Python语言程序设计基础
第7章 文件和数据格式化
文件的使用
文件概述
概念上,文件是数据的集合和抽象。
文件包括两种类型:文本文件和二进制文件。文本文件一般由单一特定编码的字符组成,如UTF-8编码,内容容易统一展示和阅读。由于文本文件存在编码,因此,它也可以被看作是存储在磁盘上的长字符串。二进制文件直接由比特0和比特1组成,没有统一字符编码,文件内部数据的组织格式与文件用途有关。二进制文件和文本文件最主要的区别在于是否有统一的字符编码。二进制文件由于没有统一字符编码,只能当字节流。
无论文件是创建为文本文件还是二进制文件,都可以用“文本文件方式”和“二进制文件方式”打开。采用二进制方式打开文件,文件被解析为字节流(Byte);采用文本方式读入文件,文件经过编码形成字符串。
文件打开关闭
Python对文本文件和二进制文件采用统一的操作步骤,“打开——操作——关闭”.

- 首先,需要打开文件。
- 打开后的文件处于占用状态,此时另一个程序不能操作这个文件。此时,文件作为一个数据对象存在,采用<a>.<b>方式进行操作
- 操作后需要将文件关闭,关闭释放对文件的控制是文件恢复存储状态,此时另一个进程能够操作这个文件
open函数
open()函数格式如下:
<变量名> = open(<文件名> , <打开模式>)
open()函数有两个参数:文件名和打开模式。文件名可以是文件的实际名字,也可以是包含完整路径的名字。打开模式用于控制使用何种方式打开文件。
文件的打开模式 7个
| 文件的打开模式 | 含义 |
|---|---|
| ‘r’ | 只读模式,如果文件不存在,返回异常FillNotFoundError,默认值 |
| ‘w’ | 覆盖写模式,文件不存在则创建,存在则完全覆盖 |
| ‘x’ | 创建写模式,文件不存在则创建,存在则返回异常FileExistsError |
| ‘a’ | 追加写模式,文件不存在则创建,存在则在文件最后追加内容 |
| ‘b’ | 二进制文件模式 |
| ‘t’ | 文本文件模式,默认值 |
| ‘+‘ | 与r/w/x/a 一同使用,在原功能的基础上增加同时读写功能 |
close 函数
文件使用结束后要用close()方法关闭。
文件的读写
文件内容读取方法
| 操作方法 | 含义 |
|---|---|
| <file>.readall() | 读入整个文件内容,返回一个字符串或字节流* |
| <file>.read(size=-1) | 从文件中读入整个文件内容,如果给出参数,读入前size长度的字符串或字节流 |
| ~ |
从文件中读入一行内容,如果给出参数,读入该行前size长度的字符串或字节流 |
| 从文件中读入所有行,以每行为元素形成一个列表,如果给出参数,读入hint行 |
文本的全文本操作
1 一次性读入
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
txt = fo.read
#对全文txt进行处理
fo.close
2 循环遍历 分段
