以,后面将句柄标志控制在指定的范围内,就可以了。
第二个: 首先讲一下背景: Qt有两种开辟线程的方式,一种是继承于QThread,将需要在子线程跑的代码写在run函数中,一种是把某个类moveToThread的一个线程 就可以了。 我这里出问题的是第一种方法:在run函数中跑子线程的代码。 就是我有这样的一个需求,就是含有run函数的这个类的某个函数,需要根据run函数中的某个值,判断自己是继续执行。
几种思路:
1. 使用信号槽的方式,通知外面,但发现这种方式不可行。
2. 直接讲最后的解决办法: 使用QEventLoop将run外面的那个函数阻塞掉。等待某个全局变量,也就是当run函数中条件成熟时,将某个全局变量置为True.这样就可以继续执行了。当然,run函数外面的那个函数也要做好超时机制。
4. 你的重构主要是重构了哪方面的内容?(重点问题)
答案
1) 将Sensor从之前的3.0摘出来,成为一个动态库。
2) 将整个文件结构整理了一下,之前是所有include,src都放在一起,现在就按照相机类型,IO类型进行拆分。
3) 使用模板方法模式,整理了一下抽象层,让上层依赖于抽象层,底层也依赖于抽象层。
四、技术面总体问答
1. 在这个项目的过程中最让你满意的是什么?
答案
1) 相机这个项目: 对内存的管理较为恰当,基本可以连续运行24小时。
2) IO这个项目: 则是对IO的稳定性以及有序性让我较为满意。
2. 能不能介绍一下你平时遇到的一个比较印象深刻的问题,以及你的解决思路。(准备3个问题进行探讨)
答案
1) 线程中的非run函数需要根据run函数的状态去更改。
a. 直接非run中延时。直接卡住1s。体验很差。
b. QEventLoop来做循环卡住的一个功能。等待run函数中去调用loop.quit.释放这个循环,使非run函数继续运行。
c. 在run中做一个变量作为状态的判定。在非run函数中,用这个变量来进行while循环,当状态更改时,就可以跳出while循环。
3. 你最近看过哪些书?讲一些你的感悟?
1 设计模式
答案
学习了一些比较常见的模式,比如单例模式,观察者模式,模板方法模式,装饰器模式
2. Effective C++
答案
讲几个印象比较深的点:
1. 调用empty而不是检查size()是否为0。因为empty对所有的标准容器都是常数时间操作,而对一些list实现,size耗费线性时间
2. 切勿对STL容器的线程安全性有不切实际的依赖。 STL不支持线程安全,想要线程安全,那自己加锁就完事儿了。
3. 切勿直接修改set或multiset中的键
4. 程序如果直接崩溃了,你们平常有没有使用一些软件去查找并定位问题点。
1.Linux系统下的程序崩溃
答案
方法一: 捕获系统信号
Linux操作系统提供了一组接口可以修改信号对应的默认回调。通过这组接口,当出现错误信号的时候,将程序的执行流程引导到我们自定义的回调函数中,在这里我们可以调用另外一组系统接口获得当前错误出现时的堆栈信息,有了堆栈信息,就可以很方便的定位到程序最后出错时的代码位置。
方法二: core dump
Linux程序在崩溃的时候可以产生core文件,这个文件记录了程序崩溃时的状态,有了core文件,就可以还原发生崩溃时的场景,并且还可以使用gdb进行调试。
方法三:直接进行部署远程调试即可。
2. Windows下的程序崩溃
答案
方法一: 在编译环境下查看打印的调试信息。从而大体知道出错的点在哪。
5. 你是怎么防止内存泄漏,或者说防止出现程序崩溃的?
答案
1. 使用智能指针。QSharedPoint和QPoint,QScopedPoint。
2. 一定要确保申请的内存异地你有对应的释放。
6. 如何检测内存泄漏?
答案
因为内存泄漏是在堆内存中,所以对我们来说并不是可见的。通常我们可以借助MAT、LeakCanary等工具来检测应用程序是否存在内存泄漏。
1、MAT是一款强大的内存分析工具,功能繁多而复杂。
2、LeakCanary则是由Square开源的一款轻量级的第三方内存泄漏检测工具,当检测到程序中产生内存泄漏时,它将以最直观的方式告诉我们哪里产生了内存泄漏和导致谁泄漏了而不能被回收。
3. 外挂式的内存泄漏检测工具:BoundsChecker
4. 使用Performance Monitor检测内存泄漏。
四、技术面反问
1. 咱公司的技术栈的需求是怎么样的?
2. 技术人员的整体晋升通道是怎么样的?
3. 研发岗这部分大约有多少个人呢?
五、HR面询问
1. 你的职业规划是怎么样的?
答案
1) 分为两个阶段,一个是死磕技术,在技术方面能通过查询沟通,解决遇到的技术难题。
2) 第二个阶段,关注业务。学着如何为项目提出可信服的方案。
2. 你做过的最难的项目是什么?
答案
最难的项目应该就是简历中写的这两部分的重构了,说实话,当时基本对设计模式没有什么概念,所以,基本是在自己慢慢模式以及主管的指导下逐渐完成重构的,主要还是抽象层的设计花费了我很多的功夫。因为要尽可能的考虑不同相机,不同IO的各种方法,所以,抽象层一定要尽可能全面,并且,还有一些成员变量可能也得做一些方法去底层获取,所以,其实也是在不断完善的一个过程吧。
3. 为什么跳槽?
答案
主要是由于现在的工作对我已经没有了太大的提升了,所以,我希望找一份更有挑战性的工作。