导入相关包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rc('font', family='SimHei', size=13)
import os,gc,re,warnings,sys
warnings.filterwarnings("ignore")
读取数据
path = './data/'
#####train
trn_click = pd.read_csv(path+'train_click_log.csv')
item_df = pd.read_csv(path+'articles.csv')
item_df = item_df.rename(columns={'article_id': 'click_article_id'}) #重命名,方便后续match
item_emb_df = pd.read_csv(path+'articles_emb.csv')
#####test
tst_click = pd.read_csv(path+'testA_click_log.csv')
数据预处理
rank函数设置ascending=False则按从大到小排序,即最后一次点击的排名为1
# 对每个用户的点击时间戳进行排序
trn_click['rank'] = trn_click.groupby(['user_id'])['click_timestamp'].rank(ascending=False).astype(int)
tst_click['rank'] = tst_click.groupby(['user_id'])['click_timestamp'].rank(ascending=False).astype(int)
#计算用户点击文章的次数,并添加新的一列count
trn_click['click_cnts'] = trn_click.groupby(['user_id'])['click_timestamp'].transform('count')
tst_click['click_cnts'] = tst_click.groupby(['user_id'])['click_timestamp'].transform('count')
#将文章信息合并到点击日志中,得到最终的训练集
trn_click = trn_click.merge(item_df, how='left', on=['click_article_id'])
注:rank函数用法
按从小到大排序,输出对应的排名,若有多个相同的值,排名取平均值。
例如:
import pandas as pd
obj = pd.Series([7,-5,7,4,2,0,4])
print(obj.rank())
从小到大排序为[-5,0,2,4,4,7,7],-5最小,对应的排名为1。因为有两个相同的7(分别排名为6,7),所以7排名为(6+7)/2 = 6.5
输出:
0 6.5
1 1.0
2 6.5
3 4.5
4 3.0
5 2.0
6 4.5
dtype: float64
总体数据浏览
# 查看前5行数据
trn_clicl.head()

#获取各个特征的基本属性
trn_click.describe()
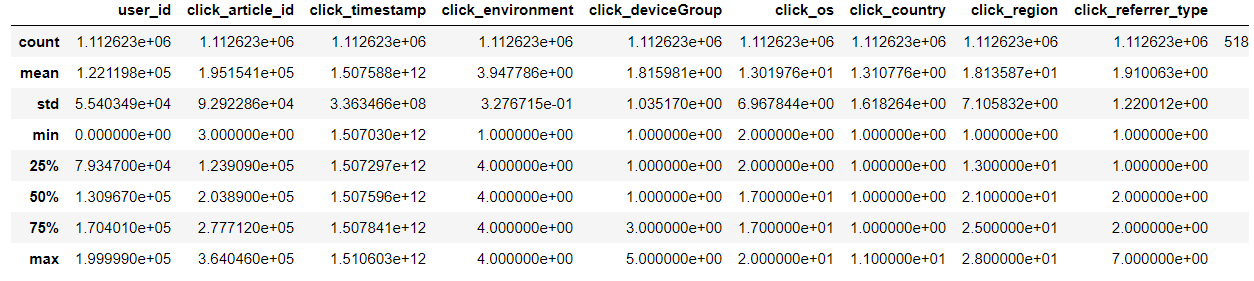
#查看各个特征的分布情况,纵坐标为百分比
plt.figure()
plt.figure(figsize=(15, 20))
i = 1
for col in ['click_article_id', 'click_environment', 'click_deviceGroup', 'click_os', 'click_country',
'click_region', 'click_referrer_type', 'rank', 'click_cnts']:
