格式化输出函数 fmt.Printf
编程开发过程中,经常需要通过输出各种信息来辅助调试代码。一般来说,我们建议通过 fmt 包中的 Println 和 Print 函数,也有使用内置函数 println 和 print 来输出打印信息。
这些函数都有一定的局限性,即在输出格式上只能按照系统默认格式来输出各个参数,无法灵活地组织输出信息的格式化:
package main
import (
"fmt"
)
func main() {
a := 1 / 3
println(a)
print(a)
fmt.Println(a)
fmt.Print()
}

注意,如果我们直接让 a := 1/3,得到的结果是 0,因为此时 ":=" 操作符让 Go 语言编译器自动根据符号右侧的表达式来判断变量 a 的数据类型,因为这两个数字都可以解释为整数,所以编译器会优先认为这是两个整数相除,Go 语言中整数相除的结果也是整数,经过取整之后结果以整数 0 存入整型变量 a。
如果需要使结果为浮点数,应该至少将表达式中的一个数字写作浮点数的表达式,因此我们使用了 a := 1.0 / 3 这种貌似没有必要但是有实际意义的写法。
这是科学记数法表示的 1 除以 3 的小数结果。
package main
import (
"fmt"
)
func main() {
a := 1.0 / 3
println(a)
print(a)
fmt.Println(a)
fmt.Print()
}
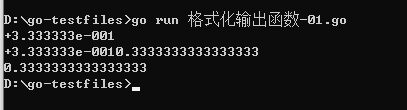
这是用一定的小数位来表达这个无限循环小数的结果。假设,如果我们希望输出仅保留小数点后面两位(这在实际生活中非常常见),这两个函数都将难以实现。
另外,在输出多个字符串参数时,println 和 fmt.Println 会在各个参数之间加上一个空格字符,这也是无法噶边。
因此可以看出,这几个输出函数在输出信息的格式上都不太灵活。如果需要更加灵活地组织输出数据的格式,我们在介绍 fmt 包中的另一个非常灵活的函数 Printf,可以满足这种情况下的需要。虽然 fmt.Printf 函数并非 Go 语言的内置函数,而是标准库中的一个函数,但由于其重要性,在后续的实例代码中会频繁用到,所以这里提一提。
fmt.Printf 函数与 C 语言中的 printf 函数非常类似,但是 Go 语言中做了一些非常好的改进。fmt.Printf 函数主要通过增加一个表示格式信息的参数来增加信息的灵活性,格式信息本身也是一个字符串,用来指引该函数如何结合其他参数组织一个最终输出的字符串。
package main
import (
"fmt"
)
func main() {
var a int
a = 8
fmt.Printf("a=%d
", a)
}

