变量之间的非确定性相关关系。
一般形式:y = f(x0,x1,x2,…xp)+ε
若为线性回归,y = β0+β1x1+β2x2+…+βnxn+ε
β0,β1等为回归系数,ε为随机误差。
模型假设
①零均值,ε均值为0
②同方差,ε项方差为常数
③无自相关性,ε项值之间无自相关性
④正态分布,ε项呈正态分布。
⑤x1,x2等解释变量之间是非随机变量,其观测值是常数。
⑥解释变量之间不存在精确线性关系。
⑦样本个数多于解释变量个数。
建立回归分析模型的一般步骤
①需求分析明确变量
②数据收集加工,检查是否满足回归分析断的假设。
③确定回归模型:一元,二元,多元;线性,非线性。画散点图。
④确定模型参数:常用最小二乘法,若不符合假设条件,可用其它方法。
最小二乘法也叫最小化平方法,通过使误差的平方和最小来寻找最佳函数匹配。
⑤模型检验优化
⑥模型部署应用。
优点:模型简单,应用方便;有坚实的理论支撑;定量分析各变量间关系;模型预测结果可通过误差分析精确了解。
缺点:假设条件比较多且严格;变量选择对模型影响较大。
回归模型的参数估计
一元线性回归模型:研究与现象关系最大的主要因素,两者有密切关系,但并非确定性关系,可用该模型。
y = β0+β1x+ε
y为被解释变量或因变量,x为解释变量或自变量。β0回归常数,β1回归系数,二者统称为回归参数。ε为随机误差。其中E(ε) = 0,var(ε) = 常数。
一元线性回归方程:y = β0+β1x 忽略随机误差。
回归方程从平均意义上表达了变量y与x的统计规律性。
回归分析的主要任务是通过n组样本的观察值,对β0,β1进行估计,得到最终方程。
参数估计:最小二乘估计(OLE)
通过最小二乘法求出对β0,β1的估计值。
离差平方和Q(β0,β1)=Σ(yi - E(yi))²=Σ(yi -β0+β1xi)²
估计值满足使上式离差平方和最小。
其最小值的求法为求其偏导数,并令其为0。求解方程组即可。
实操一下。
先创建数据,画散点图。
x = [3.4, 1.8, 4.6, 2.3, 3.1, 5.5, 0.7, 3, 2.6, 4.3, 2.1, 1.1, 6.1, 4.8, 3.8]
y = [26.2, 17.8, 31.3, 23.1, 27.5, 36, 14.1, 22.3, 19.6, 31.3, 24, 17.3, 43.2, 36.4, 26.1]
x = np.array(x)
y = np.array(y)
print(len(x), len(y))
plt.scatter(x, y)
plt.savefig("scatter.png")
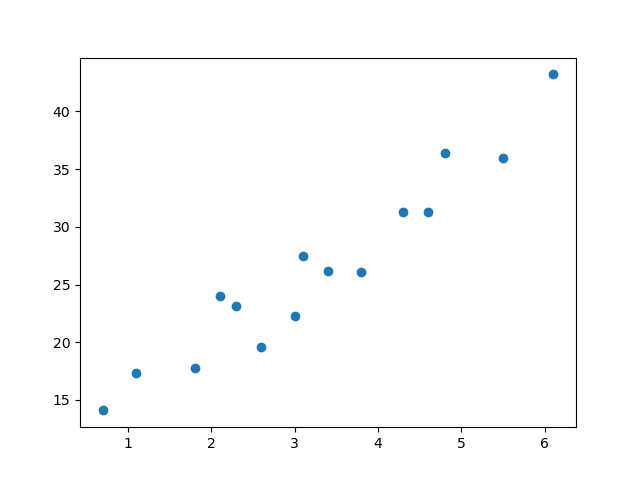
建立线性回归模型
df pd.DataFrame()
df["X"] = x
df["Y"] = y
print(df)
regr = linear_model.LinearRegression()
# 拟合
regr.fit(x.reshape(-1,1), y)
# 得到回归参数的二乘法估计
a, b = regr.coef_, regr.intercept_
print(a, b)
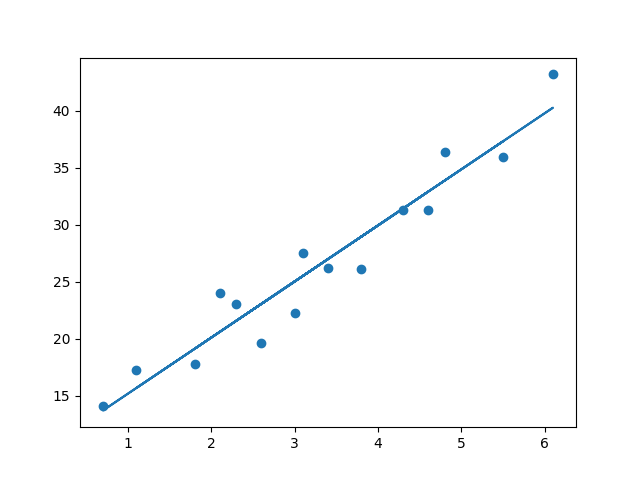
# 画出拟合的直线
yp = a*x + b
plt.scatter(x, y)
plt.plot(x, yp)
