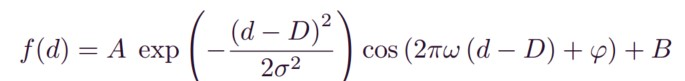论文来源:IEEE TRANSACTIONS ON INDUSTRIAL ELECTRONICS
- 2016年的文章,SCI1区,提出了两阶段的算法。第一个阶段使用Sparse filtering,无监督的方式提取出特征。第二个阶段使用softmax回归进行分类。可以实现更少的数据,但更高的准确率。对Sparse filtering的weight进行了可视化,与Gabor滤波器进行拟合,发现很相近。
Sparse filtering 和Softmax regression
论文的核心就是这两步的算法,分两个步骤讲解。
Sparse filtering
- Sparse filtering的思想来自于NIPS2011吴恩达组的文章,是一种无监督的提取特征的算法。与之相比较的无监督算法还有ICA,Sparse Coding,Sparse Autoencoder。具体见另一篇总结sparse filtering的文章。
- Sparse filtering可以实现非线性,增加一个激活函数。本文使用了下图的激活函数得到了特征。
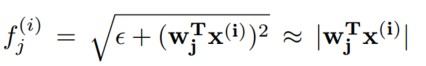
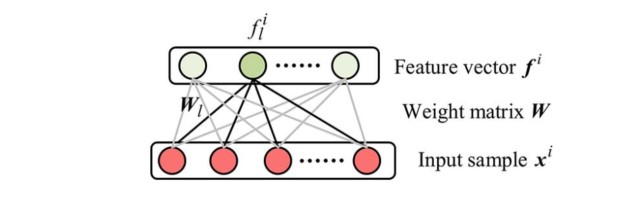
Softmax Regression
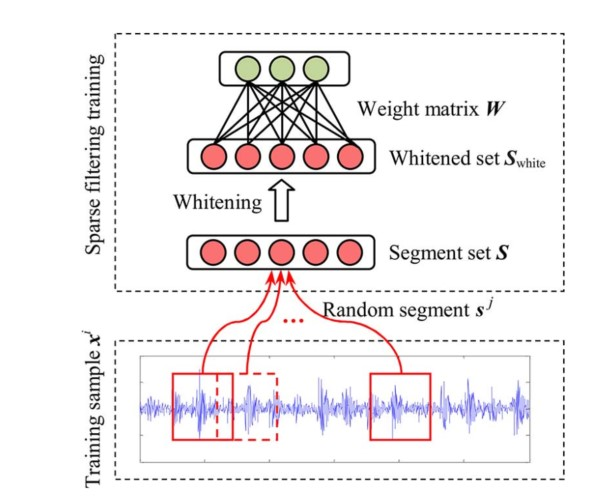
