集合的引入
概念:对象的容器,定义了对多个对象常用的操作方法。可以实现数组的功能
为什么使用集合而不是数组?
-
集合和数组比较
都可以存储多个对象,对外作为一个整体存在
数组可以存储基本类型和引用类型,集合只能存储引用类型 -
数组的缺点
- 长度必须在初始化时指定,且固定不变
- 数组采用连续存储空间,增删操作效率低下
- 数组无法直接保存映射关系(通过关键字与对象产生关联)
- 数组缺乏封装性,操作繁琐
集合的架构
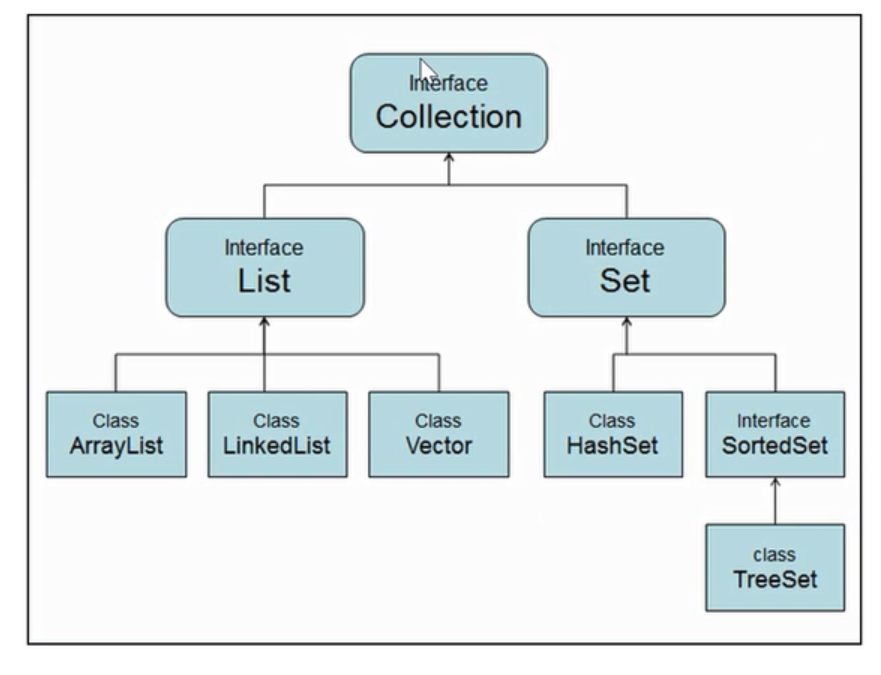
| 集合类型 | 是否唯一 | 是否有序 |
|---|---|---|
| Collection | 否 | 否 |
| List | 否 | 是 |
| Set | 是 | 否 |
| Map | Key唯一,Value不唯一 | 否 |
List
| List类型 | 优点 | 缺点 |
|---|---|---|
| ArrayList | 遍历元素和下标随机访问元素效率高 | 1.增删元素需要移动大量元素,效率低 2.按照内容访问元素效率低 |
| LinkedList(双向链表) | 增删元素效率较高 | 遍历和随机访问元素效率低 |
package com.kuang.containers.List;
import java.util.ArrayList;
import java.util.Iterator;
/**
* 集合中只能放对象,不能放基本数据类型(可以通过包装类存储--自动装箱)
* 数组中可以存储基本数据类型
* 下面代码的确定:
* 1.繁琐:取出的元素是Object类型,需要强转
* 2.不安全:可以添加不同数据类型
* 解决办法:使用泛型
*/
public class TestArrayList {
public static void main(String[] args) {
//创建ArrayList
//推荐的书写方式:List<Integer> list = new ArrayList<Integer>();
ArrayList<Integer> list = new ArrayList<Integer>();//初始分配多少空间?