plt.savefig("fit.png")
拟合结果
a = 4.91933073 b = 10.277928549524688
另一种参数估计方法:最大似然估计(MLE)
利用总体的分布密度或概率分布的表达式及其样本所提供的信息求未知参数估计量的一种方法。
基本思路:已知样本符合某种分布,但分布参数未知,通过实验来估计分布参数。估算思路:如果某组参数能使当前样本出现的概率最大,就认为该参数为最终的估计值。解决的是模型已定,参数未知的问题,用已知样本去估算未知参数。
出现当前情形的概率为f(x1x2x3…xn|θ)=f(x1|θ)f(x2|θ)f(x3|θ)…f(xn|θ),其中θ未知。
似然函数L(θ|x1x2x3…xn) = f(x1x2x3…xn|θ)=f(x1|θ)f(x2|θ)f(x3|θ)…f(xn|θ)=Πf(xi|θ)
前提是事件x之间是独立的。
取对数lnL(θ|x1x2x3…xn) = lnf(x1|θ)+lnf(x2|θ)+lnf(x3|θ)+…+lnf(xn|θ) = Σf(xi|θ)
平均对数似然l = lnL(θ|x1x2x3…xn)/n
最大似然估计就是找到一个θ使得l最大。求导求出最大值。
一元线性回归,OLE和MLE是等价的,MLE还可以估计方差σ²的值。
无偏估计,估计不同样本,偏差平均值为0。反之则为有偏估计。
一元线性回归方差的性质:
①线性:估计回归参数为随机变量yi的线性函数。
②无偏,估计值y为真实值的无偏估计,即E(y) = E(y)
③参数的方差,与样本方差,随机误差的方差等有关系。
模型的检验
①回归系数是否显著:t检验
检验因变量y与自变量x之间是否真的存在线性关系?即β1=0?用t检验进行判断。
确定假设:目的是找到不达标的证据。原假设H0:β0=0,备择假设H1:β0≠0
检验水平:α=0.05或0.01
构造统计量:H0成立时,β1满足正态分布。
计算p值。
得出结论。
②回归方程是否显著:F检验。
根据平方和分解式,直接从回归效果检验回归方程的显著性。
③相关系数显著性检验:t检验。
样本相关系数可以作为总体相关系数的估计值,样本相关系数不等于零时需要进行假设检验确定是来自抽样误差还是来自整体。
④决定系数
SST = SSR + SSE, SSR占的比重越大,线性回归效果越好。
r² = SSR/SST
用模型的score函数来给模型评分,结果为0.9234781689805285。
还可以用statsmodels库来做,回归结果类似,与sklearn库不同的是它可以输出检验结果。
用statsmodels来做
import statsmodels.api as sm
X = sm.add_constant(x)
model = sm.OLS(y, X)
result = model.fit()
print("statsmodels做线性回归")
print(result.params)
print(result.summary())
结果及解释(以下参考:https://blog.csdn.net/CoderPai/article/details/83899268)
OLS Regression Results
Dep. Variable: y
R-squared: 0.923
Model: OLS
Adj. R-squared: 0.918
Method: Least Squares
F-statistic: 156.9
