一,背景知识
进程即正在执行的一个过程。进程是对正在运行程序的一个抽象。
进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一。操作系统的其他所有内容都是围绕进程的概念展开的。
所以想要真正了解进程,必须事先了解操作系统,点击进入
PS:即使可以利用的cpu只有一个(早期的计算机确实如此),也能保证支持(伪)并发的能力。将一个单独的cpu变成多个虚拟的cpu(多道技术:
时间多路复用和空间多路复用+硬件上支持隔离),没有进程的抽象,现代计算机将不复存在。
理论基础
#一 操作系统的作用: 1:隐藏丑陋复杂的硬件接口,提供良好的抽象接口 2:管理、调度进程,并且将多个进程对硬件的竞争变得有序 #二 多道技术: 1.产生背景:针对单核,实现并发 ps: 现在的主机一般是多核,那么每个核都会利用多道技术 有4个cpu,运行于cpu1的某个程序遇到io阻塞,会等到io结束再重新调度,会被调度到4个 cpu中的任意一个,具体由操作系统调度算法决定。 2.空间上的复用:如内存中同时有多道程序 3.时间上的复用:复用一个cpu的时间片 强调:遇到io切,占用cpu时间过长也切,核心在于切之前将进程的状态保存下来,这样 才能保证下次切换回来时,能基于上次切走的位置继续运行
二,进程
进程:正在进行的一个过程或者说一个任务。而负责执行任务则是cpu。
1,并发与并行
无论是并行还是并发,在用户看来都是'同时'运行的,不管是进程还是线程,都只是一个任务而已,真是干活的是cpu,cpu来做这些任务,而一个cpu同一时刻只能执行一个任务
(1),并发:并发是伪并行,即看起来是同时运行。单个cpu+多道技术就可以实现并发,(并行也属于并发)
(2) 并行:同时运行,只有具备多个cpu才能实现并行
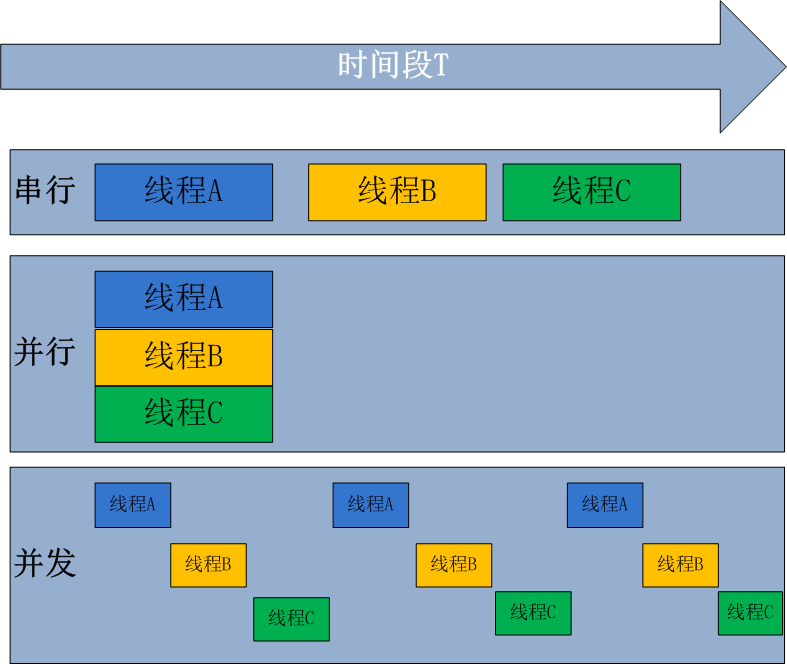
所有现代计算机经常会在同一时间做很多件事,一个用户的PC(无论是单cpu还是多cpu),都可以同时运行多个任务(一个任务可以理解为一个进程)。
启动一个进程来杀毒(360软件)
启动一个进程来看电影(暴风影音)
启动一个进程来聊天(腾讯QQ)
所有的这些进程都需被管理,于是一个支持多进程的多道程序系统是至关重要的
多道技术概念回顾:内存中同时存入多道(多个)程序,cpu从一个进程快速切换到另外一个,使每个进程各自运行几十或几百毫秒,这样,虽然在某一个瞬间,一个cpu只能执行一个任务,但在1秒内,cpu却可以运行多个进程,这就给人产生了并行的错觉,即伪并发,以此来区分多处理器操作系统的真正硬件并行(多个cpu共享同一个物理内存)
进程间的数据不会共享
data_list = [] def task(arg): data_list.append(arg) print(data_list) def run(): for i in range(5): p = Process(target=task,args=(i,)) p.start() if __name__ == '__main__': run()
打印结果
[0] [4] [2] [1] [3]
通过类创建进程
# 通过继承类来创建进程 class Myprocess(Process): def run(self): print(f"当前进程{multiprocessing.current_process()}") if __name__ == '__main__': for i in range(4): p = Myprocess() p.start()
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
from multiprocessing import Pool import os def func(i): print(f"进程{i} id>>>{os.getpid()}") if __name__ == '__main__': p = Pool(5) for i in range(6): p.apply_async(func, args=(i,)) p.close() p.join() # join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
print("end")
进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
from multiprocessing import Process, Queue import os,time,random # 写数据进程执行的代码 def write(q): print("Process to write: %s" % os.getpid()) for value in ['A',"B",'C']: print(f"Put {value} to queue...") q.put(value) time.sleep(random.random()) # 读数据进程执行代码 def read(q): print(f"Process to read: {os.getpid()}") while 1: value = q.get(1) print(f'Get {value} from queue.') if __name__ == '__main__': # 父进程创建Queue,并传给各个子进程 q = Queue() pw = Process(target=write, args=(q,)) pr = Process(target=read, args=(q,)) # 启动子进程write,写入 pw.start() # 启动子进程pr读取 pr.start() # 等待pw的结果 pw.join() # pr进程里是死循环,无法等待其结束,只能强行终止: pr.terminate()
Manager进程间数据共享
from multiprocessing import Process, Manager def task(arg, dic): time.sleep(0.5) dic[arg] = 100 if __name__ == '__main__': m = Manager() dic = m.dict() process_list = [] for i in range(10): p = Process(target=task, args=(i, dic,)) p.start() # p.join() process_list.append(p) while True: count = 0 for p in process_list: if not p.is_alive(): # is_alive 看进程是否还存活着 count += 1 if count == len(process_list): break print(dic)
# ##################### 进程间的数据通信,其他电脑 ##################### def task(url, dic): ''' 假设写了个爬虫,爬取的数据url对应的数据 :param url: :param dic: :return: ''' dic[url] = "res..." pass if __name__ == '__main__': while True: # 连接上指定的服务器 # 去机器上获取url url = 'adfasdf' p = Process(target=task, args=(url,)) p.start()
进程锁
进程锁与线程锁的用法一模一样
为什么要加锁,用到锁是因为数据共享,数据不安全,而进程默认是数据隔离的;当不同的进程用到相同的数据时(进程间通信,数据共享),才用到进程锁。
线程加锁是因为同一进程下的多线程数据是共享的,线程不安全(多个线程改同一个变量把内容改乱了),加锁是为了线程安全。
import multiprocessing import time lock = multiprocessing.Lock() def task(arg): print("进程来了") lock.acquire() time.sleep(2) print(arg) lock.release() if __name__ == '__main__': p1 = multiprocessing.Process(target=task, args=(1,)) p1.start() p2 = multiprocessing.Process(target=task, args=(2,)) p2.start()