ArrayList list1 = new ArrayList();
list1.add(11);
list1.add(22);
ArrayList list2 = list1;
//添加元素
list.add(66);//自动装箱,不指定索引位置,默认从末尾添加
list.add(99);
list.add(0,100);//指定插入的位置,底层数组发生大量元素移动操作
list.addAll(list1);//一次性添加多个元素
//list.addAll(0,list1);
//修改元素
list.set(0,1);//将下标为0的元素值改为1
//删除元素
//删除元素
list.remove(0);//删除下标为0的元素
list.remove(new Integer(22));//当元素有整数,想按照元素值来删除,需要用Integer来跟下标区分
list.removeAll(list1);//删除与list1相同的元素
list2.clear();//清空整个list
//访问元素
System.out.println(list.size());//元素个数
System.out.println(list.get(0));//通过索引访问元素
//遍历元素
//方法一:for循环
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
//方法二:for-each循环
for (Object elem:list) {
System.out.println(elem);
}
//方法三:Iterator迭代器
Iterator it = list.iterator();//创建一个迭代器
while (it.hasNext()){
System.out.println(it.next());
}
//其他方法
list.indexOf(11);//从左往右找,返回对应值的元素的下标
list.lastIndexOf(11);//从右往左找,返回对应值的元素的下标
list.contains(22);//判断是否含有某个元素,返回布尔值
list.containsAll(list1);//判断list中是否含有list1中的全部元素
}
}
ArrayList和LinkedList的比较
/*
相同点:
1.调用的方法大同小异
2.操作的结果一样
不同点:
1.底层结构不同:
ArrayList: 连续的空间 数组
LinkedList: 不连续的空间 双向链表
2.像中间插入元素,list.add(3,5)
ArrayList产生大量元素后移,效率低下;
LinkedList只需创建新的节点,并修改前后两个指针,加入到第三个位置,效率较高
如何选择?
1.随机访问频率高,使用ArrayList
2.增删操作多,选择LinkedList
*/
Set
特点
无序,唯一
HashSet
- 采用hashtable哈希表存储结构(基于计算来查询)
- 优点:增删、查询速度快
- 缺点:无序
LinkedHashSet
- 采用哈希表存储结构,同时使用链表维护次序
- 有序(添加顺序)
TreeSet
- 采用红黑树(二叉树&&二叉排序树&&二叉平衡树)的存储结构
- 优点:有序(大小顺序),查询速度比List要快(按照内容查询)
- 缺点:查询速度没有HashSet快
红黑树如何保证有序?
- 存储有序(二叉排序树规则)
- 输出有序(中序遍历)
- 中序遍历:左子树--->根--->右子树
- 前序遍历:根--->左子树--->右子树
- 后序遍历:左子树--->右子树--->根
二叉平衡树应对极端的存储顺序的调整规则?
对Set的遍历
- for-each循环
- Iterator
- 不能使用for循环,因为Set没有提供get(i)方法
- Set相比Collection没有增加什么方法,但List则新增了许多与index相关的方法
for (String course:set
) {
System.out.println(course);
}
Iterator<String> iterator = set.iterator();
for (int i = 0; i < set.size(); i++) {
System.out.println(iterator.next());
}
Set存储自定义类
-
使用HashSet/LinkedHashSet存储自定义类时,为了保持唯一性,必须重写hashcode()和equals()方法
-
equals()只能比较是否相等,不能比较大小,比较大小用比较器
-
使用TreeSet存储自定义类时,自定义类必须实现Comparable接口或Comparator接口
-
TreeSet的底层调用的是TreeMap,都是有序的,需要比较器来进行比较
-
Comparator:外部比较器(优先调用外部比较器,若没有指定外部比较器,则调用内部比较器),Comparable:内部比较器(一般选最常用的比较方式)
某个类的内部比较器只有一种比较规则,一般选取最常用的比较方式;想要实现多种规则,可使用外部比较器
import com.kuang.containers.Entity.StuAgeDescComparator;
import com.kuang.containers.Entity.Student;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
public class TestSet2 {
public static void main(String[] args) {
//创建比较器对象
//Comparator comparator = new StuAgeDescComparator();
//创建set对象,指定比较器
Set<Student> set = new TreeSet<Student>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return Double.compare(o1.getScore(),o2.getScore());
}
}.reversed());
//创建学生对象
Student stu1 = new Student(1,"张三",16,92);
Student stu2 = new Student(2,"李四",17,95.5);
Student stu3 = new Student(3,"王五",15,93);
Student stu4 = new Student(1,"张三",16,92);
//存储学生对象
set.add(stu1);
set.add(stu2);
set.add(stu3);
set.add(stu4);
//输出存储的结果
System.out.println(set.size());
for (Student stu:set
) {
System.out.println(stu);
}
}
}
哈希表
哈希表(hashtable,也称散列表)的结构和特点
-
特点:增删操作速度快
-
结构:有多种,最流行和常见的是顺序表+链表的形式(主结构是顺序表,顺序表的每个节点再引出一个链表)

哈希表的存储(查询类似)
- 调用hashcode()计算哈希码(hashcode()返回整数结果;整数的哈希码是本身)
- 根据哈希码,通过某种算法计算存储位置(需要使用合理的策略减少存储冲突)
- 存储到指定位置(调用equals()方法检测元素是否冲突)
哈希码的计算
import com.kuang.containers.Entity.Student;
public class testSet3 {
public static void main(String[] args) {
Object obj;//hashCode()是Object类的public方法,返回值int类型
Integer i;//整数的哈希码是本身
/*
public static int hashCode(int value){
return value;
}
*/
Double d;//算法复杂,目的是让不同的double产生不同的哈希码,减少存储冲突
/*
public static int hashCode(double value){
long bits = doubleToLongBits(value);
return (int)(bits ^ (bits >>> 32));
}
*/
String s;//字符串底层是字符数组,对字符编码进行循环计算得到哈希码,如”ab“:(0*31+97)*31+98
Student student;//对于自定义类,可以先根据成员变量各自的类型计算哈希值,再通过某种方式对各个哈希值进行计算得到最终结果
}
}
如何减少冲突?
