随机试验:可重复性,可观察性,不确定性。
条件概率
P(B|A) = P(AB)/P(A),为事件A发生的条件下事件B的发生概率。
概率乘法公式:
P(AB) = P(B|A)P(A) = P(A|B)P(B)
事件独立:两事件的发生没有影响。P(B|A) = P(B)。
P(AB) = P(B|A)P(A) = P(A)P(B)
全概率公式
如果事件A1,A2,…,An是完备事件组,且都有正概率,则有P(B) = P(A1)P(B|A1) + P(A2)P(B|A2) + … + P(An)P(B|An)
贝叶斯公式,对一完备事件组A1,A2,…,An,对仍一事件B,P(B)>0,则有
P(Ai|B) = P(AiB)/P(B),对P(B)应用全概率公式,
P(Ai|B) = P(Ai)P(B|Ai)/ΣP(Ai)P(B|Ai)
已知某事件已发生,可以通过贝叶斯公式考察引发该事件的各种原因和可能性的大小。
贝叶斯推断
应用观察到的现象对主观概率(先验概率)进行修正。支持某项属性的事件发生得越多,该属性成立的可能性越大。
先验概率:由以往经验和分析中得到的概率,作为“由因求果”问题中“因”出现的概率。一般是单独的概率,如患病概率,下雨概率,购物概率等。
后验概率:在得到“结果”的信息后重新修正的概率,是“执果索因”中的“果”。后验概率的计算要以先验概率为基础。形式一般和条件概率相同。
最大似然估计:以当前样本的分布参数作为总体的参数的最佳估计。

P(H|E) 后验概率
P(H) 先验概率
P(E|H), P(E) 证据。
最大后验概率估计:融入了要估计的先验分布,是最大似然估计的规则化。
朴素贝叶斯
一种分类算法,通过计算样本归属于不同类别的概率进行分类。
贝叶斯理论:基于能获得的最好证据,来计算信念度的有效方法。信念度即为对事物真实性和正确性所具有的信心。
朴素:单纯、简单假设给定目标值时属性之间相互条件独立。如果这个条件不成立,不能用朴素贝叶斯。
朴素贝叶斯模型
m个样本,每个样本n个特征,输出为k个类。
通过样本学习得到先验概率,即分类为某个值的概率。
通过样本学习条件概率,即分类为某值时样本为某个的概率。
计算联合概率,分类为某项时样本为某个分布的概率。
一个例子
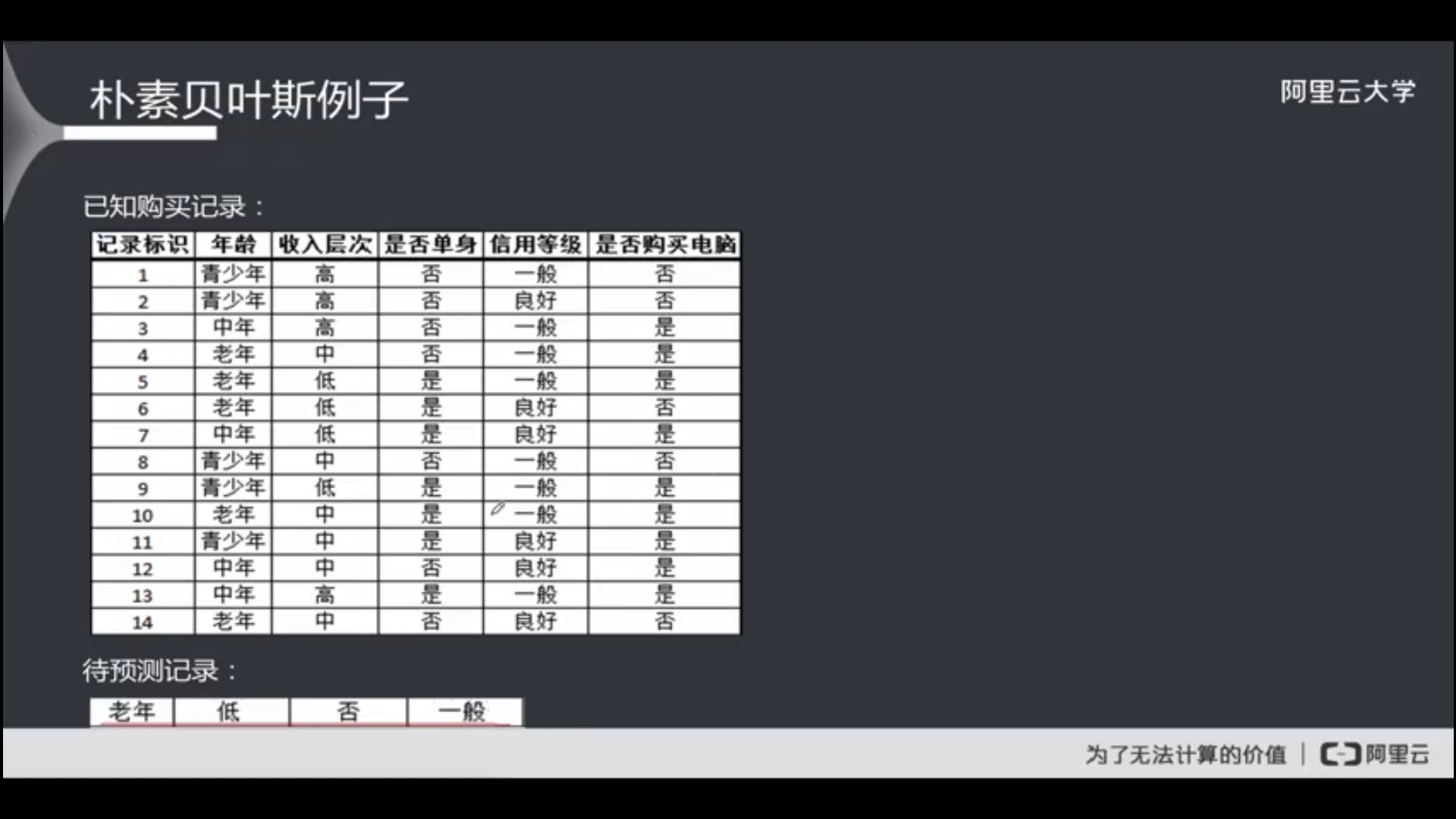
课程是用手算的,我试试用sklearn。
sklearn主要提供GaussianNB(高斯朴素贝叶斯)、MultinomialNB(多项式朴素贝叶斯)、BernoulliNB(伯努利朴素贝叶斯)。后两者主要用于离散特征分类。
手工将数据输入csv文件,读入以后再将数据数值化,最后建模,输出。
朴素贝叶斯的例子
import pandas as pd
from sklearn.naive_bayes import MultinomialNB
数据转换
def transform(data):
data.loc[data.Age == "青少年", "Age"] = 1
data.loc[data.Age == "中年", "Age"] = 2
data.loc[data.Age == "老年", "Age"] = 3