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
txt = fo.read(2)
while txt != "":
#对全文txt进行处理
txt = fo.read(2)
fo.close
逐行遍历
1 一次读入,分行处理
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
for line in fo.readlines():
print(line)
fo.close()
2 逐行读入处理
fname = input("请输入要打开的文件名称:")
fo = ope(fname,"r")
for line in fo:
print(line)
fo.close()
文件内容写入
| 方法 | 含义 |
|---|---|
| <file>.write(s) | 向文件写入一个字符串或字节流 |
| <file>.writelines(lines) | 将一个元素作为字符串的列表写入文件,元素拼接之间没有空格 |
| <file>.seek(offset) | 改变当前文件操作元素指针的位置,offset的值:0——文件开头;1——当前位置;2——文件结尾 |
代码示例
fo =open("output.txt","w+")
ls= ["中国","法国","美国"]
fo.writelines(ls)
for line in fo:
print(line)
fo.close()
实际没有输出任何信息。因为指针在输入的内容后方,想要输出需要将指针放大文件头部进行遍历。这就是seek()函数的作用
fo =open("output.txt","w+")
ls= ["中国","法国","美国"]
fo.writelines(ls)
fo.seek(0)
for line in fo:
print(line)
fo.close()
模块5 PIL库的使用
PIL库概述
PIL库支持图形存储、显示和处理。PIL库主要可以实现图像归档和图像处理两方面功能需求。
- 图像归档:对图像进行批处理、生成图像预览、图像格式转换等
- 图像处理:图像基本处理、像素处理、颜色处理
Image类
from PIL import Image
image类的图像读取和创建方法
| 方法 | 描述 |
|---|---|
| Image.open(filename) | 根据参数加载图像文件 |
| Image.new(mode,size,color) | 根据指定参数创建一个新的图像 |
| Image.open(StringIO,StringIo(buffer)) | 从字符串中获取图像 |
| Image.frombytes(mode,size,data) | 根据像素点data创建图像 |
| Image.verify() | 对图像文件完整性进行检查,返回异常 |
Image类的常用属性
| 属性 | 描述 |
|---|---|
| Image.format | 标识图像格式或来源,如果图像不是从文件中读取,值为None |