这里的 a 是一个 int 类型的整数变量,fmt.Printf 函数的第一个参数是一个字符串 "a=%d",这个字符串参数叫作 fmt.Printf 函数的格式参数或格式字符串,必须位于函数参数中的第一个位置。
格式参数中的其他内容都会按原样输出,唯有百分号 "%" 开头的子字符串有特殊的含义,起到占位的作用,并会指示出后面的参数按什么格式替代进来,我们一般称之为 "格式化动作符" 或简称 "格式化符"。
在格式字符串结尾增加 " " 表示换行,这种以反斜杠 "" 开头后面带有一个字符的表达形式叫作 "转义字符",反斜杠表示后面的字符并不代表其本身,而是反斜杠一起表达另一个字符。
1、整数格式化符%d
有时候为了输出多行数字时右对齐,需要在输出的整数前补充一定数量的空格,可以在 %d 这两个字符中间增加一个表示宽度的数字:
package main
import (
"fmt"
)
func main() {
fmt.Printf("1,2,4,5,6,7,8,9,10
")
fmt.Printf("%9d
", 18)
fmt.Printf("%09d
", 18)
fmt.Printf("%-9d
", 39)
fmt.Printf("%-09d
", 39)
}
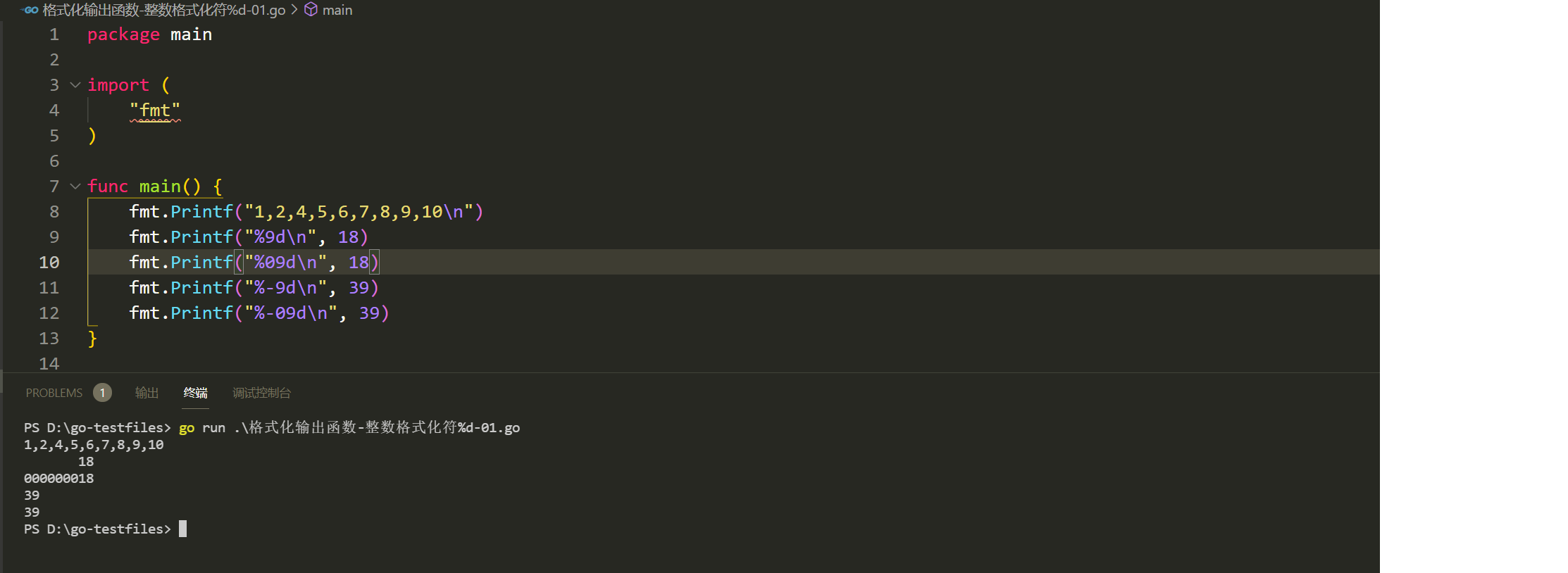
- 第 1 行作为参照物决定第 2 行输出时补充几个空格字符。
- 第 2 行中格式化符 "%9d" 表示要保证输出的整数有 9 位,如果不到 9 位则在左侧补上空格字符,直至一共有 9 个字符为止,左侧的确是空了 7 个字符的位置。
- 如果想要左对齐,可以在宽度标志符前增加一个减号字符 "-"。
- 左侧可以用数字 "0" 来补齐空位,只需要在宽度标识符前加一个数字 "0" 即可。
- 右侧补数字 "0",是无效的。因为从数学意义上来说,在整数右侧补0会使数值发生变化。
2、十六进制格式化符%x和%X
如果需要用十六进制表示整数,可以使用 %x 或 %X 格式化符。这两者都是将整数按十六进制形式输出,唯一区别的是 %x 输出的是小写字符而 %X 输出的是大写字符。

%x 和 %X 也支持宽度标识符和左右对齐:

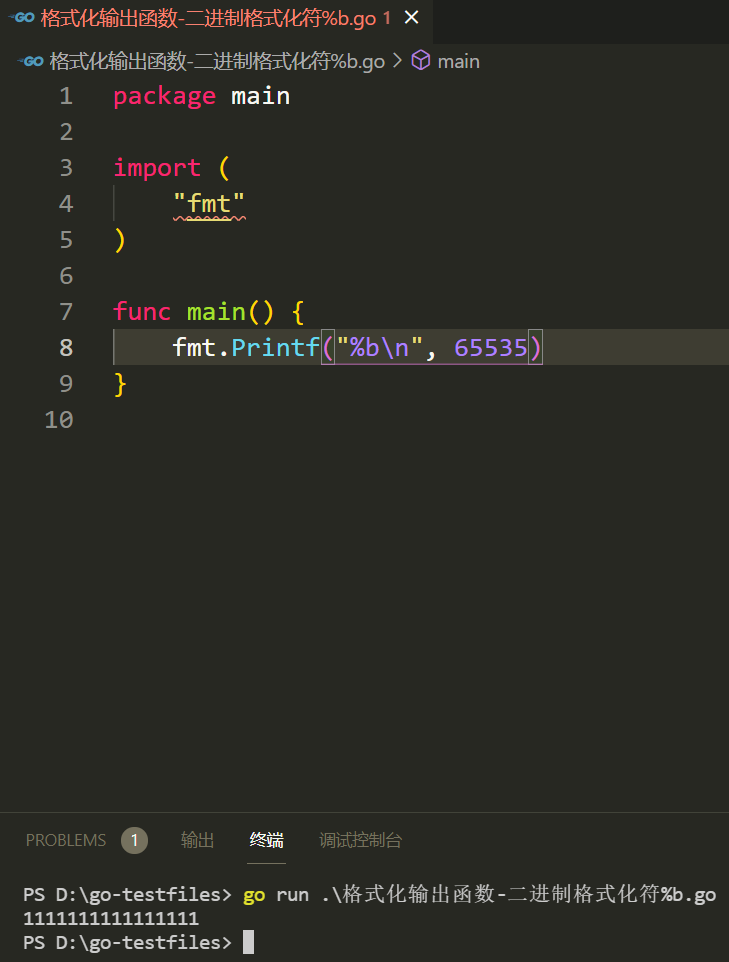
3、二进制格式化符%b
类似于十六进制格式化符 %x 和 %X,%b 可以以二进制的形式将整数表达出来:
4、浮点数格式化符%f
如果是浮点数,一般会使用格式化符 %f 来控制输出:
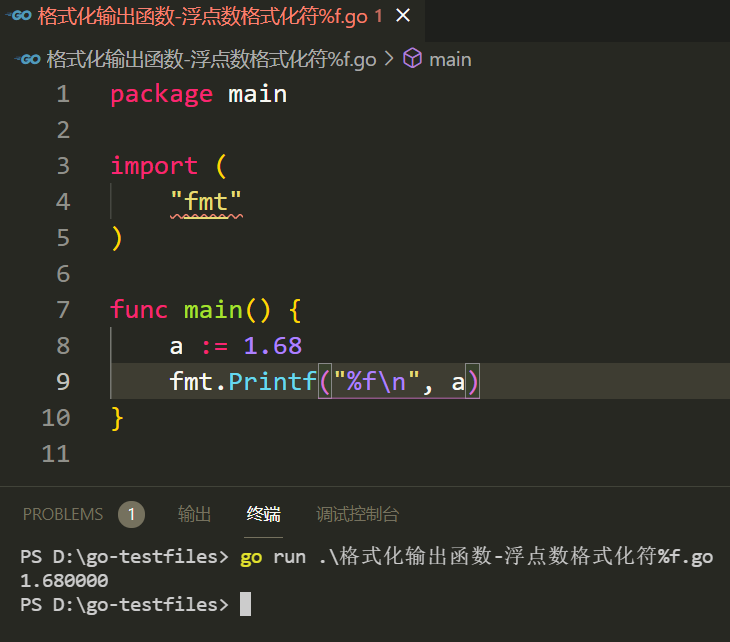
可以看出,仅使用格式化符 %f 本身虽然可以输出浮点数,但对数字显示的格式还是没有精细的控制。
如果要精细的控制,可以使用宽度标识符和对齐标识符,程序代码如下:
package main
import (
"fmt"
)
func main() {
a := 1.23456789
fmt.Printf("%9.2f
", a) // %9.2f,要求整体输出9个字符,其中,小数点后输出2个字符
fmt.Printf("%9.6f
", a) // %9.6f,要求整体输出9个字符,其中,小数点后输出6个字符
fmt.Printf("%09.2f
", a) // %09.2f,要求整体输出9个字符,不足补0,其中,小数点后输出2个字符,超过的部分四舍五入处理后输出
b := 8.888888888
fmt.Printf("%09.2f
", b) // %09.2f,要求整体输出9个字符,不足补0,其中,小数点后输出2个字符,超过的部分四舍五入处理后输出
fmt.Printf("%-9.2f
", a) // %-9.2f,要求整体输出9个字符,左对齐,其中,小数点后输出2个字符
fmt.Printf("%9.9f
", a) // %9.9f,要求整体输出9个字符,其中,小数点后输出9个字符
fmt.Printf("%9.09f
", a) // %9.9f,要求整体输出9个字符,其中,小数点后输出9个字符
}
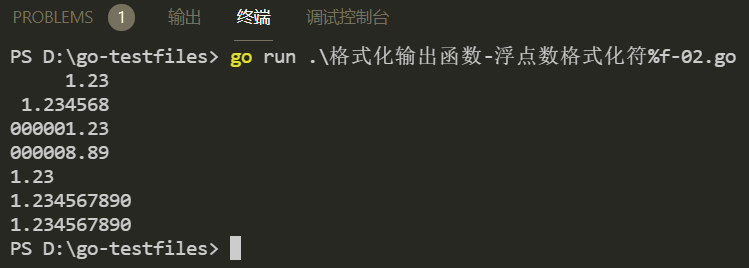
与整数的宽度标识符是一个整数数字不同,浮点数的宽度标识符一般是一个小数,小数点前的部分表示要求输出的整体宽度是几个字符,小数点后的部分表示要求输出的小数点后面的位数。
整体字符位数可以省略,比如格式化符 " 0.2f ",可以输出小数点后 2 位,总数根据需要而定的浮点数。
5、其他浮点数格式化符
还有一些并不常用的浮点数格式化符,以及一些用于表示复数的格式化符。
%b 也可以用于表示任意数字(包括小数)的二进制形式,实际上表示的是该数字对应 2 的多少次方乘以一个数字,类似科学计数法中将 e 的值从 10 转换成 2:
package main
import (
"fmt"
)
func main() {
fmt.Printf("%b
", 2.0)
fmt.Printf("%b
", 1.0)
fmt.Printf("%b
", 0.1)
}