Date: Fri, 14 Feb 2020
Prob (F-statistic): 1.25e-08
Time: 15:48:01
Log-Likelihood: -32.811
No. Observations: 15
AIC: 69.62
Df Residuals: 13
BIC: 71.04
Df Model: 1
Covariance Type: nonrobust
coef std err t P>|t| [0.025 0.975]
const 10.2779 1.420 7.237 0.000 7.210 13.346
x1 4.9193 0.393 12.525 0.000 4.071 5.768
Omnibus: 2.551
Durbin-Watson: 1.318 Prob(Omnibus): 0.279
Jarque-Bera (JB): 1.047 Skew: -0.003 Prob(JB): 0.592 Kurtosis: 1.706 Cond. No. 9.13
Adj. R-squared: 0.918 R平方,反映模型的拟合度,取值0-1,越高越好。
const coef:10.2779 y截距,即b值。
x1:4.9193 a值,即一元线性方程的一次项。
std err,反映系数的准确度,越低,准确度越高。
P>|t|:p值,判断回归参数是否有统计学意义。本处均为0。
Confidence Interval:这是置信区间,表示我们的系数可能下降的范围(可能性为 95%)
另外回归方程的F值F-statistic:156.9,概率Prob (F-statistic):1.25e-08,小于0.05,回归分析效果是显著的。
残差(residual):回归值与真实值的差额。
ei = yi^-yi
残差是误差的估计值。
残差图,以x为横轴,残差为纵轴做的图。残差应在0附近随机变动,且变动不大。
残差图的几种情况。
算出上面回归的残差并绘出残差图。
residual = []
for i in range(len(x)):
cha = res[0] + res[1]*x[i] - y[i]
residual.append(cha)
print(residual)
plt.scatter(x, residual)
plt.savefig("residual.png")
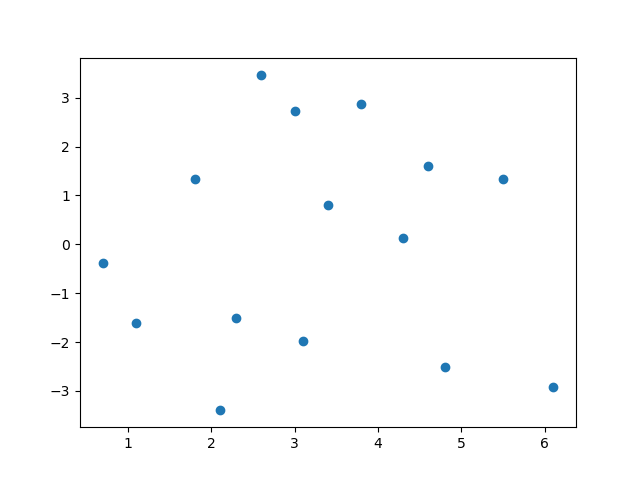
可以看到残差图还是比较正常的。
模型的应用,有预测和控制。
预测分为单值预测和区间预测。
单值预测直接求值。
区间预测:以α显著水平,找到区间(T1,T2),使得某特定X0的实际值Y0以1-α的概率在该区间内。即p(T1<Y0<T2) = 1-α。
控制:要把因变量控制在一定范围内,求自变量的取值范围。
下次学习多元回归。
本文代码:https://github.com/zwdnet/MyQuant/tree/master/15
我发文章的四个地方,欢迎大家在朋友圈等地方分享,欢迎点“在看”。
我的个人博客地址:https://zwdnet.github.io
我的知乎文章地址: https://www.zhihu.com/people/zhao-you-min/posts
我的博客园博客地址: https://www.cnblogs.com/zwdnet/
我的微信个人订阅号:赵瑜敏的口腔医学学习园地