| Image.mode | 图像的色彩模式,“L”为灰度图像,“RGB”为真彩色图像“CMYK”为出版图像 |
| Image.size | 图像宽度和高度,单位是元素(px),返回值是二元元组(tuple) |
| Image.palette | 调色板属性,返回一个ImagePalette类型 |
Image类的图像转换和保存方法
| 方法 | 描述 |
|---|---|
| Image.save(filename,format) | 将图像保存为filename文件名,format是图片格式 |
| Image.convert(mode) | 使用不同的参数,转换图像为新的模式 |
| Image.thumbnail(size) | 创建图像的缩略图,size是缩略图尺寸的二元数组 |
Image类的图像旋转和缩放方法
| 方法 | 描述 |
|---|---|
| Image.resize(size) | 按size大小调整图像,生成副本 |
| Image.rotate(angle) | 按angle角度旋转图像,生成副本 |
Image类的图像像素和通道处理方法
| 方法 | 描述 |
|---|---|
| Image.point(func) | 根据函数func的功能对每个元素进行运算,返回图像副本 |
| Image.split() | 提取RGB图像的每个颜色通道,返回图像副本 |
| Image.merge(mode,bands) | 合并通道,其中mode表示色彩,bands表示新的色彩通道 |
| Image.blend(im1,im2,alpha) | 将两幅图片im1,iim2按着如下公式插值生成新的图像:im1**(1.0-alpha)+im2* *alpha |
图像的过滤和增强
ImageFilter类的预定义过滤方法
| 方法表示 | 描述 |
|---|---|
| ImageFilter.BLUR | 图像的模糊效果 |
| .CONTOUR | 轮廓效果 |
| .DETAIIL | 细节效果 |
| .EDGE_ENHANCE | 边界加强 |
| .EDGE_ENHANCE_MORES | 阈值边界加强 |
| .EMBOSS | 浮雕 |
| .FIND_EDGES | 边界 |
| .SMOOTH | 平滑 |
| .SMOOTH_MORE | 阈值平滑 |
| .SHARPEN | 锐化 |
ImageEnhance类的图像增强和滤镜方法
| 方法 | 描述 |
|---|---|
| ImageEnhance.enhance(factor) | 对选择属性的数值增强factor倍 |
| ImageEnhance.Color(im) | 调整图像的色彩平衡 |
| ImageEnhance.Contrast(iim) | 调整图像的对比度 |
| ImageEnhance.Brightness(im) | 调整图像的亮度 |
| ImageEnhance.Sharpness(im) | 调整图像的锐度 |
实例12:图像的字符画绘制
一维数据的格式化和处理
数据组织的维度
一维数据: 由对等关系的有序或无序数据组成,采用线性方式组织,对应数学中的数组和集合等概念