结构图如下,这里看出原文是对输入的样本再一次进行了切分,对同一个example的输出结果进行的求和平均,而不是concatenate,它们的实验证明求和平均效果更好。
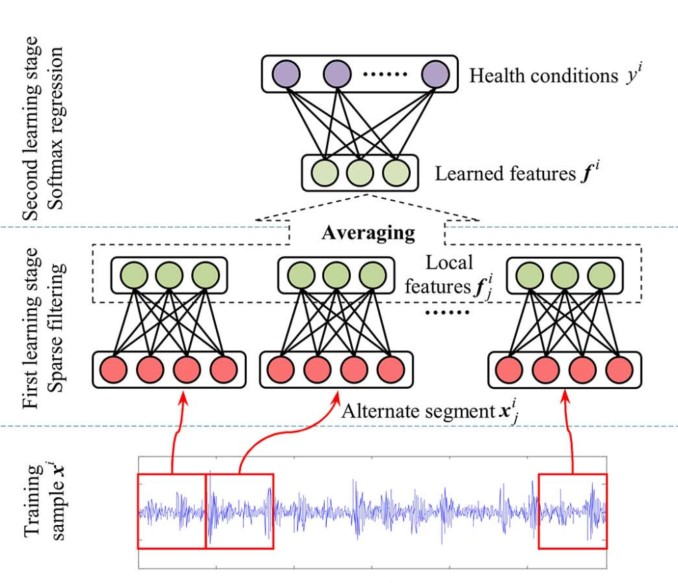

下图是目标函数,这里没有使用交叉熵。
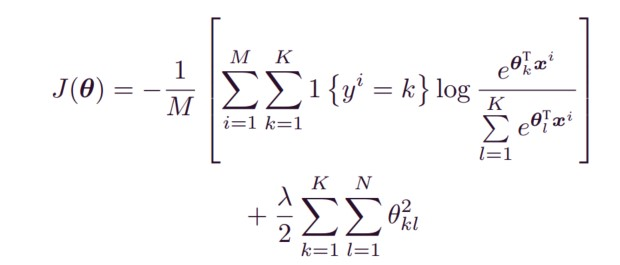
其次,这里对随机segment的样本进行了whitening的操作。我参考了矩阵论(张贤达)里面的公式。
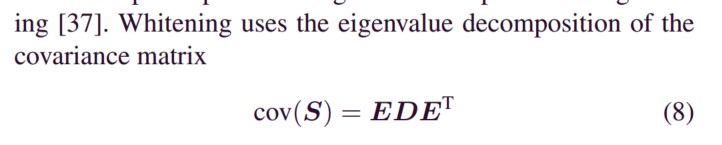

进行了白化之后的向量,协方差矩阵为单位矩阵,可以加速收敛的速度。实验也证明了白化的作用。
可视化
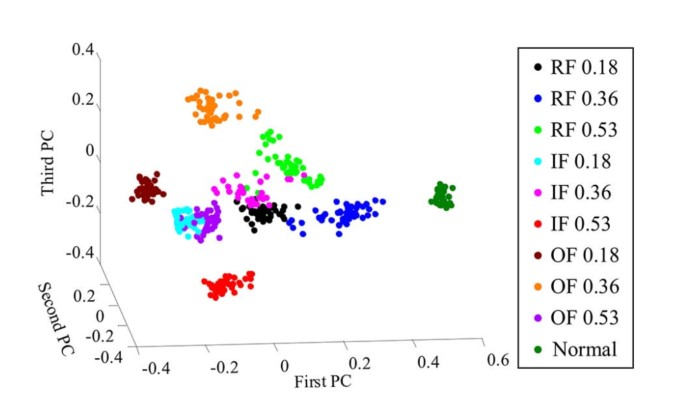
PCA降维
对学习到的特征PCA降维后的结果
对Sparse filtering的权重矩阵可视化
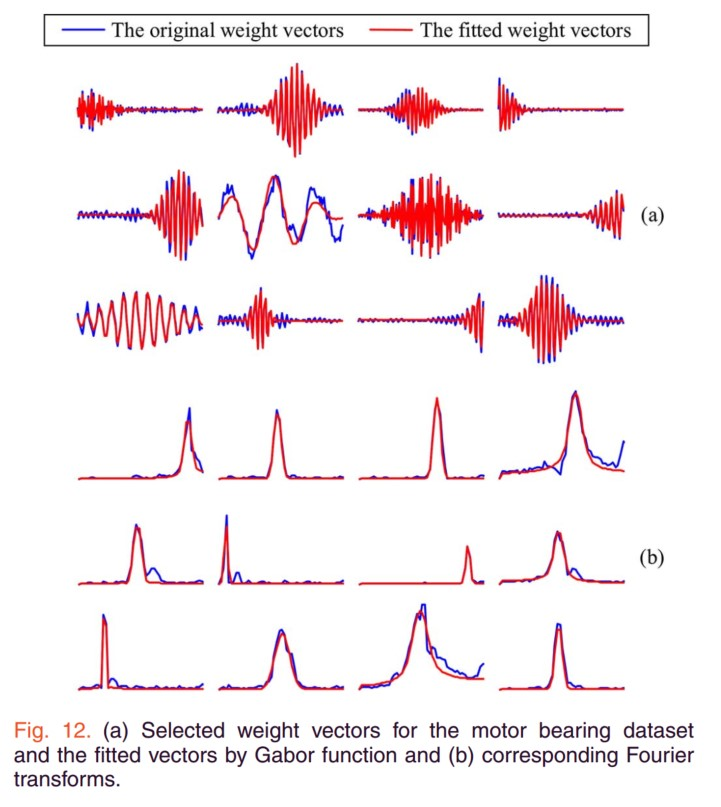
直观理解,W矩阵和X输入相乘,其实是W的每个行向量和X向量计算相似度(点积)。对行向量可视化。然后用面的Gabor滤波器去拟合,发现两者很接近。下面三行是傅里叶变换之后的结果。Gabor滤波器的公式引用自其它文献。具体更多的理解看傅里叶变换的那篇文章,收集了一些不错的解答。拟合的结果说明了一定的物理意义。Gabor滤波器接近于最优的特征提取滤波器。