plot_envs = plt.subplot(5, 2, i)
i += 1
v = trn_click[col].value_counts().reset_index()[:10]
fig = sns.barplot(x=v['index'], y=v[col]/trn_click.shape[0]*100)
plt.title(col)
plt.tight_layout()
plt.show()
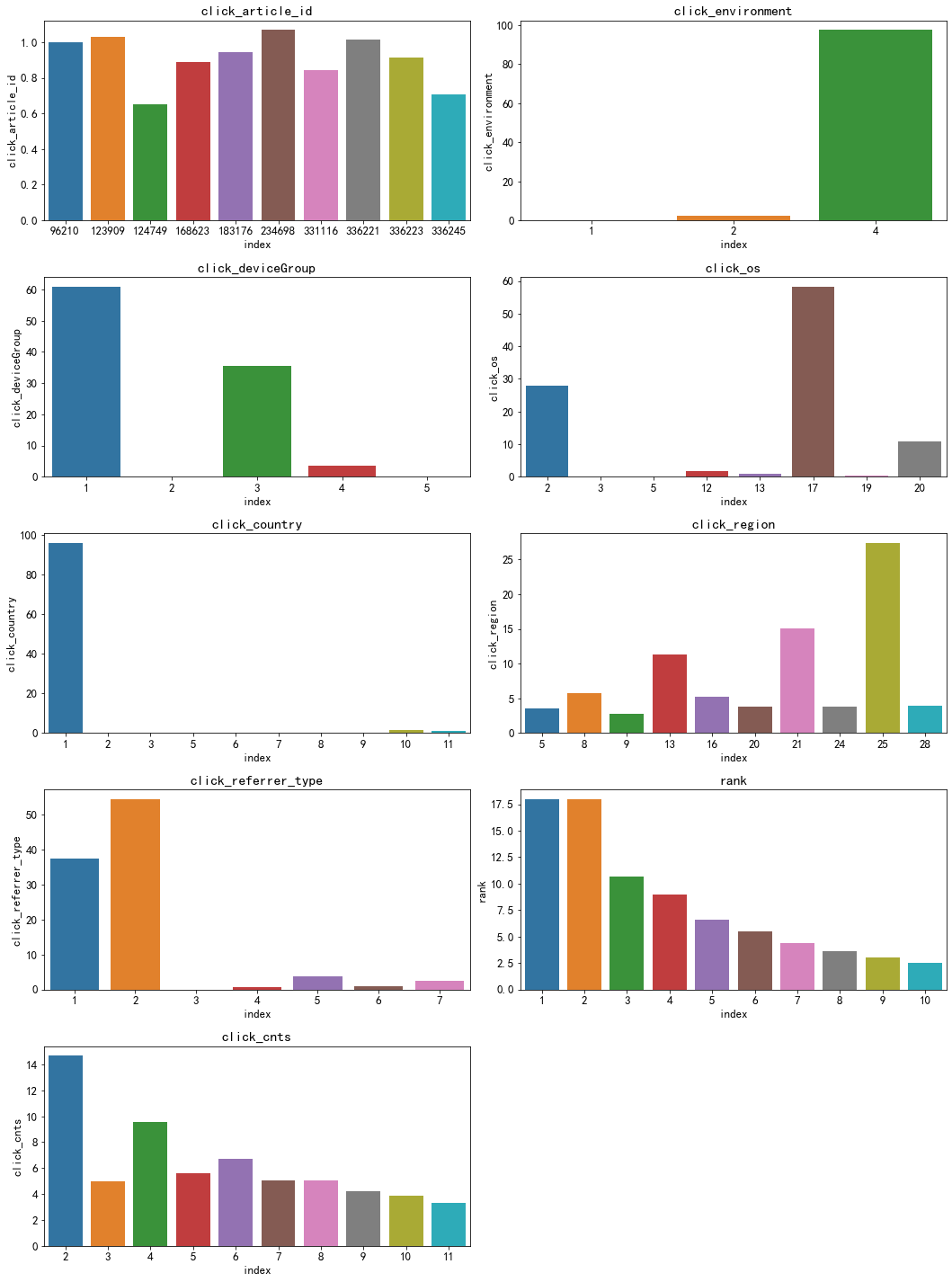
对于新闻id而言,阅读最多的占了总文章数目的1%,点击环境最多的是4(90+%),其他的分析就不一一叙述了,我们可以从这些图片可视化各个特征的分布情况,为下一步的分析提供参考。
文章信息查看
- 文章类型分布
print(item_df['category_id'].nunique()) # 461个文章主题
plt.plot(sorted(item_df['category_id'].value_counts()))
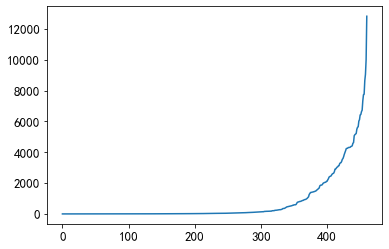
不同类别的文章数目分布差异较大,绝大多数类型的文章数目少于1000
-
文章字数分布
item_df['words_count'].value_counts() 176 3485 182 3480 179 3463 178 3458 174 3456 ... 845 1 710 1 965 1 847 1 1535 1 Name: words_count, Length: 866, dtype: int64文章的字数大多在100-200之间
-
文章被点击次数统计
item_click_count = sorted(user_click_merge.groupby('click_article_id')['user_id'].count(), reverse=True)
plt.plot(item_click_count)
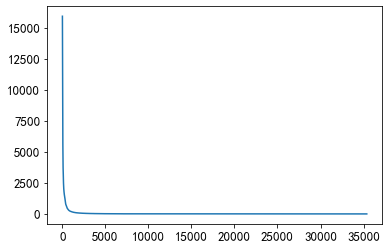
点击量大于1000的文章可以认为是热门文章
用户信息查看
- 点击次数
#画出点击次数在前50的用户
user_click_merge = trn_click.append(tst_click)
user_click_item_count = sorted(user_click_merge.groupby('user_id')['click_article_id'].count(), reverse=True)
plt.plot(user_click_item_count[:50])
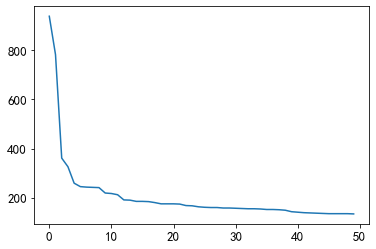
可以看见前50名的点击次数都大于100,一种思路是把点击次数大于100的作为活跃用户。
- 点击文章类型查看
plt.plot(sorted(user_click_merge.groupby('user_id')['category_id'].nunique(), reverse=True))
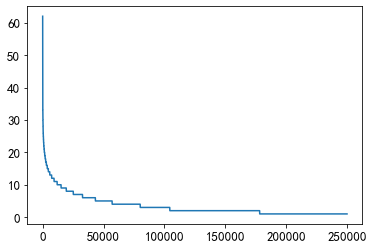
由图可见大部分人的点击次数在10次以下,只有少部分人的点击次数比较广泛
-
点击文章长度查看
plt.plot(sorted(user_click_merge.groupby('user_id')['words_count'].mean(), reverse=True))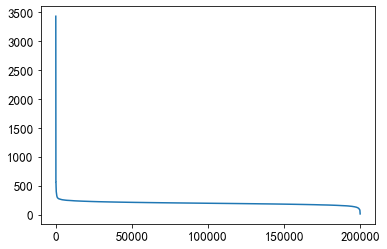
大多数人都在200-300之间,说明大家对短文更感兴趣。
总结
经过分析可以得出如下的结论:
- 可以通过数据查看确定热门文章和热门用户
- 不同文章的长度和文章类型被点击的次数不一样
- 文章本身分布差异也很大,不同类型的和不同字数的文章数目本身也不一样,所以可能导致2.的情况出现