二维数据,也称表格数据,由关联关系数据构成,采用表格方式组织,对应数学中的矩阵。其中,表格说明部分(第一行)可以看做是二维数据的一个维度,也可以看作是数据外的说明。
高维数据:高维数据由键值对类型的数据组成,采用对象方式组织,属于整合度更好的数据组织方式。高维数据在网络系统中十分常用,HTML、XML、JSON等都是高维数据
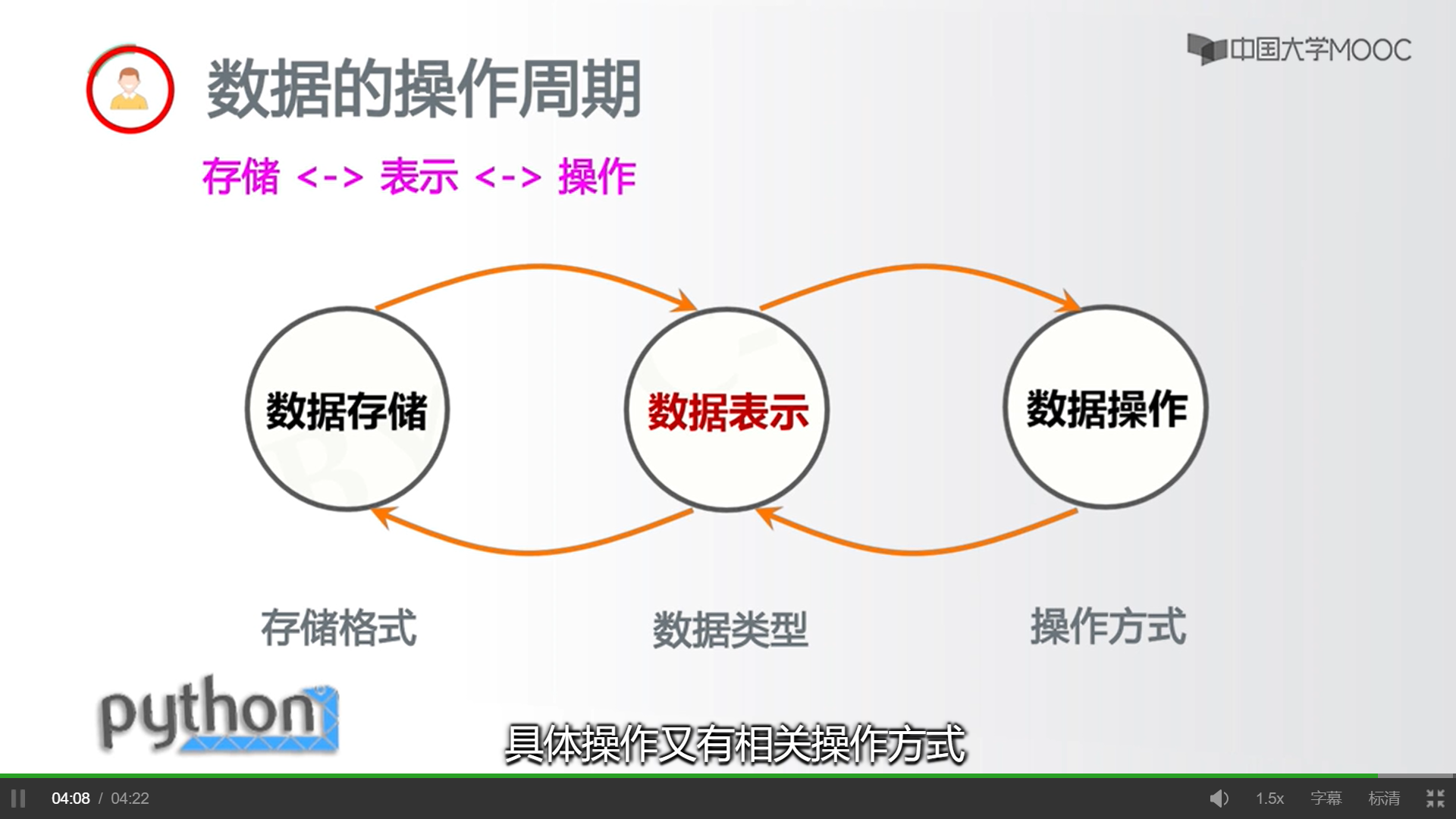
数据的操作周期
存储 —— 表示—— 操作
一维数据的表示
数据间有序:使用列表类型
数据间无序:使用集合类型
一维数据的存储
1 空格分隔
缺点 数据中不能存在空格
2 逗号分隔
3 其他字符分隔
一维数据的格式化和处理
从空格分隔的文件中读入数据
txt = open(fname).read()
ls = txt.split()
f.close()
从特殊符号分割的文件中读入数据
txt = open(fname).read()
ls = txt.split("$")
f.close()
一维数据的写入方式
采用空格分隔方式将数据写入文件
ls = ['中国','美国','日本']
f = open(fname,'w')
二维数据的格式化和处理
二维数据的表示
二维数据,也称表格数据,由关联关系数据构成,采用表格方式组织,对应数学中的矩阵。其中,表格说明部分(第一行)可以看做是二维数据的一个维度,也可以看作是数据外的说明。
使用列表类型
[[1,2,3,4], [2,3,4,5]]
使用两层for循环遍历每个元素
外层列表中每个元素对应一行,也可以对应一列
CSV格式存储格式
国际上通用的一二维数据存储格式,一般.csv扩展名。每行一个一维数据,采用逗号分隔,无空行。Excel和一般编辑软件都可以读入或另存为csv文件
如果某个元素缺失,逗号仍要保留。二维数据的表头可以作为数据存储,也可以另行存储
数据中有逗号的处理:
二维数据的存储
二维数据按行存或按列存都可以,具体由程序决定,一般索引习惯:ls[owcolumn先行后列,根据一般习惯,外层列表每一个元素是一行,按行存储
二维数据的处理
从csv格式的文件中读入数据
fo = open(fname)
ls = []
for line in fo:
line = line.replace("\n","") #替换换行符为空格
ls .append(line.split(","))
fo.close()
print(ls)
将数据写入CSV格式的文件
ls = [ [] , [], [] ] #二维列表
f = open(fname,'w')
for item in ls:
f.write(','.join(item)+'\n')
f.close()
逐行处理CSV格式数据
ls =[[1,2], [3,4], [5,6]] #二维列表
for row in ls:
for column in row :
print(column)
模块 wordcloud库的使用
wordcloud 库把词云作为一个WordCloud对象.