data.loc[data.Income == "高", "Income"] = 1
data.loc[data.Income == "中", "Income"] = 2
data.loc[data.Income == "低", "Income"] = 3
data.loc[data.Alone == "是", "Alone"] = 1
data.loc[data.Alone == "否", "Alone"] = 2
data.loc[data.Credit == "良好", "Credit"] = 1
data.loc[data.Credit == "一般", "Credit"] = 2
data.loc[data.Buy == "是", "Buy"] = 1
data.loc[data.Buy == "否", "Buy"] = 2
return data
if name == "main":
data = pd.read_csv("data.csv")
print(data)
data = transform(data)
print(data)
train_data = data[["Age", "Income", "Alone", "Credit"]]
test_data = data["Buy"]
test = np.array([3, 3, 2, 2])
print(test)
print("测试输出")
print(data.values)
进行朴素贝叶斯分类模型训练
clf = MultinomialNB(alpha = 2.0)
clf.fit(data.values, test_data)
print(clf.class_log_prior_)
用模型预测
print(clf.predict(test))
print(clf.predict_proba(test))
运行结果
[1]
[[0.66684573 0.33315427]]
拉普拉斯平滑
有时会碰到零概率的问题,由于其中某个概率为0,相乘导致整个概率为0。拉普拉斯平滑通过在分子分母上加上调整解决这一问题。即上面程序里的alpha参数。
优点
有统计理论背书,分类效率稳定。
支持多分类任务。
对缺失数据不敏感。
算法简单,模型容易解释。
计算量小,支持海量数据。
支持增量式计算,可做在线预测。
缺点
需要有先验概率,不同值对结果有影响。
分类决策存在错误率。
对输入数据表达形式敏感。
"朴素"的假设对结果影响大。
接下来,试试用这个算法来解决泰坦尼克号问题吧。
课程也看完了,好像不全,还有其它方法没讲。再找找看有没有其它课程。
本文代码:
https://github.com/zwdnet/MyQuant/tree/master/21
我发文章的四个地方,欢迎大家在朋友圈等地方分享,欢迎点“在看”。
我的个人博客地址:https://zwdnet.github.io
我的知乎文章地址: https://www.zhihu.com/people/zhao-you-min/posts
我的博客园博客地址: https://www.cnblogs.com/zwdnet/
我的微信个人订阅号:赵瑜敏的口腔医学学习园地