%e 和 %E 则代表用科学计数法表示一个浮点数,两者的区别在于结果中的字母 e 是大写还是小写:
package main
import (
"fmt"
)
func main() {
fmt.Printf("%e
", 2.0/3)
fmt.Printf("%E
", 2.0/3)
fmt.Printf("%e
", 8.0)
}

%g 和 %G 则是根据浮点数后小数点的位数自动决定是否用科学计数法表示,如果位数少就用 %f 的方式表示,否则根据字母 g 的大小写分别对应 %e 和 %E 的方式显示,整体原则是尽量减少数字中无用的 0 来简洁输出的位数
package main
import (
"fmt"
)
func main() {
fmt.Printf("%g
", 3.0/700000)
fmt.Printf("%G
", 2.0/3)
fmt.Printf("%G
", 8.0)
}

6、布尔类型的格式符%t
布尔类型的数据或变量可以用格式化符 %t 来控制输出,输出信息是 true 或 false 两个字符串。
package main
import (
"fmt"
)
func main() {
a := true
b := false
fmt.Printf("a: %t
b: %t
a==b: %t
", a, b, a == b)
}

7、Unicode 码相关格式化符 %c 、%q 和 %U
格式化符 %c 和 %q 的作用是将后面的整数参数作为一个字符的编码来看待并输出该编码对应的 Unicode 字符,两者的区别在于 %q 会将输出的字符用单引号括起来。而格式化符 %U 与这两者正好想相反,是将后面作为参数的字符(注意需用英文单引号 " ' " 括起来)的 Unicode 编码(确切地说是 UTF-8 编码)输出。
package main
import (
"fmt"
)
func main() {
fmt.Printf("%c
", 0x61)
fmt.Printf("%q
", 0x61)
fmt.Printf("%U
", 'a')
}

ASCII码中小写字母 a 是 97,即十六进制的 61,在 Go 语言中表示 0x61。
Go 语言中使用 UTF-8 编码,属于 Unicode 编码中使用较广泛的一种,且 UTF-8 编码是涵盖 ASCII 码的,所以第1个和第2个输出 a 和 'a' 是正确的。
第 3 条语句是完全反向的操作,输出的结果也是正确的,"U+0061" 中的数字也是十六进制的数字,这是 Unicode 编码通常的表达形式。
输出汉字的 UTF-8 编码:
package main
import (
"fmt"
)
func main() {
fmt.Printf("%U
", '我')
}

8、字符串格式化符%s
package main
import (
"fmt"
)
func main() {
fmt.Printf("%s is aaa", "aaa")
}

9、指针格式化符%p
格式化符 %p 用于输出指针的值,由于 Go 语言中为了代码安全尽量弱化了指针的存在,因此这个格式化符并不常用。
package main
import (
"fmt"
)
func main() {
a := "abc"
b := []int{1, 2, 3}
p := &b
fmt.Printf("a的地址: %p,b的地址: %p
", &a, p)
}

10、万能格式化符%v
%v 这个是格式化符是 Go 语言中的一个比较有用的改进。使用 %v 格式化符,可以对包括符合类型在内的绝大多数数据类型按照默认格式输出。这样可以避免我们编程时再去关注输出数据的具体类型并按其类型确定格式化符。
%v 可以理解:对整数而言等同于 %d,对浮点数而言等同于 %g,对布尔类型数据而言等同于 %t,对字符串而言等同于 %s,对指针而言等同于 %p。
%#v 字符可以输出数据在 Go 语言中的表达形式,主要用于编程中调试程序。