wordcloud.WordCloud代表一个文本对应的词云
可以根据文本中词语出现的频率等参数绘制词云。绘制词云的形状。尺寸和颜色都可以设定
wordcloud库的常规使用
w = worldcloud.WorldCloud
以WorldCloud对象为基础,配置参数,加载文本,输出文件
| 方法 | 描述 |
|---|---|
| w.generate(txt) | 向WorldCloud对象w中加载文本txt |
| w.to_file(filename) | 将词云输出为图像文件,.png或.jpg格式 |
步骤
-
配置对象参数
配置对象参数
w = worldcloud.WorldCloud(<参数>)
参数 描述 width 指定词云对象生成图片的宽度,默认400像素 height 指定词云对象生成图片高度,默认200像素 min_font_size 指定词云中字体的最小字号,默认4号 max_font_size 指定词云中字体的最大字号,根据高度自动调节 font_path 指定字体文件的路径,默认None max_words 指定词云显示的最大单词数量 stop_words 指定词云的排除列表,即不显示的单词列表 mask 指定词云形状,默认为长方形,需要引用imread()函数 backgroud_color 指定词云背景颜色 -
加载词云文本
-
输出词云文件
、
import wordcloud
c= wordcloud.WordCloud()
w.generate("wordcloud by Python")
c.to_file("Pywordcloud.png")
做了什么
- 分隔:以空格分隔单词
- 统计:单词出现次数并过滤
- 字体:根据统计配置字号
- 布局:颜色环境尺寸
import wordcloud
txt = "life short, you need python"
w = worldcloud.WorldCloud(background_color="white")
w.generate(txt)
w.to_file("pywcloud.png")
对中文显示词云,首先需要将文本分组
import jieba
import worldcloud
txt="阿宾的高中成绩并不理想,但是必竟也给他考上了台北附近一所私立专校。开学之前,他考虑到每天通车恐怕太过于辛苦,于是就在学校旁边租了间学生房,只在周末假日,才回家看看妈妈。他所租的是专门分租给学生的一层楼,在旧公寓六楼顶木板加盖的小违建,一共有六个房间,共享一套卫浴设备和一小间厨房,外头屋顶还留有一小片阳台可以晒衣服。阿宾搬进去的时候,还要五六天才开学,也不知道其它房间住的是什么人。那小巧浑圆的线条,紧绷的白色三角裤,阿宾哪里还在按摩,他只是爱不释手的来回抚摸。摸着摸着,手指不安的从臀腿之间去轻触过去那神秘之处,只觉得肥肥的、嫩嫩的、热热的、湿湿的。手指头在丝布外按柔了一会儿之后,他大胆扳动胡太太那弓起的左腿,将她翻了个身,这时候胡太太上身虽然衣杉整齐,腰腹以下却已是完全不设防。"
w = worldcloud.WorldCloud(width=1000,font_path="msyh.ttc",height=700)
w.generate(" ".join(jieba.lcut(txt))) #jieba.lcut()函数将txt分割为一个列表,接着用join函数将列表中的元素用空格组织起来
w.to_file("pyworld.png")
实例 12 政府工作报告词云
基本思路
- 读取文件,分词整理
- 设置并输出词云
- 观察结果,优化迭代
import jieba
import wordcloud
f = open("B.txt","r",encoding="utf-8")
t= f.read()
f.close()
ls = jieba.lcut(t)
txt = " ".join(ls)
w = wordcloud.WorldCloud( font_path = "msyh.ttc",width=1000,height=700,backgroud_color="white")
w.generate(txt)
w.to_file("grwordcloud.png")
五角星形状的词云
需要一个空白的五角星形状的图片,使用
#GovRptWordCloudv2.py
import jieba
import wordcloud
from scipy.misc import imread
mask = imread("chinamap.jpg")
excludes = { }
f = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")
t = f.read()
f.close()
ls = jieba.lcut(t)
txt = " ".join(ls)
w = wordcloud.WordCloud(\
width = 1000, height = 700,\
background_color = "white",
font_path = "msyh.ttc", mask = mask
)
w.generate(txt)
w.to_file("grwordcloudm.png")
模块 Json库的使用
import json
json库包含两个过程:编码(encoding)和解码(decoding)。编码是将Python数据类型变换为JSON格式的过程,解码是从JSON格式中解析数据对应到Python数据类型的过程.本质上,编码和解码是数据类型序列化和反序列化的过程。
json库的操作函数
| 函数 | 描述 |
|---|---|
| json.dumps(obj,sort_keys=False,indent=None) | 将Python的数据类型转换为JSON格式,编码过程 |
| json.loads(string) | 将JSON格式字符串转换为Python的数据类型,解码过程 |
| json.dump(obj,fp,sort_keys=False,indent=None) | 与dumps()功能一致,输出到文件fp |
| json.load(fp) | 与loads()功能一致,从文件fp读入 |