- 哈希表长度/存储元素总数=装填因子,取经验值0.5左右时,hash性能最优;
- 动态扩容:当事先不知到要存储多少个元素时,需要动态维护哈希表长度,取装填因子=表中已存记录数/表长度为0.75时,进行扩容;
- 哈希函数的选择:
- 直接定址法
- 平方取中法
- 折叠法
- 除留取余法
- 其他
如何处理冲突?
- 链地址法
- 开放地址法
- 再散列法
- 建立公共溢出区
java中HashSet、LinkedHashSet、HashMap、LinkedHashMap、HashTable底层都是使用的哈希表。
为了减少查询比较次数,JDK1.8后,哈希表的底层结构发生了变化:如果链表的长度大于等于8,会转化成红黑树结构。
Map
map存储字符串键值对
import java.util.*;
/**
*Map没有迭代器,不能直接使用迭代器进行遍历,可以先变成set,对set进行迭代遍历
*Entry:是Map接口的内部接口
*
*/
public class TestMap1 {
public static void main(String[] args) {
//创建map对象
//Map<String,String> map = new HashMap<String,String>();//无序,key唯一,value不唯一
//Map<String,String> map = new LinkedHashMap<String, String>();//添加顺序
Map<String,String> map = new TreeMap<String, String>();//按元素的默认排序,此处为String
//用map存储键值对
map.put("CN","China");
map.put("US","America");
map.put("UK","United Kingdom");
map.put("UK","英国");//key重复时,最后添加的元素value会覆盖前面添加的元素value
map.put("en","英国");//value可以重复
//获取map相关属性
System.out.println(map.size());
System.out.println(map);
System.out.println(map.get("en"));//根据key获取value
System.out.println(map.values());//[China, 英国, America, 英国],获取值组成的set
System.out.println(map.keySet());//[CN, UK, US, en],获取key组成的set
System.out.println(map.entrySet());//[CN=China, UK=英国, US=America, en=英国],获取key=value组成的set
//遍历map
//方法一:通过遍历key组成的集合,使用map.get()方法获取每个value
Set<String> set1 = map.keySet();
for (String k:set1
) {
System.out.println(k+"========"+map.get(k));
}
//方法二:遍历entry组成的集合
Set<Map.Entry<String,String>> set2 = map.entrySet();
Iterator<Map.Entry<String,String>> it = set2.iterator();
while (it.hasNext()){
Map.Entry<String,String> entry = it.next();
System.out.println(entry.getKey()+"========"+entry.getValue());
}
}
}
map存储自定义类键值对
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class TestMap2 {
public static void main(String[] args) {
//创建student实例
Student stu1 = new Student(1,"张三",16,90);
Student stu2 = new Student(2,"李四",11,88);
Student stu3 = new Student(3,"王五",17,90);
Student stu4 = new Student(4,"赵六",10,61);
Student stu5 = new Student(1,"张三",22,100);
//创建map对象
Map<Integer,Student> map = new HashMap<Integer,Student>();
//添加元素
map.put(stu1.getSno(),stu1);
map.put(stu2.getSno(),stu2);
map.put(stu3.getSno(),stu3);
map.put(stu4.getSno(),stu4);
map.put(stu5.getSno(),stu5);
//输出结果
System.out.println(map.size());//4,key必须是唯一
//遍历
Set<Map.Entry<Integer,Student>> set = map.entrySet();
Iterator<Map.Entry<Integer,Student>> it = set.iterator();
while (it.hasNext()){
Map.Entry<Integer,Student> entry = it.next();
System.out.println(entry.getValue());
}
//其他方法
map.remove(1);//删除key=1的键值对
//map.clear();//清空map
map.replace(4,stu2);//将key=1的元素替换为stu2
map.get(3);//查询key=3的value值
map.entrySet();//获取所有key-value键值对组成的set
map.containsKey(1);//判断是否包含key
map.containsValue(stu1);//判断是否包含value
}
}