1.不相交集合操作:
集合嘛!就是集合论中的集合.它包括无序,确定,互异性.
a.不相交集合定义:任意两个集合的交集为空.这样对于任意一个数据(元素),它只能属于这个不相交集合族中的某一个集合里面!
b.其数据结构: 不相交集合数据结构保持一组不相交的动态集合S={S1, S2,…, Sk}。每个集合通过一个代表来识别,代表即集合中的某个成员。选择代表成员视乎具体应用,如选择最小元素。其中Si表示一个集合,Si这个集合可以通过其中的一个元素root予以代表.
2.对数据结构的操作:集合中的每一个元素是由一个对象表示的。设x表示一个对象,支持以下操作:
1)Make-set(x):建立一个新的集合,其唯一成员就是x。各集合是不相交的,所以x没有在其他集合中出现过;
2)Union(x,y):将包含x和y的动态集合(Sx和Sy)合并成一个新的集合(并集SxUSy),当然Sx和Sy是不相交的.
3)Find-set(x):返回一个指针,指向包含x的唯一集合的代表.
3.时间复杂度分析:
见算法导论! 分析要结合具体组织方式.
4.数据结构的组织方式:
一共有两种!
1.链表.即一条链表示一个集合
2.有根树.具体就是由一群树构成的森林
5.数据结构的优化:
可以采用以下两种方式进行优化:
1.路径压缩--两层深度的树,降低深度,方便find.
2.按秩合并--即考虑树结点数目
通常两种优化都需要用,才能有更好的效率!
接着我们就对并查集采用有根树的数据结构进行设计和分析,并最终进行测试!
首先定义两个数据结构:
1.parent数组,parent[i]表征i下标的父节点对应的下标;
2.rank[]数组,,,rank[i]表征下标为i的结点,并以其为根节点的子树的高度或者层次深度
我们有以下几种操作:
1.find(x)
找到x下标对所在的根节点,其实就是找到它所在集合的代表!由于parent数组的缘由,可以借助parent数组进行递归的查找
代码:
1 int findroot(int x) 2 { 3 if(par[x]==-1) return x; 4 else return par[x]=findroot(par[x]); 5 }
2.unite(x,y)
这个操作就相应的复杂点,一般效率下可以直接把其中一个元素的代表插在另一个元素的代表之下,当作此代表的一棵新的子树! (两个元素所在的集合都是树结构).在对效率有较高要求时,可以对其进行高度判断,这样把整合的一棵新树的高度限制下来,保证了查找操作的平均查找时间的降低.
1 void unite(int x,int y) 2 { 3 int xroot=findroot(x),yroot=findroot(y); 4 if(xroot!=yroot) 5 { 6 if(rk[xroot]<rk[yroot]) 7 { 8 par[x]=y; 9 } 10 else if(rk[xroot]>rk[yroot]) 11 { 12 par[y]=x; 13 } 14 else 15 { 16 par[y]=x; 17 rk[x]++; 18 } 19 } 20 }
注意:在合并前因为两棵树不一定就是二层深度的树,所以合并之后的树可能会发生深度的变化,如:
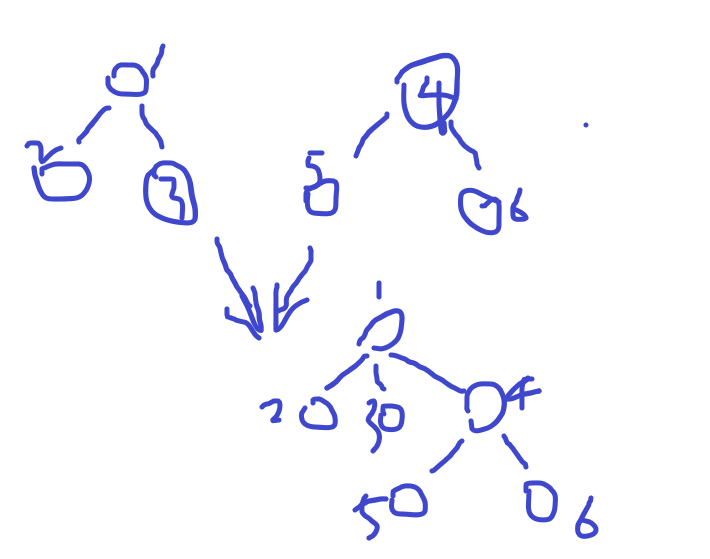
所以,合并操作我们可以看到,不能保证树必定是二层深度的树,而路径压缩即find()操作中shiy使用的技术可以帮助把这种杂乱的树结构给局部"压缩",例如:find(5), 在函数执行时(路径压缩),可以把从5到根节点的路径上的所有节点的父亲都指向根节点,这样在查找的过程中就对先前合并操作得到的杂乱无章的树给优化了一点.
容易想到,当对所有节点都进行了查找后,整个树森林的所有树都变成了"矮树".
另外一种数据结构: 链表
每一条链都可以表示一个集合,它可以方便插入元素,删除元素,或者整合两个集合.链表所具有的性质都为并查集的实现提供了完美的环境,当然,能用有根树这么简单的结构,又为何用链表这种结构呢?
小伙伴们,有兴趣的可以尝试一下这种新的数据结构呦
最后说一点:
并查集是集合论中的内容,是一种数学概念,不是数据结构,它可以通过多种数据结构来实现!以上的两种数据结构就刚好可以实现.